Scrapy与 Selenium 的结合
今天我们来使用 Scrapy 和 Selenium 结合爬取京东商城中网络爬虫相关的书籍数据。
1. 需求分析与初步实现
今天我们的目的是使用 Scrapy 和 Selenium 结合来爬取京东商城中搜索 “网络爬虫” 得到的所有图书数据,类似于下面这样的数据:
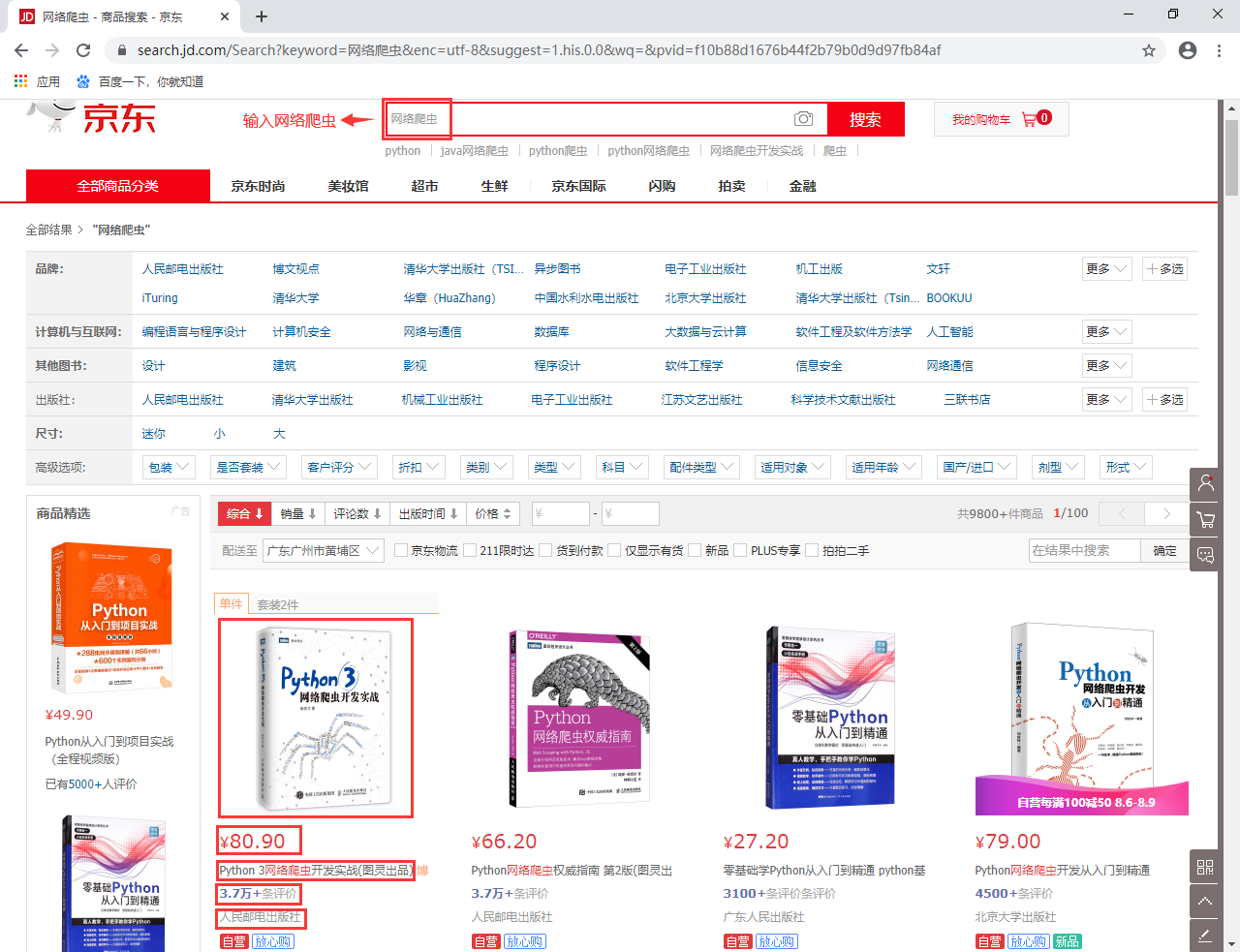
搜索出的结果有9800+条数据,共计100页。我们现在要抓取所有的和网络爬虫相关的书籍数据。有一个问题需要注意,搜索的100页数据中必定存在重复的结果,我们可以依据图书的详细地址来进行去重。此外,我们提取的图书数据字段有:
- 图书名;
- 价格;
- 评价数;
- 店铺名称;
- 图书详细地址;
需求已经非常明确,现在开始使用 Selenium 和 Scrapy 框架结合来完成这一需求。来看看如果我们是单纯使用 Selenium 工具,该如何完成数据爬取呢?这里会有一个问题需要注意:按下搜索按钮后,显示的数据只有30条,只有使用鼠标向下滚动后,才会加载更多数据,最终显示60条结果,然后才会到达翻页的地方。在 selenium 中我们可以使用如下两行代码实现滚动条滑到最底端:
height = driver.execute_script("return document.body.scrollHeight;")
driver.execute_script(f"window.scrollBy(0, {height})")
time.sleep(2)
可以看到,上面两行代码主要是执行 js 语句。第一行代码是得到页面的底部位置,第二行代码是使用 scrollBy() 方法控制页面滚动条移动到底部。接下来,我们来看看页面数据的提取,直接右键 F12,可以通过 xpath 表达式得到所有需要抓取的数据。为此,我编写了一个根据页面代码提取图书数据的方法,具体如下:
def parse_book_data(html):
etree_html = etree.HTML(html)
# 获取列表
gl_items = etree_html.xpath('//div[@id="J_goodsList"]/ul/li')
print('总共获取数据:{}'.format(len(gl_items)))
res = []
for item in gl_items:
book_name_em = item.xpath('.//div[@class="p-name"]/a/em/text()')[0]
book_name_font = item.xpath('.//div[@class="p-name"]/a/em/font/text()')
book_name_font = "".join(book_name_font) if book_name_font else ""
# 获取图书名
book_name = f"{book_name_em}{book_name_font}"
# 获取图书的详细介绍地址
book_detail_url = item.xpath('.//div[@class="p-name"]/a/@href')[0]
# 获取图书价格
price = item.xpath('.//div[@class="p-price"]/strong/i/text()')[0]
# 获取评论数
comments = item.xpath('.//div[@class="p-commit"]/strong/a/text()')[0]
# 获取店铺名称
shop_name = item.xpath('.//div[@class="p-shopnum"]/a/text()')
shop_name = shop_name[0] if shop_name else ""
data = {}
data['book_name'] = book_name
data['book_detail_url'] = book_detail_url
data['price'] = price
data['comments'] = comments
data['shop_name'] = shop_name
res.append(data)
# 返回页面解析的结果
print('本页获取的结果:{}'.format(res))
return res
现在来思考下如何能使用 selenium 一页一页访问?我给出了如下代码:
def get_page_data(driver, page):
"""
:driver 驱动
:page 第几页
"""
# 请求当前页
if page > 1:
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, 'J_bottomPage'))
)
driver.find_element_by_xpath(f'//div[@id="J_bottomPage"]/span/a[text()="{page}"]').click()
time.sleep(2)
# 滚动到最下面,出现京东图书剩余书籍数据
height = driver.execute_script("return document.body.scrollHeight;")
driver.execute_script(f"window.scrollBy(0, {height})")
time.sleep(2)
return parse_book_data(driver.page_source)
对于第一页的访问是在输入关键字<网络爬虫>后点击按钮得到的,我们不需要放到这个函数来得到,只需要滚动到底部得到所有的图书数据即可;而对于第2页之后的页面,我们需要使用 selenium 的模拟鼠标点击功能,点击下对应页后便能跳转得到该页,然后再滚动到底部,就可以得到整页的搜索结果。我们来看看完整的实现:
import time
import random
import re
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from lxml import etree
def get_page_data(driver, page):
"""
:driver 驱动
:page 第几页
"""
# 具体代码参考上面
# ...
def parse_book_data(html):
"""
解析页面图书数据
"""
# 具体代码参考上面
# ...
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ['enable-automation'])
driver = webdriver.Chrome(options=options, executable_path="C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe")
driver.maximize_window()
driver.get("https://www.jd.com/")
# 输入网络爬虫,然后点击搜索
driver.find_element_by_id('key').send_keys('网络爬虫')
driver.find_elements_by_xpath('//div[@role="serachbox"]/button')[0].click()
time.sleep(2)
max_page = 100
for i in range(1, max_page + 1):
get_page_data(driver, i)
下面来看看代码执行的效果,这里为了能尽快执行完,我将 max_page 参数调整为10,只获取10页搜索结果,一共是600条数据:
从上面的演示中,可以看到最后每页抓取的数据都是60条。
2. Scrapy 与 Selenium 结合爬取京东图书数据
接下来我们对上面的代码进行调整和 Scrapy 框架结合,而第一步需要做的就是建立好相应的工程:
# 创建爬虫项目
PS D:\shencong\scrapy-lessons\code\chap17> scrapy startproject jdbooks
# ...
# 进入到spider目录,使用genspider命令创建爬虫文件
PS D:\shencong\scrapy-lessons\code\chap17\jd_books\jd_books\spiders> scrapy genspider jd www.jd.com
创建好工程后就是编写 items.py 中的 JdBooksItem 类,这非常简单,直接根据我们前面定义好的字段编写相应的代码即可:
class JdBooksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
book_name = scrapy.Field()
price = scrapy.Field()
comments = scrapy.Field()
shop_name = scrapy.Field()
book_detail_url = scrapy.Field()
整个项目的难点是如何实现下一页数据的爬取?前面可以使用 selenium 去自动点击页号而进入下一个,然而在 Scrapy 中却不太好这样处理。我们通过分析京东搜索的 URL 后发现,其搜索的 URL 可以简化为如下形式:https://search.jd.com/Search?keyword=搜索关键字&page=(页号* 2 - 1),我们只需要提供搜索的关键字以及相应的请求页号即可。例如下图所示:
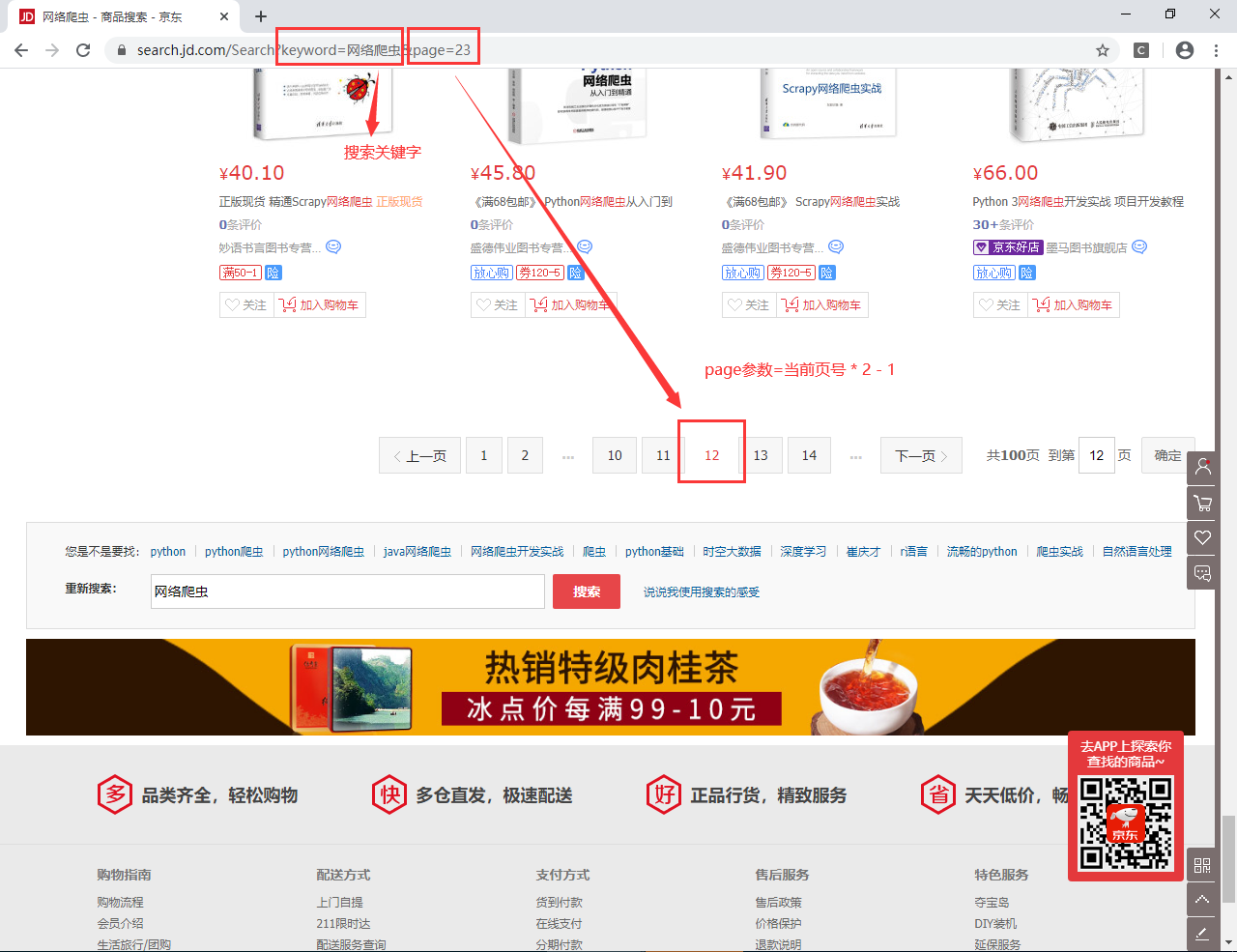
因此我们在 settings.py 中准备两个参数:一个是搜索的关键字,另一个是爬取的最大页数。具体的形式如下:
# settings.py
# ...
KEYWORD = "网络爬虫"
MAX_PAGE = 10
紧接着我们可以构造出请求不同页的 URL 并交给 Scrapy 的引擎和调度器去处理,对应的 Spider 代码如下:
# 代码位置:jd_books/jd_books/spiders/jd.py
from urllib.parse import quote
from scrapy import Spider, Request
from jd_books.items import JdBooksItem
class JdSpider(Spider):
name = 'jd'
allowed_domains = ['www.jd.com']
start_urls = ['http://www.jd.com/']
base_url = "https://search.jd.com/Search?keyword={}&page={}"
def start_requests(self):
keyword = self.settings.get('KEYWORD', "Python")
for page in range(1, self.settings.get('MAX_PAGE') + 1):
url = self.base_url.format(quote(keyword), page * 2 - 1)
yield Request(url=url, callback=self.parse_books, dont_filter=True)
def parse_books(self, response):
goods_list = response.xpath('//div[@id="J_goodsList"]/ul/li')
print('本页获取图书数目:{}'.format(len(goods_list)))
for good in goods_list:
book_name_em = good.xpath('.//div[@class="p-name"]/a/em/text()').extract()[0]
book_name_font = good.xpath('.//div[@class="p-name"]/a/em/font/text()').extract()
book_name_font = "".join(book_name_font) if book_name_font else ""
book_name = f"{book_name_em}{book_name_font}"
book_detail_url = good.xpath('.//div[@class="p-name"]/a/@href').extract()[0]
price = good.xpath('.//div[@class="p-price"]/strong/i/text()').extract()[0]
comments = good.xpath('.//div[@class="p-commit"]/strong/a/text()').extract()[0]
shop_name = good.xpath('.//div[@class="p-shopnum"]/a/text()').extract()[0]
item = JdBooksItem()
item['book_name'] = book_name
item['book_detail_url'] = book_detail_url
item['price'] = price
item['comments'] = comments
item['shop_name'] = shop_name
yield item
上面的代码就是单纯的生成多页的 Request 请求 (start_requests() 方法) 和解析网页数据 (parse_books() 方法)。这个解析数据完全依赖于我们获取完整的页面源码,那么如何在 Scrapy 中使用 selenium 去请求 URL 然后获取页面源码呢?答案就是下载中间件。我们在编写一个下载中间件,拦截发送的 request 请求,对于请求京东图书数据的请求我们会切换成 selenium 的方式去获取网页源码,然后将得到的页面源码封装成 Response 响应并返回。在生成 Scrapy 项目中已经为我们准备好了一个 middleware.py 文件,我们按照上面的思路来完成相应代码,具体内容如下:
import time
from scrapy import signals
from scrapy.http.response.html import HtmlResponse
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
options = webdriver.ChromeOptions()
# 注意,使用这个参数我们就不会看到启动的google浏览器,无界面运行
options.add_argument('-headless')
options.add_experimental_option("excludeSwitches", ['enable-automation'])
class JdBooksSpiderMiddleware:
# 保持不变
# ...
class JdBooksDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def __init__(self):
self.driver = webdriver.Chrome(options=options, executable_path="C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe")
# ...
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print('使用 selenium 请求页面:{}'.format(request.url))
if request.url.startswith("https://search.jd.com/Search"):
# 如果是获取京东图书数据的请求,使用selenium方式获取页面
self.driver.get(request.url)
time.sleep(2)
# 将滚动条拖到最底端,获取一页完整的60条数据
height = self.driver.execute_script("return document.body.scrollHeight;")
self.driver.execute_script(f"window.scrollBy(0, {height})")
time.sleep(2)
# 将最后渲染得到的页面源码作为响应返回
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8', status=200)
# ...
紧接着,我们需要将这个下载中间件在 settings.py 中启用:
DOWNLOADER_MIDDLEWARES = {
'jd_books.middlewares.JdBooksDownloaderMiddleware': 543,
}
最后我们来完成下数据的存储,继续使用 mongodb 来保存抓取到的数据。从实际测试中发现京东的搜索结果在100页中肯定会有不少重复的数据。因此我们的 item pipelines 需要完成2个处理,分别是去重和保存。来直接看代码:
import pymongo
from scrapy.exceptions import DropItem
from itemadapter import ItemAdapter
class JdBooksPipeline:
def open_spider(self, spider):
self.client = pymongo.MongoClient(host='47.115.61.209', port=27017)
self.client.admin.authenticate("admin", "shencong1992")
db = self.client.scrapy_manual
self.collection = db.jd_books
def process_item(self, item, spider):
try:
book_info = {
'book_name': item['book_name'],
'comments': item['comments'],
'book_detail_url': item['book_detail_url'],
'shop_name': item['shop_name'],
'price': item['price'],
}
self.collection.insert_one(book_info)
except Exception as e:
print("插入数据异常:{}".format(str(e)))
return item
def close_spider(self, spider):
self.client.close()
class DuplicatePipeline:
"""
去除重复的数据,重复数据直接抛出异常,不会进入下一个流水线处理
"""
def __init__(self):
self.book_url_set = set()
def process_item(self, item, spider):
if item['book_detail_url'] in self.book_url_set:
print('重复搜索结果:book={}, url={}'.format(item['book_name'], item['book_detail_url']))
raise DropItem('duplicate book info, drop it')
self.book_url_set.add(item['book_detail_url'])
return item
我们直接使用 Item 的 book_detail_url 字段来判断数据是否重复。此外,同样需要将这两个 Item Pipelines 在 settings.py 中启用,且保证 DuplicatePipeline 需要先于 JdBooksPipeline 处理:
ITEM_PIPELINES = {
'jd_books.pipelines.DuplicatePipeline': 200,
'jd_books.pipelines.JdBooksPipeline': 300,
}
最后剩下一步就是禁止遵守 Robot 协议:
ROBOTSTXT_OBEY = True
至此,我们的 Scrapy 和 Selenium 结合爬取京东图书数据的项目就算完成了。为了快速演示效果,我们将最大请求页设置为10,然后运行代码看看实际的爬取效果:
3. 小结
本小节中我们使用 scrapy 和 selenium 结合完成了一个京东图书的爬取案例,从这个案例中我们能看到了 Scrapy 强大的第三方结合能力,包括前面的 Splash 服务。
4. 参考文献
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出