使用 Estimator 实现 Boosting Tree 模型
在学习 TensorFlow 的过程之中,最好的方式是结合示例来进行学习,并且加以相应的训练。因此这节课我们就来学习一下 Estimator 模型的一个经典示例:Boosting Tree 模型,也被称作提升树模型。
在这节课程之中,我们会学习什么是 Boosting Tree ,它的一些简单的工作原理,同时学习如何使用 Estimator 来实现一个简单的 Boosting Tree 模型。
1. 什么是 Boosting
首先,Boosting 是机器学习中的集成学习的一种。
那么什么是集成学习呢?简单来说,集成学习就是使用多个模型来一同学习,最后在每个模型都得到预测结果后再经过进一步的集成处理得到最终预测结果的一种学习方法。值得注意的是,不同的集成学习方法有着不同的集成方法,常见的包括 Bagging、Boosting 等集成方法。
下面我们可以简单的了解一下这两种集成方法(我们的重点在集成,因此省略掉了相应的采样工作)。
- Bagging 集成方法:这种集成方法的思想比较简单,在每个模型都得到一个结果之后,我们会采用一种更加民主的方式进行:
- 对于回归问题,我们使用的是取均值操作;
- 对于分类问题,我们采用的是投票方法,也就是选取出现次数最多的那个。
- 在 Bagging 之中,每个模型的重要性是相同的。
- Boosting 集成方法:这种集成方法就是我们这节课要采用的,相对复杂一些:
- 我们首先采用加法线性组合对各个模型进行处理;
- 然后我们得到每个模型的错误率;
- 最后对于错误率小的模型,我们会减少它的权重(话语权),反而提升一些错误率高的模型的权重(话语权)。
- 在 Boosting 之中,每个模型的重要性是不同的。
既然了解了什么是 Boosting 方法,那么我们便要简单学习一下提升树的基础模型:决策树。
2. 什么是决策树(Tree)
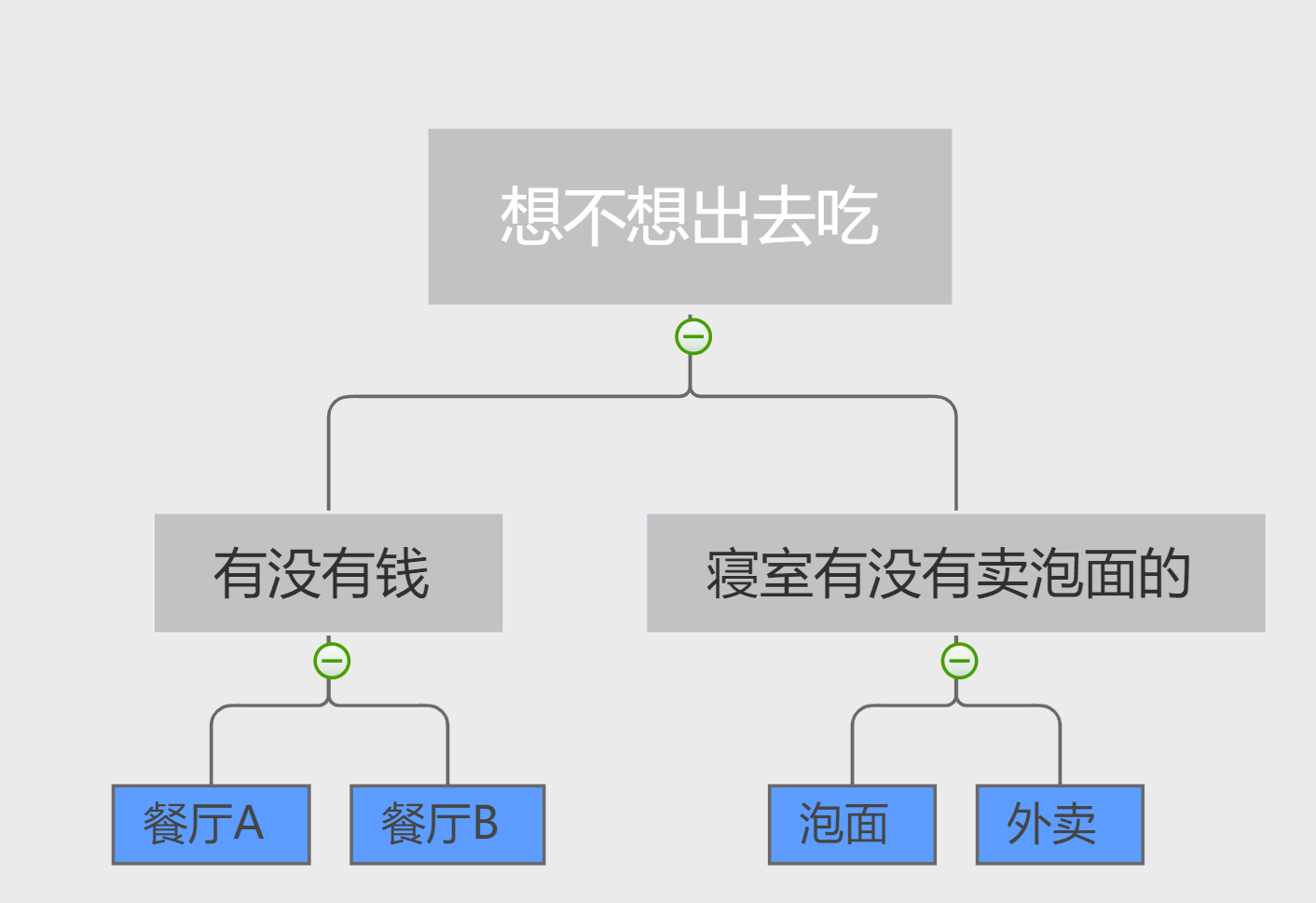
决策树其实很简单,我们日常生活中用到的例子非常多,举个简单的分类的例子:
我中午饿了,要去吃饭,学校里面一共有两个餐厅,而我一共有4个选择:
- A餐厅:价格贵;
- B餐厅:价格便宜;
- 吃泡面:不用出宿舍,前提是宿舍售卖机有卖;
- 点外卖:不用出宿舍。
那么,我们的决策树就如下图所示:如果我想出门而且有钱,我就去 A 餐厅;如果我想出门但是却钱不多,那么我就去 B 餐厅;倘若我不想出宿舍而刚刚好宿舍有卖泡面,我就可以直接吃泡面;到那时如果没有泡面的话,我就只能点外卖。
这只是一个简单的理解,而具体的优化的细节涉及到许多的数学原理,这里就不过多解释了。
3. 如何在 TensorFlow 的 Estimator 之中使用提升树
既然我们了解了 Boosting ,也知道了 Tree ,那么接下来就是了解如何在 Estimator 之中使用Boosting Tree。在这节课之中,我们依然使用泰坦尼克数据集为示例来进行演示,这是我们接触过的一个二分类问题。
其实在 Estimator 之中,已经包含一个内置的 API 来向我们提供一个提升树分类器,刚刚好符合我们对数据分类的要求。
tf.estimator.BoostedTreesClassifier()
通过该API我们可以直接构造一个用于分类的提升树。
4. 具体的实现细节
首先我们和之前一样,进行数据的获取:
import numpy as np
import pandas as pd
import tensorflow as tf
x_train = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
x_test = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = x_train.pop('survived')
y_test = x_test.pop('survived')
然后我们要定义连序列以及离散列:
categories = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck', 'embark_town', 'alone']
numeric = ['age', 'fare']
然后我们就要定义特征列了:
def one_hot_cat_column(feature_name, vocab):
return tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocab))
feature_columns = []
for feature_name in categories:
feature_columns.append(one_hot_cat_column(feature_name, x_train[feature_name].unique()))
for feature_name in numeric:
feature_columns.append(tf.feature_column.numeric_column(feature_name,dtype=tf.float32))
在第一个 one_hot_cat_column 函数之中,我们对于特征列进行了独热编码。并且我们对于离散列与连续列进行了不同的处理。
然后我们定义输入函数,这里我们仍然定义了两个输入函数,一个为训练使用,另一个为测试使用:
def train_input_fn(x, y):
dataset = tf.data.Dataset.from_tensor_slices((dict(x), y))
dataset = dataset.shuffle(len(y_train)).repeat().batch(32)
return dataset
def test_input_fn(x, y):
dataset = tf.data.Dataset.from_tensor_slices((dict(x), y)).batch(32)
return dataset
train_input = lambda: train_input_fn(x_train, y_train)
test_input = lambda: test_input_fn(x_test, y_eval)
在这之后,我们便需要定义我们的提升树模型了:
estimator = tf.estimator.BoostedTreesClassifier(feature_columns, n_batches_per_layer=len(y_train) // 32)
这里的第一个参数 feature_columns 就是特征列,这个很好理解;关键是第二个参数,大家要记住的是, n_batches_per_layer 这个参数需要是样本的数量与批次大小的商,因为这里我们的批次大小为 32 ,因此我们设置其为 (y_train) // 32 。
最后便是模型的训练了:
estimator.train(train_input, max_steps=100)
result = estimator.evaluate(test_input)
print(pd.Series(result))
于是我们可以的得到输出:
accuracy 0.787879
accuracy_baseline 0.625000
auc 0.835384
auc_precision_recall 0.825271
average_loss 0.554901
label/mean 0.375000
loss 0.552625
precision 0.747126
prediction/mean 0.454899
recall 0.656566
global_step 100.000000
dtype: float64
于是我们可以得到了我们训练结果: 78% 的准确率。
为了做对比,大家可以采用一个简单的线性分类器来做对比,也就是:
tf.estimator.LinearClassifier(feature_columns)
通过对比,大家就可以看到集成学习的优势。
5. 小结
在这节课之中,我们学习了什么是集成学习以及集成学习的两种常用的集成方法。同时我们也了解了什么是决策树。最后我们在实践中学习了如何使用 Estimator 来实现一个提升树模型。