在 Keras 中进行模型的评估
在我们进行模型训练的过程之中总是避免不了进行模型的评估,从而判别一个模型是好是坏,进而帮助我们选择较好的模型进行使用。
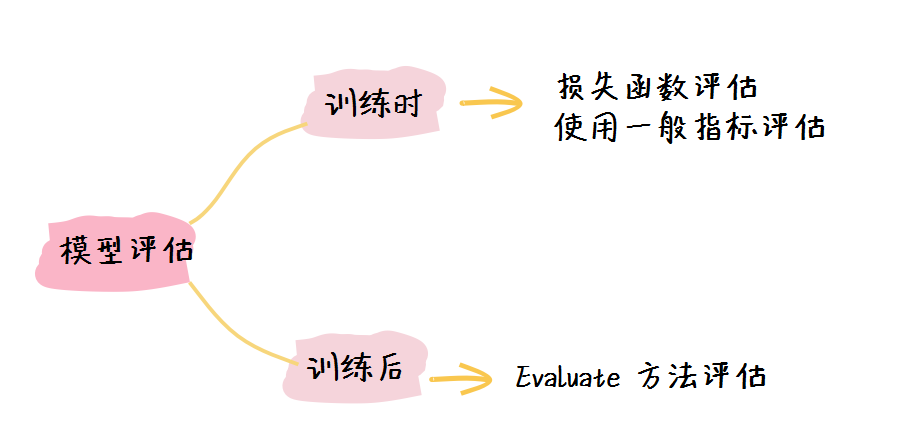
那么我们这节课就来学习一下如何进行模型的评估。这节课是在之前的 fashion_mnist 数据集合实验的基础上进行进一步的改进,常用模型的评估方法大致分为两类:
- 根据训练过程中的指标进行评估;
- 训练结束后在验证集合或者测试集合上进行测试。
总体而言,第二种方法是采用较多的方法,因为模型训练的目的不是在已知的数据集合上表现良好,而是要在未知的数据集合上表现良好。
1. 根据训练过程中的指标进行评估
在训练过程中根据指标进行评估的时候大致可以分为两个类别:
- 根据损失函数进行评价;
- 根据普通的指标进行评价。
1· 根据损失函数进行评价
根据损失函数评价比较简单,因为损失函数是所有的训练过程都需要定义的,而损失函数也会在训练的过程之中自动记录与保存。
对于所有的损失函数而言,损失函数越小,表示我们的模型越精确。我们平常一些常见的损失函数包括:
- MAE:均绝对误差,用于回归任务学习的损失函数;直观地可以理解为误差的的均值;
- MSE:均方误差,用于回归任务学习的损失函数;与 MAE 相似,直观地可以理解为误差的平方的均值;
- Binary_CrossEntropy:二元交叉熵,用于二分类学习的损失函数,描述的是标签和预测值的差距;
- Categorical_CrossEntropy:交叉熵,与二元交叉熵类似,只是用于多分类的任务的损失函数。
在使用的时候要首先在模型编译的时候指定损失函数,在后面的训练过程中 TensorFlow 会帮助我们自动记录损失函数的变化。比如以下的示例:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy')
在训练的过程之中,我们可以根据日志的输出来查看损失函数的变化:
......
Epoch 2/5
1875/1875 [==============================] - 5s 2ms/step - loss: 0.3616
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3256
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3006
......
一般而言损失函数的值会不断变小,如果损失函数变大或者不变,则表示我们的模型出错,抑或是获得的数据出错。
2. 根据普通的指标进行评价
如果要使用普通的评价指标,比如准确率,那么我们需要在模型的编译过程之中使用 metrics 参数来设置我们需要追踪的指标。比如如下例子:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
在上面的代码之中,我们规定了准确率这个指标,那么在训练的过程之中 TensorFlow 便会帮助我们评价该指标,并将结果在日志中输出。比如如下输出:
Epoch 2/5
1875/1875 [==============================] - 5s 2ms/step - loss: 0.3616 - accuracy: 0.8679
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3256 - accuracy: 0.8795
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3006 - accuracy: 0.8883
当然我们可以追踪的指标不止准确率这一个,我们在TensorFlow可以经常用到的指标主要有:
- Accuracy:准确率,用于分类任务;
- Mean: 平均值;
- TruePositives:真正例的数量,用于二分类任务,(真正例:实际类别和预测类别都为正,简写 TP );
- TrueNegatives:真负例的数量,用于二分类任务,(真反例:实际类别和预测类别都为负,简写 TN )
- FalsePositives:假正例的数量,用于二分类任务,(假正例:预测为正,实际为负,简写 FP );
- FalseNegatives:假负例的数量,用于二分类任务,(假反例:预测为负,实际为正,简写 FN );
- Precision:精确率,用于二分类任务,Precision = TP/(TP+FP));
- Recall:召回率,用于二分类任务,Recall = TP/(TP+FN);
- AUC:用于二分类任务的一个指标,可以理解为正样本的预测值大于负样本的概率;
- MSE:均方误差,用于回归任务,可作为损失函数;
- MAE:均绝对误差,用于回归任务,可以作为损失函数;
- RMSE:均方根误差,用于回归任务,可作为损失函数,由MSE开方即可得到;
2. 在验证集合或者测试集合上进行测试
在测试集合上进行验证需要我们首先在数据集合中预留出一定的测试集合,一般而言,我们会将所有数据的 80% 用于训练集合,而剩下的 20% 用于测试集合。
在测试集合上我们主要是使用 evaluate 方法进行模型的评估:
model.evaluate(x_test, y_test)
其中假设我们的模型已经经过,而 x_test 与 y_test 分别是测试集合的数据和标签。
我们可以得到如下输出:
313/313 - 0s - loss: 0.3444
0.34437522292137146
如果我们在模型编译的过程之中添加了指标,比如准确率:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
那么我们会得到输出:
313/313 - 0s - loss: 0.3836 - accuracy: 0.8792
[0.3835919201374054, 0.8791999816894531]
可以看到,evaluate 方法会记录损失函数和编译中指定的指标。而在 evaluate 函数中返回的指标一般可以作为我们参考的较为可靠的依据。
3. 小结
在这节课之中我们学习了如何进行模型的评估,主要包括如何在训练的过程中进行评估以及如何在训练结束后进行评估。