在 TensorFlow 之中进行迁移学习
在之前的学习之中,我们都是从定义模型开始,逐步的获取数据并且对数据进行处理,最终训练模型以达到一个良好的效果。这些任务都是从零开始训练的例子,那么我们能不能使用别人已经训练好的模型来帮助我们来进行相似的工作呢?答案是肯定的,这就是我们这节课要学习到的 “迁移学习”。
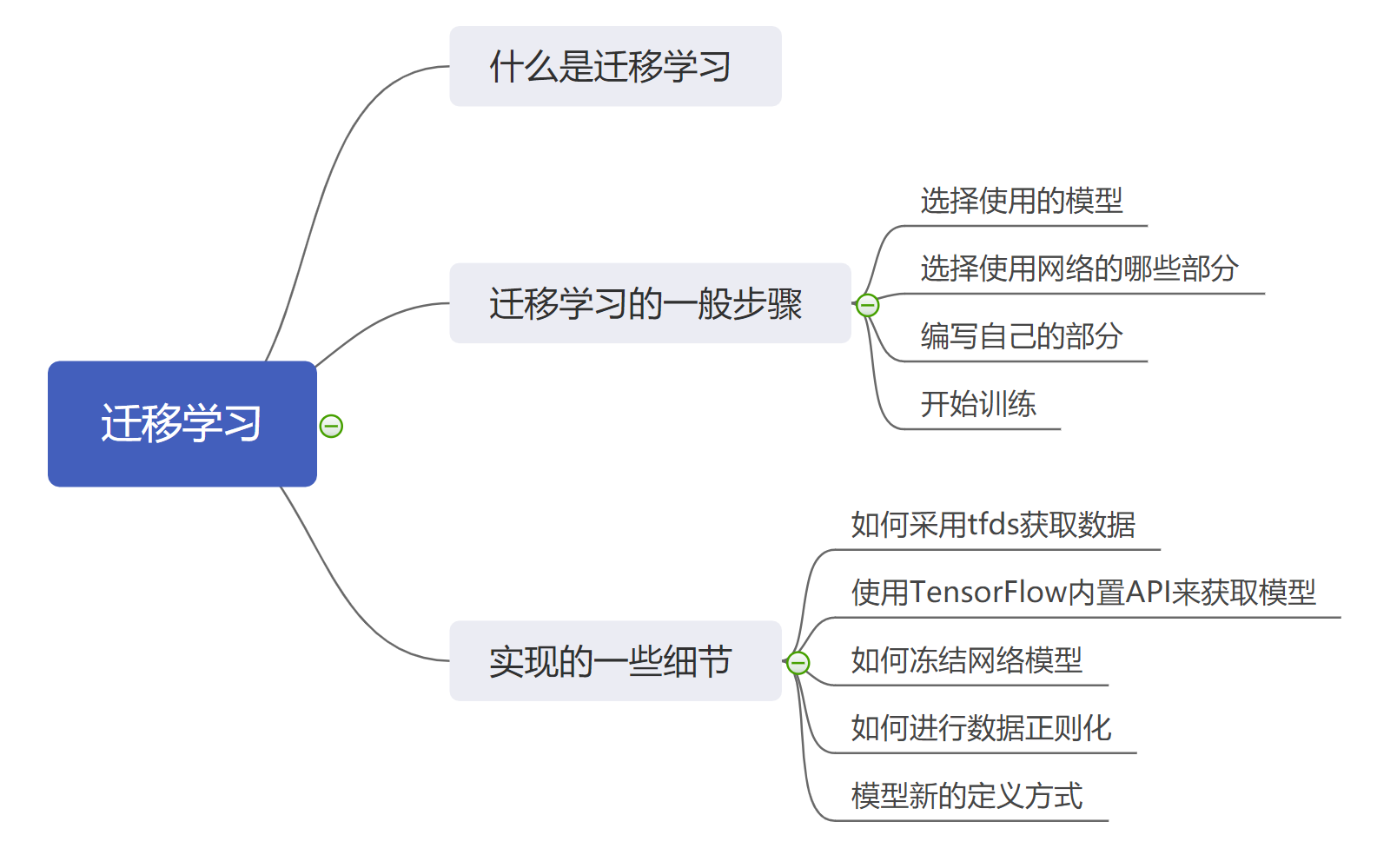
1. 什么是迁移学习
迁移学习,顾名思义,就是将学习任务迁移的意思。在实际的应用之中,我们遇到的好多学习任务都具有很强的相似性,比如图片分割任务和图片分类任务就很相似,因为他们都是对图片进行处理的任务。
而对相似数据类型进行处理的任务的模型往往可以互相迁移使用,而不必重新训练一个新的模型,从而节省时间和空间的开支。
在迁移学习的领域之中,图片处理的任务往往占据大多数,因为图片任务的处理往往都含有相似的部分 —— 提取特征。在实际的任务之中,我们往往会使用已经在大型数据集(比如 ImageNet )上训练得到的模型作为迁移学习的基本模型,以此来提取图片的特征,从而进行下一步的处理。
简单来说就是:使用别人训练好的模型来做自己的学习任务。
2. 迁移学习的基本思路
迁移学习是一个非常宽泛的概念,其的种类包括很多,我们这里以图片任务为例来讲解迁移学习的基本思路:
- 选择迁移学习的基本模型,一般为在大型数据集上训练的大型网络,比如:
- ResNet 网络;
- GoogLeNet 网络;
- Xception 网络;
- 然后选择使用网络的哪些部分,一般使用除了顶层的所有部分;
- 编写剩余的部分,也就是自己接下来的处理过程;
- 训练自己编写的处理过程。
这几个步骤看起来非常简单,在实际过程之中也是非常简单的,接下来我们就以在 ImageNet 超大数据集上训练的 Xception 模型作为基本模型进行迁移学习的演示。
3. 使用迁移学习的实例
这次,我们依然使用猫狗分类的例子来进行实现,具体的代码如下所示:
注意:部分代码来自 TensorFlow 官方 API 。
import tensorflow_datasets as tfds
import tensorflow as tf
import numpy as np
train_data, validation_data = tfds.load(
"cats_vs_dogs",
split=["train[:80%]", "train[80%:]"],
as_supervised=True,
)
# 重新调整大小
train_data = train_data.map(lambda x, y: (tf.image.resize(x, (150, 150)), y))
validation_data = validation_data.map(lambda x, y: (tf.image.resize(x, (150, 150)), y))
# 分批次
train_data = train_data.batch(32)
validation_data = validation_data.batch(32)
# 迁移模型
base_model = tf.keras.applications.Xception(
weights="imagenet",
input_shape=(150, 150, 3),
include_top=False,
)
base_model.trainable = False
# 定义输入
inputs = tf.keras.Input(shape=(150, 150, 3))
# 数据正则化
norm_layer = tf.keras.layers.experimental.preprocessing.Normalization()
x = norm_layer(inputs)
mean = np.array([127.5] * 3)
norm_layer.set_weights([mean, mean ** 2])
# 数据经过迁移模型
x = base_model(x, training=False)
# 数据经过自定义网络
x = tf.keras.layers.GlobalAveragePooling2D()(x)
outputs = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
model.fit(train_ds, epochs=20, validation_data=validation_ds)
在这里的代码之中,我们有几处需要注意的地方:
- 在数据获取方面,我们采用了 tfds.load 函数,该函数能够直接获取相应的内置数据集,同时进行相应的分割,这里我们按照 8:2 的比例来进行训练集、测试集的划分;
- 我们使用 map 函数,来将所有的数据的图片重新调整至(150, 150)大小,我们将图片调整至相同大小是为了方便后面的处理;
- 使用 tf.keras.applications.Xception API 来获取已经预训练的 Xception 模型,在该 API 之中,包含三个参数:
- weights:表示在哪个数据集上训练;
- input_shape:表示输入图片的形状;
- include_top=False:表示不含顶层网络,因为我们要定义自己的网络。
- 然后我们使用 base_model.trainable=False 语句来将基本模型的训练参数冻结,这样我们就不能训练 Xception 的参数。
- 我们使用了 tf.keras.layers.experimental.preprocessing.Normalization 这个 API 来进行数据的正则化,我们需要通过 norm_layer.set_weights () 设定它的权重:
- 第一个参数是输入的每个通道的平均值,这里是 255/2=127.5;
- 第二个参数是第一个参数的平方;
- 最后我们采用了一种新的定义模型的方式:先定义一个 Input ,然后将该 Input 逐次经过自己需要处理的网络层得到 output,最后通过 tf.keras.Model (inputs, output) 来让 TensorFlow s 根据数据的流动过程来自动生成网络模型。
最终我们可以得到结果:
Model: "functional_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_10 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
normalization_3 (Normalizati (None, 150, 150, 3) 7
_________________________________________________________________
xception (Functional) (None, 5, 5, 2048) 20861480
_________________________________________________________________
global_average_pooling2d_2 ( (None, 2048) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 2049
=================================================================
Total params: 20,863,536
Trainable params: 2,049
Non-trainable params: 20,861,487
_________________________________________________________________
Epoch 1/20
291/291 [==============================] - 9s 31ms/step - loss: 0.1607 - binary_accuracy: 0.9313 - val_loss: 0.0872 - val_binary_accuracy: 0.9703
Epoch 2/20
291/291 [==============================] - 8s 27ms/step - loss: 0.1181 - binary_accuracy: 0.9501 - val_loss: 0.0869 - val_binary_accuracy: 0.9690
......
Epoch 20/20
291/291 [==============================] - 8s 27ms/step - loss: 0.0914 - binary_accuracy: 0.9841 - val_loss: 0.0875 - val_binary_accuracy: 0.9765
我们可以看到,我们的模型最终达到了 97% 的分类准确率,这是一个非常高的准确率,而这得益于 Xception 模型强大的特征提取能力。
4. 小结
在这节课之中,我们学习了什么是迁移学习,同时了解了迁移学习的一般思路,同时我们有手动实现了一个使用迁移学习进行分类的例子。在示例之中,我们学习到了一种新的模型定义方式。