在 TensorFlow 之中使用循环神经网络
在之前的学习之中,我们使用了全连接网络、卷积神经网络以及其他的网络。今天我们要来学习另一种常用的神经・网络 —— 循环神经网络(RNN)。
1. 什么是循环神经网络
循环神经网络( recurrent neural network )简称 RNN 。顾名思义,这种网络之中包含循环的结构,因此才被称作循环神经网络。
在我们之前学习过的网络之中,网络模型只是根据不同的样本的输入来进行处理,前面的输入和后面的输入互不相干,简而言之,我们之前学习过的网络模型不包含记忆性。而循环神经网络( RNN )则可以具有记忆性,它能够 “记住” 之前的输入,从而对后面输入的判别产生影响。
举个简单的例子,当我们在看电影的时候,如果用之前学过的模型来处理,就相当于一帧接着一帧地进行分析;而如果我们使用循环神经网络来处理,就相当于将多个帧联系起来处理。
因此我们可以得出结论,循环神经网络更适合用来处理一些连续输入的数据,比如文本、视频、音频等连续的数据。
既然想要使用循环神经网络,我们便要简单的了解一下循环神经网络的基本结构。
循环神经网络的基本结构如下图所示:
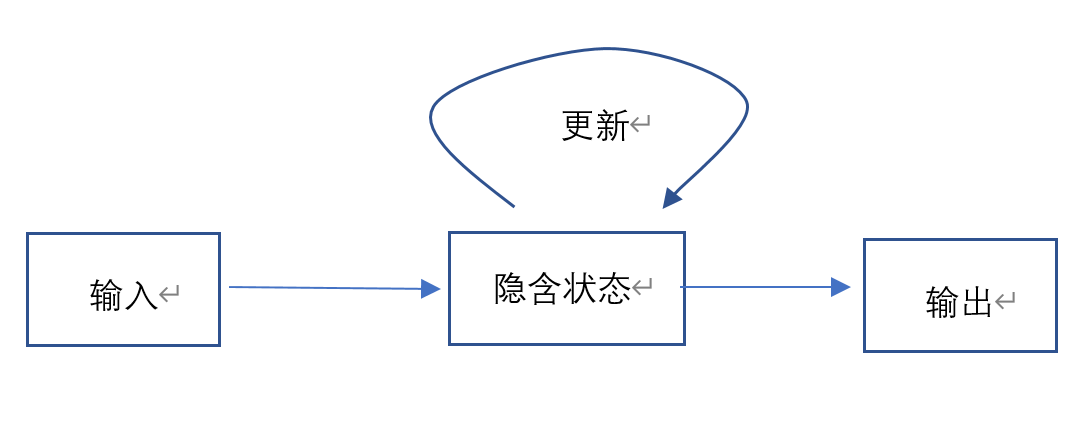
我们可以看到,与之前学习过的网络最大的不同就是该网络含有一个循环结构,具体来说,循环神经网络处理数据的基本过程为:
- 输入数据并处理;
- 数据经过隐含状态并得到两个结果:
- 这次输入数据的输出;
- 隐含状态的更新值。
- 将数据输出,同时更新隐含的状态。
正是因为 RNN 可以根据不同的输入来不断地更新自己的隐含状态,因此我们才会说 RNN 具有 “记忆性”,也就是说,隐含状态会 “记住之前地输入状态”。
在 RNN 的具体细节之中,涉及到许多的数学推导知识,我们在这里暂时不展开叙述,我们只需要学会如何使用循环神经网络即可。而且在实际的应用之中,我们会采用多个单元的方式进行,从而提升网络的容量。
2. 如何在 TensorFlow 之中使用循环神经网络
在 TensorFlow 之中使用循环神经网络也是一件非常容易的事情。但是值得注意的是,原生的循环神经网络在 TensorFlow 之中的的实现比较复杂,而且通过训练得到的效果也不是很好。因此,我们建议在 TensorFlow 之中使用 RNN 的一些变体,这些变体往往可以通过更少的工作量来获取到更好的工作成果,在这里,我们使用 LSTM (长短期记忆)与 GRU (门循环单元)为例。这两者的改变都涉及到比较底层的知识,大家不需要掌握,只需要知道这些变体能够取得更好的效果并且学会如何使用即可。
最简单的,我们可以通过使用以下 Keras 的 API 来进行长短期记忆(LSTM)的调用。
tf.keras.layers.LSTM(
units, activation='tanh', recurrent_activation='sigmoid',
dropout=0.0, recurrent_dropout=0.0, return_sequences=False,
return_state=False
)
其中的一些参数的意义如下:
- units: 正整数,输出的维度;
- activation: 要采用的激活函数,一般保持默认 “tanh” 即可;
- recurrent_activation: 在每次循环的时候要采用的激活函数,默认为 “sigmoid”;
- dropout:用来抑制过拟合的一种方法,被应用于输入的阶段;
- recurrent_dropout:用来抑制过拟合的一种方法,被应用于循环的阶段;
- return_sequences:布尔值,是否返回一个完整的输出序列,还是只返回最后一个输出;
- return_state:布尔值,是否返回中间的隐含状态。
对于 GRU ,我们可以使用以下的 API 实现。
tf.keras.layers.GRU(
units, activation='tanh', recurrent_activation='sigmoid', dropout=0.0,
recurrent_dropout=0.0, return_sequences=False, return_state=False
)
可以看到 GRU 的 API 和 LSTM 的 API 的参数非常相似,而实际上他们的含义也相同。
- units: 正整数,GRU 输出的维度;
- activation: GRU 要采用的激活函数,一般保持默认 “tanh” 即可;
- recurrent_activation: GRU 在每次循环的时候要采用的激活函数,默认为 “sigmoid”;
- dropout:用来抑制过拟合的一种方法,被应用于 GRU 输入的阶段;
- recurrent_dropout:用来抑制过拟合的一种方法,被应用于 GRU 循环的阶段;
- return_sequences:布尔值,定义 GRU 是否返回一个完整的输出序列,还是只返回最后一个输出;
- return_state:布尔值,决定 GRU 是否返回中间的隐含状态。
3. 在 TensorFlow 之中使用循环神经网络的示例
这一小节,我们将会使用一个具体的程序实例来演示如何在 TensorFlow 之中使用循环神经网络,在这里,我们会使用 LSTM 举例,大家也可以常使使用 GRU 等其他循环神经网络。与往常一样,我们仍然采用的是 IMDB 电影评价的数据集来进行演示。
在这里,我们具体的程序为:
import tensorflow as tf
import numpy as np
# 定义基本参数
words_num = 10000
val_num = 12500
EPOCHS = 10
pad_max_length = 256
BATCH_SIZE = 64
# 获取数据
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words=words_num)
word_index = tf.keras.datasets.imdb.get_word_index()
# 添加特殊字符
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<pad>"] = 0
word_index["<start>"] = 1
word_index["<unknown>"] = 2
word_index["<unused>"] = 3
# 数据预处理
train_data = tf.keras.preprocessing.sequence.pad_sequences(train_data, value=0, padding='post', maxlen=pad_max_length)
test_data = tf.keras.preprocessing.sequence.pad_sequences(test_data, value=0, padding='post', maxlen=pad_max_length)
# 划分训练集合与验证集合
x_val, x_train = train_data[:val_num], train_data[val_num:]
y_val, y_train = train_labels[:val_num], train_labels[val_num:]
# 模型构建
model = tf.keras.Sequential([
tf.keras.layers.Embedding(words_num, 32),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练
history = model.fit(x_train, y_train, epochs=EPOCHS,
batch_size=BATCH_SIZE, validation_data=(x_val, y_val))
# 测试
results = model.evaluate(test_data, test_labels)
print(results)
可以看到,我们的代码与之前的模型几乎完全相同,只是我们的网络模型采用了 LSTM(长短期记忆),大家可以将这次运行的结果与之前运行的结果相比较。
该处的代码中,我们需要注意的一点是,我们将 LSTM 用 tf.keras.layers.Bidirectional () 这一网络层包裹起来了。顾名思义,这一个双向的网络层,通过将 LSTM 使用该网络层包裹,LSTM 不仅仅能够学习到正向的信息,也能学习到反向的信息。举个不恰当的例子,相当于人可以反着读书一样。这可以增强循环神经网络提取信息的能力,童儿提升模型的效果。
最终,通过运行代码,我们可以得到输出:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 32) 320000
_________________________________________________________________
bidirectional_1 (Bidirection (None, 128) 49664
_________________________________________________________________
dense_6 (Dense) (None, 64) 8256
_________________________________________________________________
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 377,985
Trainable params: 377,985
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
196/196 [==============================] - 72s 369ms/step - loss: 0.5292 - accuracy: 0.7088 - val_loss: 0.3791 - val_accuracy: 0.8432
Epoch 2/10
196/196 [==============================] - 71s 360ms/step - loss: 0.2714 - accuracy: 0.8993 - val_loss: 0.3445 - val_accuracy: 0.8719
Epoch 3/10
196/196 [==============================] - 71s 363ms/step - loss: 0.1885 - accuracy: 0.9358 - val_loss: 0.3460 - val_accuracy: 0.8706
Epoch 4/10
196/196 [==============================] - 72s 365ms/step - loss: 0.1363 - accuracy: 0.9550 - val_loss: 0.3765 - val_accuracy: 0.8563
Epoch 5/10
196/196 [==============================] - 71s 363ms/step - loss: 0.0915 - accuracy: 0.9713 - val_loss: 0.4558 - val_accuracy: 0.8667
Epoch 6/10
196/196 [==============================] - 71s 362ms/step - loss: 0.0798 - accuracy: 0.9733 - val_loss: 0.7503 - val_accuracy: 0.8242
Epoch 7/10
196/196 [==============================] - 71s 363ms/step - loss: 0.0617 - accuracy: 0.9807 - val_loss: 0.5544 - val_accuracy: 0.8570
Epoch 8/10
196/196 [==============================] - 70s 359ms/step - loss: 0.0636 - accuracy: 0.9782 - val_loss: 0.5350 - val_accuracy: 0.7421
Epoch 9/10
196/196 [==============================] - 70s 357ms/step - loss: 0.0934 - accuracy: 0.9661 - val_loss: 0.6706 - val_accuracy: 0.8348
Epoch 10/10
196/196 [==============================] - 70s 356ms/step - loss: 0.0976 - accuracy: 0.9638 - val_loss: 0.5770 - val_accuracy: 0.8568
782/782 [==============================] - 34s 43ms/step - loss: 0.6340 - accuracy: 0.8440
[0.6339613795280457, 0.843999981880188]
可以看到,我们的网络模型的准确率达到了 84% ,对于之前的网络来说是一个不小的提升。
4. 总结
在这节课之中,我们学习了什么是循环神经网络,并且详细的了解了循环神经网络在 TensorFlow 之中的使用方法。与此同时,我们使用了一个具体的网络示例来展示了如何完整地使用 LSTM ,而这也达到了不错的效果。