文本数据嵌入
在之前的学习之中,我们已经简单地学习了如何进行文本数据的处理:
- 使用 tf.data.TextLineDataset 加载文本数据;
- 使用编码将数据进行编码。
而在这节课之中,我们将详细地了解将文本数据编码的各种方法,并且对最常用的字词嵌入方法进行深入研究,最后我们会给出一个完整的模型来对电影评价进行分类。
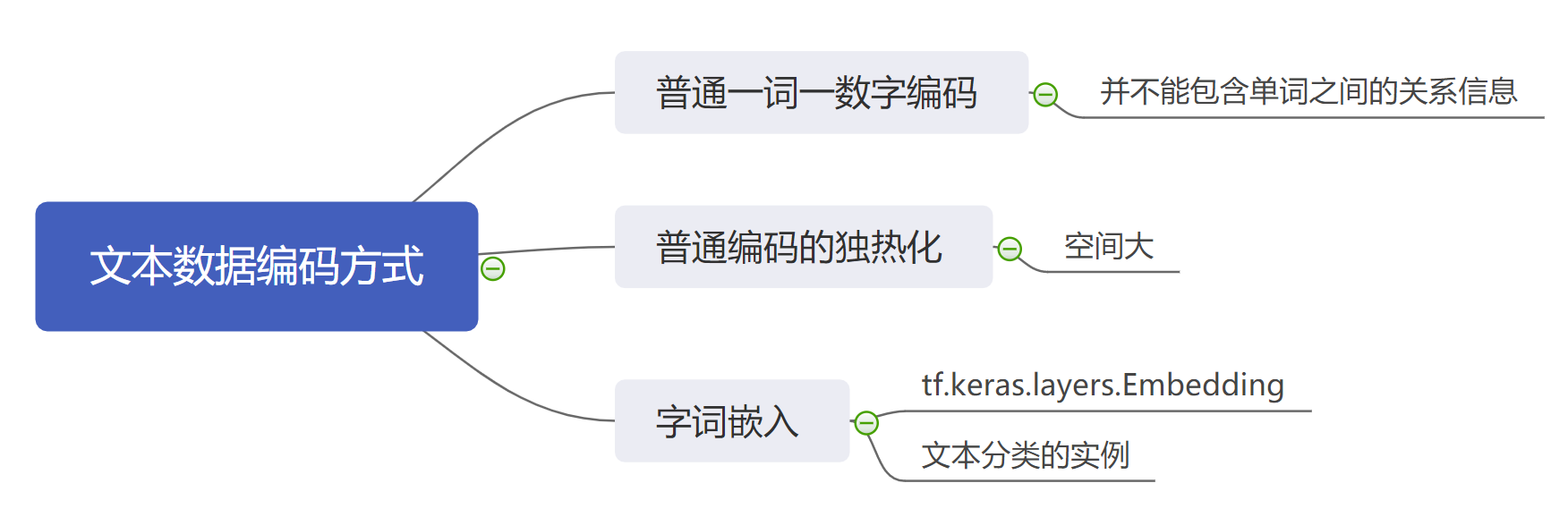
1. 文本数据编码的方法
在机器学习领域,所有模型的处理数据都是数字类型的数据。因此在文本处理的过程之中,如何将文本数据转化为数字类型数据是一个重要的研究课题。纵观所有的数据编码方法,我们可以将常用的编码方法大致可以分为三类:
- 简单编码处理;
- 简单编码后独热处理;
- 字词嵌入处理。
1.1 简单编码处理
假如我们有一个英文句子:
s = "How are you"
那么简单编码处理就是对每个单词赋予一个独特的数字,用来表示该数字。比如:
"How" = 0
"are" = 1
"you" = 2
那么我们便可以将字符串s编码为:
s_1 = [0, 1, 2]
相应的“How you are”快就可以编码为:
s_2 = [0, 2, 1]
这种编码方式最大的好处是简单,非常容易理解,而且占用的空间资源很少。
但是这种方法也有缺点:
- 那就是这种编码方式无法识别两个单词之间的关系,也就是说两个数字之间的关系不能代表实际的两个单词的关系,比如我们直观理解 How 和 You 的关系更近一些,然而 How 和 You 的编码距离是 2 ,而 are 和 you 的距离却是 1 。
- 同时也正是因为上面的原因,导致不同的编码规则会产生截然不同的效果,因为我们的“How are you”完全可以编码为 [111, 222, 333] ,而这会导致编码后的数据只能依靠固定的编码规则使用。
1.2 简单编码的独热化
这种编码和上述编码方式一样,只是进行了一些独热化处理,因为独热化处理能够让模型在分类任务上拥有更好的性质。
比如上述的例子:
s = "How are you"
按照独热编码可以看作是:
"How" = [1, 0, 0]
"are" = [0, 1, 0]
"you" = [0, 0, 1]
虽然独热编码具有更好的性值,但是它仍然没有解决上面的问题,也就是说它依然无法表示两个单词之间的关系。不仅如此,它还引入了新的问题:存储空间开销巨大。因为每个单词的存储大小都是一个所有词汇量大小的一个数组。
1.3 字词嵌入
这种处理方式我们之前有过稍微的接触,字词嵌入会根据相关指定的参数来为每个单词生成一个固定长度的向量。
比如上面的英文句子:
s = "How are you"
编码后可能变为:
s_3 = [[1.9, 0.4,-0.3],[0.74, 0.23, -0.3],[0.5, 0.6, 0.7]]
通过这种形式的编码处理,我们已经很难通过肉眼来看出原来的句子了,但是对于机器学习的网络模型来说,它却可以进行更快速的处理,同时它其中也包含着不同单词之间的距离信息。
2. 使用 tf.keras.layers.Embedding 进行字词嵌入
该嵌入函数API的常用参数如下所示:
tf.keras.layers.Embedding(
input_dim, output_dim, embeddings_initializer='uniform',
embeddings_regularizer=None
)
这几个参数的具体含义包括:
- input_dim: 输入的维度,对于字词嵌入来说就是词汇量的大小;
- output_dim: 产出的维度,简单来说就是对单词嵌入产生的向量的长度;
- embeddings_initializer: 如何对嵌入进行初始化;
- embeddings_regularizer: 嵌入的正则化项,比如之前的L2正则化。
通过这些参数,我们可以发现,我们在进行字词嵌入之前谓一需要做的就是找到词汇量的大小,而这一般是人为规定的。
我们可以通过一个简单的示例来看一下它是如何工作的:
layer = tf.keras.layers.Embedding(100, 5) # 100表示词汇量大小,5表示产出维度
print(layer(tf.constant([1,2,3,4,5])).numpy())
我们可以得到输出:
[[-0.00772538 -0.00696523 -0.0306471 0.01268767 -0.0099443 ]
[-0.00331452 -0.00279518 -0.03783524 0.00927589 -0.02038437]
[ 0.03577108 0.01887624 -0.00056656 -0.00773742 0.03503906]
[ 0.02601126 0.02511038 0.01170179 -0.02206317 -0.03981184]
[-0.00608523 0.03906326 0.02454172 -0.0453696 -0.00303098]]
可以看到,我们的嵌入层已经成功进行了嵌入。
3. 使用字词嵌入进行电影评论分类
我们这里还是使用之前的电影评价进行分类,在这里,我们不仅仅使用了嵌入层进行处理,我们还手动规定了最大的词汇量为 10000 (这是为了避免一些生僻的单词的不利影响,同时降低运算量),同时我们将单词数据提前填充到了相同的长度 256 ,具体代码展示如下:
import tensorflow as tf
# 使用内置API获取数据,同时规定最大的词汇量为10000
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words=10000)
# 文本数据对齐
train_data = tf.keras.preprocessing.sequence.pad_sequences(train_data, value=0, padding='post', maxlen=256)
test_data = tf.keras.preprocessing.sequence.pad_sequences(test_data, value=0, padding='post', maxlen=256)
# 模型构建与编译
model = tf.keras.Sequential([
tf.keras.layers.Embedding(10000, 32),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练与测试
history = model.fit(train_data, train_labels, epochs=30, batch_size=64)
results = model.evaluate(test_data, test_labels)
print(results)
最终,我们可以得到结果:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 32) 320000
_________________________________________________________________
global_average_pooling1d_2 ( (None, 32) 0
_________________________________________________________________
dense_4 (Dense) (None, 64) 2112
_________________________________________________________________
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 322,177
Trainable params: 322,177
Non-trainable params: 0
_________________________________________________________________
Epoch 1/30
391/391 [==============================] - 3s 7ms/step - loss: 0.5101 - accuracy: 0.7729
Epoch 2/30
391/391 [==============================] - 3s 7ms/step - loss: 0.2611 - accuracy: 0.8996
..........
Epoch 29/30
391/391 [==============================] - 3s 7ms/step - loss: 0.0013 - accuracy: 1.0000
Epoch 30/30
391/391 [==============================] - 3s 7ms/step - loss: 0.0010 - accuracy: 1.0000
782/782 [==============================] - 1s 1ms/step - loss: 1.6472 - accuracy: 0.8312
[1.6471874713897705, 0.8312000036239624]
可以发现我们的模型准确率最终达到了 83% 的准确率,这是一个比较可以接收的结果。同时我们也可以发现模型的参数主要集中在嵌入层当中。
4. 总结
在这节课之中,我们学习了文本嵌入的三种方法,同时我们对最常用的字词嵌入的方法进行了详细的了解,最后我们根据一个电影评价分类的例子来进行了联系。