Scrapy 的分布式实现
今天我们简单介绍下 Scrapy 的分布式实现框架:Scrapy-Redis 并基于该插件完成一个简单的分布式爬虫案例。
1. 一个简单的分布式爬虫案例
我们以前面的第16讲的头条热点新闻爬虫基础,使用 scrapy-redis 插件进行改造,使之支持分布式爬取。现在我们按照如下的步骤进行。
环境准备。由于条件限制,我们只有2台云主机,分别命名为 server 和 server2。两台主机的用途如下:
| 主机 | 服务 | 公网 ip |
|---|---|---|
| server | scrapy爬虫 | 180.76.152.113 |
| server2 | scrapy爬虫、redis服务 | 47.115.61.209 |
先准备好 redis 服务,redis 服务的搭建以及设置密码等步骤在第一部分中已经介绍过了,这里就不再重复介绍了;
[root@server ~]# redis-cli -h 47.115.61.209 -p 6777
47.115.61.209:6777> auth spyinx
OK
47.115.61.209:6777> get hello
"new world"
我们在 server 和 server2 上都进行测试,确保都能连上 server2 上的 redis 服务。
安装 scrapy 和 scrapy-redis;
[root@server2 ~]# pip3 install scrapy scrapy-redis
# ...
改造 spider 代码,将原先继承的 Spider 类改为继承 scrapy-redis 插件中的 RedisSpider,同时去掉 start_requests() 方法:
# from scrapy import Request, Spider
from scrapy_redis.spiders import RedisSpider
# ...
class HotnewsSpider(RedisSpider):
# ...
# 注释start_requests()方法
# def start_requests(self):
# request_url = self._get_url(max_behot_time)
# self.logger.info(f"we get the request url : {request_url}")
# yield Request(request_url, headers=headers, cookies=cookies, callback=self.parse)
# ...
改造下原先的 pipelines.py 代码,为了能实时将数据保存到数据库中,我们挪动下 SQL 语句 commit 的位置,同时去掉原先的邮件发送功能:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import logging
from string import Template
from itemadapter import ItemAdapter
import pymysql
from toutiao_hotnews.mail import HtmlMailSender
from toutiao_hotnews.items import ToutiaoHotnewsItem
from toutiao_hotnews.html_template import hotnews_template_html
from toutiao_hotnews import settings
class ToutiaoHotnewsPipeline:
logger = logging.getLogger('pipelines_log')
def open_spider(self, spider):
# 初始化连接数据库
self.db = pymysql.connect(
host=spider.settings.get('MYSQL_HOST', 'localhost'),
user=spider.settings.get('MYSQL_USER', 'root'),
password=spider.settings.get('MYSQL_PASS', '123456'),
port=spider.settings.get('MYSQL_PORT', 3306),
db=spider.settings.get('MYSQL_DB_NAME', 'mysql'),
charset='utf8'
)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
# 插入sql语句
sql = "insert into toutiao_hotnews(title, abstract, source, source_url, comments_count, behot_time) values (%s, %s, %s, %s, %s, %s)"
if item and isinstance(item, ToutiaoHotnewsItem):
self.cursor.execute(sql, (item['title'], item['abstract'], item['source'], item['source_url'], item['comments_count'], item['behot_time']))
# 将commit语句移动到这里
self.db.commit()
return item
def query_data(self, sql):
data = {}
try:
self.cursor.execute(sql)
data = self.cursor.fetchall()
except Exception as e:
logging.error('database operate error:{}'.format(str(e)))
self.db.rollback()
return data
def close_spider(self, spider):
self.cursor.close()
self.db.close()
接下来就是配置 settings.py 了,我们首先要设置好 UserAgent,这一步是所有爬虫必须的。另外,针对 scrapy-redis 插件,我们只需要设置 scrapy-redis 的调度器和去重过滤器以及 Redis 的连接配置即可。如果想要将抓取的结果保存到 Redis 中,需要在 ITEM_PIPELINES 值中添加 scrapy-redis 的 item pipeline 即可。这里我们相应的配置如下:
# ...
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
# ...
ITEM_PIPELINES = {
'toutiao_hotnews.pipelines.ToutiaoHotnewsPipeline': 300,
# 指定scrapy-redis的pipeline,将结果保存到redis中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# ...
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 设置连接 Redis 的 URL
REDIS_URL = 'redis://:spyinx@47.115.61.209:6777'
就这样简单改造后,一个支持分布式的爬虫就完成了。我们在每台云主机上上传该爬虫代码,然后在爬虫项目目录下执行 scrapy crawl hotnews 运行爬虫。此时,所有的爬虫都会处于等待状态,需要手动将起始的请求 URL 设置到 redis 的请求列表中,相应的 key 默认为 hotnews:start_urls。添加的 redis 命令为:
> lpush hotnews:start_urls url
为此我准备了一段 python 代码帮助我们完成 url 的生成以及推送到 redis 中:
# 位置: 在 toutiao_hotnews 目录下,和 scrapy.cfg 文件同一级
import redis
from toutiao_hotnews.spiders.hotnews import HotnewsSpider
spider = HotnewsSpider()
r = redis.Redis(host='47.115.61.209', port=6777, password='spyinx', db=0)
request_url = spider._get_url(0)
r.lpush("hotnews:start_urls", request_url)
接下来,我们看看这个分布式爬虫的运行效果:
上面的视频中,我们启动了两个 scrapy 爬虫,他们分别监听 redis 中的 hotnews:start_urls 列表,当里面有数据时其中一个爬虫便会读取该 url 然后开始爬取动作;后面我们停止其中一个爬虫时,继续向 redis 中添加一个请求的 url 则另一个 scrapy 爬虫也会继续正常工作。 由于我们添加了两个 item pipeline,其中第一个会将 item 数据保存到数据库中,scrapy_redis 的 item pipeline 则会将抓取的 item 结果保存到 redis 中,对应的 key 名为 hotnews:items。
在对 scrapy-redis 插件有了一定的了解后,我们来分析一下 scrapy-redis 的源码并解释下上述工程的执行流程。
2. Scrapy-Redis 源码分析
我们从 github 上可以找到 scrapy-redis 插件的源码。它的代码少而精,但是简单的扩展就能使得 scrapy 框架具备分布式功能,因此它在 github 上也收获了不少赞。我们下载其源码来一窥其内部原理:
我们会从一开始继承的 RedisSpider 类开始学起,并逐步深入源码学习。
2.1 scrapy-redis 中的 RedisSpider 类分析
来看 RedisSpider 类的定义,它位于源码的 spider.py 文件中:
# 源码位置:scrapy_redis/spider.py
# ...
class RedisSpider(RedisMixin, Spider):
"""Spider that reads urls from redis queue when idle.
Attributes
----------
redis_key : str (default: REDIS_START_URLS_KEY)
Redis key where to fetch start URLs from..
redis_batch_size : int (default: CONCURRENT_REQUESTS)
Number of messages to fetch from redis on each attempt.
redis_encoding : str (default: REDIS_ENCODING)
Encoding to use when decoding messages from redis queue.
Settings
--------
REDIS_START_URLS_KEY : str (default: "<spider.name>:start_urls")
Default Redis key where to fetch start URLs from..
REDIS_START_URLS_BATCH_SIZE : int (deprecated by CONCURRENT_REQUESTS)
Default number of messages to fetch from redis on each attempt.
REDIS_START_URLS_AS_SET : bool (default: False)
Use SET operations to retrieve messages from the redis queue. If False,
the messages are retrieve using the LPOP command.
REDIS_ENCODING : str (default: "utf-8")
Default encoding to use when decoding messages from redis queue.
"""
@classmethod
def from_crawler(self, crawler, *args, **kwargs):
obj = super(RedisSpider, self).from_crawler(crawler, *args, **kwargs)
# 设置redis相关信息
obj.setup_redis(crawler)
return obj
# ...
源码中关于该类的说明已经非常清楚了,我们简单翻一下就是:空闲时从 redis 队列中读取 urls 的 spider。来关注 from_crawler() 方法的第二个语句:setup_redis(),其实现代码如下:
class RedisMixin(object):
"""Mixin class to implement reading urls from a redis queue."""
redis_key = None
redis_batch_size = None
redis_encoding = None
# Redis client placeholder.
server = None
def start_requests(self):
"""Returns a batch of start requests from redis."""
return self.next_requests()
def setup_redis(self, crawler=None):
"""Setup redis connection and idle signal.
This should be called after the spider has set its crawler object.
"""
if self.server is not None:
return
if crawler is None:
# We allow optional crawler argument to keep backwards
# compatibility.
# XXX: Raise a deprecation warning.
crawler = getattr(self, 'crawler', None)
if crawler is None:
raise ValueError("crawler is required")
settings = crawler.settings
# 设置redis_key属性值,如果settings.py中没有设置,就会使用默认的key值
if self.redis_key is None:
self.redis_key = settings.get(
'REDIS_START_URLS_KEY', defaults.START_URLS_KEY,
)
self.redis_key = self.redis_key % {'name': self.name}
# 确保redis_key值不为空
if not self.redis_key.strip():
raise ValueError("redis_key must not be empty")
# 获取redis_batch_size的值,并转成int类型
if self.redis_batch_size is None:
# TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE).
self.redis_batch_size = settings.getint(
'REDIS_START_URLS_BATCH_SIZE',
settings.getint('CONCURRENT_REQUESTS'),
)
try:
self.redis_batch_size = int(self.redis_batch_size)
except (TypeError, ValueError):
raise ValueError("redis_batch_size must be an integer")
# 获取redis_batch_size值
if self.redis_encoding is None:
self.redis_encoding = settings.get('REDIS_ENCODING', defaults.REDIS_ENCODING)
self.logger.info("Reading start URLs from redis key '%(redis_key)s' "
"(batch size: %(redis_batch_size)s, encoding: %(redis_encoding)s",
self.__dict__)
# 获取server属性,即redis的连接
self.server = connection.from_settings(crawler.settings)
# The idle signal is called when the spider has no requests left,
# that's when we will schedule new requests from redis queue
crawler.signals.connect(self.spider_idle, signal=signals.spider_idle)
def next_requests(self):
"""Returns a request to be scheduled or none."""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
# TODO: Use redis pipeline execution.
while found < self.redis_batch_size:
data = fetch_one(self.redis_key)
if not data:
# Queue empty.
break
req = self.make_request_from_data(data)
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis.
By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding.
Parameters
----------
data : bytes
Message from redis.
"""
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
def schedule_next_requests(self):
"""Schedules a request if available"""
# TODO: While there is capacity, schedule a batch of redis requests.
for req in self.next_requests():
self.crawler.engine.crawl(req, spider=self)
def spider_idle(self):
"""Schedules a request if available, otherwise waits."""
# XXX: Handle a sentinel to close the spider.
self.schedule_next_requests()
raise DontCloseSpider
上面的代码比较简单,也十分容易看懂。关于 setup_redis() 方法:该方法主要是设置 redis 相关信息,同时连接 redis 并得到连接属性 self.server 值;从该方法中我们可以看到在 settings.py 中我们可以设置如下几个参数:
-
REDIS_START_URLS_KEY:设置起始 urls 的 key,前面我们知道没有设置是,默认的 key 是
爬虫名:start_urls,这在代码中也有所体现;if self.redis_key is None: self.redis_key = settings.get( 'REDIS_START_URLS_KEY', defaults.START_URLS_KEY, ) # default.py中有START_URLS_KEY = '%(name)s:start_urls' self.redis_key = self.redis_key % {'name': self.name} -
REDIS_START_URLS_BATCH_SIZE:已经移除了;
-
REDIS_ENCODING: 设置 redis 中的编码类型;
-
REDIS 的相关配置,主要在如下的语句中读取:
self.server = connection.from_settings(crawler.settings)我们来跟踪下这个
connection.from_settings()的代码,位于 connection.py 中:# 源码位置:scrapy_redis/connection.py import six from scrapy.utils.misc import load_object from . import defaults # 重要的映射关系,对应着settings.py的 SETTINGS_PARAMS_MAP = { 'REDIS_URL': 'url', 'REDIS_HOST': 'host', 'REDIS_PORT': 'port', 'REDIS_ENCODING': 'encoding', } def get_redis_from_settings(settings): params = defaults.REDIS_PARAMS.copy() params.update(settings.getdict('REDIS_PARAMS')) # XXX: Deprecate REDIS_* settings. for source, dest in SETTINGS_PARAMS_MAP.items(): val = settings.get(source) if val: params[dest] = val # Allow ``redis_cls`` to be a path to a class. if isinstance(params.get('redis_cls'), six.string_types): params['redis_cls'] = load_object(params['redis_cls']) return get_redis(**params) # Backwards compatible alias. from_settings = get_redis_from_settings def get_redis(**kwargs): # 默认使用defaults.REDIS_CLS,也就是redis.StrictRedis redis_cls = kwargs.pop('redis_cls', defaults.REDIS_CLS) url = kwargs.pop('url', None) if url: return redis_cls.from_url(url, **kwargs) else: return redis_cls(**kwargs)
上面的代码非常简单,get_redis_from_settings() 方法会从 settings.py 中读取 REDIS_URL 、REDIS_HOST 、REDIS_PORT 等参数,另外还会额外读取 REDIS_PARAMS 。优先使用 REDIS_URL 配置信息,来看看最核心的建立客户端连接实例的代码:
if url:
return redis_cls.from_url(url, **kwargs)
else:
return redis_cls(**kwargs)
这里的 redis_cls 正是第三方模块类 redis.StrictRedis,当然我们也可以通过覆盖 default.py 中的 REDIS_PARAMS 参数中的 redis_cls 来选择新的操作 redis 的第三方模块。
紧接着,我们注意到前面在改造 Scrapy 爬虫时去掉了 start_requests() 这个方法。在启动 scrapy 爬虫后,爬虫会等到 redis 的 urls 队列中出现相应的起始 url 值,然后获取该 url 开始数据爬取。我们来看看这个过程是如何实现的?
RedisSpider 类继承了 RedisMixin 这个 mixin,它是 scrapy-redis 插件爬虫需要单独实现的功能类。该 Mixin 中正好实现了 start_requests() 方法,具体代码如下:
# 源码位置:scrapy_redis/spiders.py
# ...
class RedisMixin(object):
# ...
def start_requests(self):
"""Returns a batch of start requests from redis."""
return self.next_requests()
# ...
def next_requests(self):
"""Returns a request to be scheduled or none."""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
# TODO: Use redis pipeline execution.
while found < self.redis_batch_size:
data = fetch_one(self.redis_key)
if not data:
# Queue empty.
break
req = self.make_request_from_data(data)
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
# ...
我们没有设置 REDIS_START_URLS_AS_SET 值,所以默认使用 Redis 的列表类型。因此 fetch_one 方法就是 self.server.lpop,对应就是 Redis 中的 lpop (左弹出) 方法。我们的 URL 是使用 lpush 进去了,获取该结果默认使用的是 lpop,因此我们知道先 push 进去的 url 元素就会后 pop 弹出并执行。另外,我们看到,如果 redis 中对应的 urls 队列中存在一个 url 元素后,执行如下操作:
req = self.make_request_from_data(data)
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
来继续看 self.make_request_from_data() 这个方法:
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
这个 self.make_requests_from_url() 方法其实调用的是 scrapy 模块中的 spider 类中的方法:
# 源码位置:scrapy/spiders/__init__.py
# ...
class Spider(object_ref):
# ...
def make_requests_from_url(self, url):
""" This method is deprecated. """
warnings.warn(
"Spider.make_requests_from_url method is deprecated: "
"it will be removed and not be called by the default "
"Spider.start_requests method in future Scrapy releases. "
"Please override Spider.start_requests method instead."
)
return Request(url, dont_filter=True)
最终我们发现在 scrapy-redis 插件中,它的 RedisSpider 类也有默认的 start_requests() 方法,该方法从 redis 中指定的队列中取出 urls 并封装成 Scrapy 中的 Request 请求并 yield 给 Scrapy 的调度器去调度处理。
2.2 scrapy-redis 中的请求队列
接下来我们来看看 scrapy-redis 在对 scrapy 框架对请求队列做的一些改动。Scrapy 原生的请求队列是存储在内存中的,这样必然无法实现分布式功能。scrapy-redis 插件将这个请求队列改造成基于 redis 数据库的,通过这个 redis 数据库,实现了三种请求队列:
- 优先级队列 (默认):PriorityQueue;
- 先进先出队列:FifoQueue;
- 后进先出队列:LifoQueue;
有了这个基于 Redis 数据库的队列后,所有的 Scrapy 爬虫就能共享这一请求队列,实现分布式协作的功能。对于请求队列,主要的功能是入队 (push) 和出队 (pop)。这部分的代码位于 scrapy_redis/queue.py 文件中,有兴趣可以仔细阅读三个队列的入队和出队的实现。
2.3 scrapy-redis 中的去重过滤器
scrapy-redis 插件内部实现了一个去重过滤器,同样基于 Redis 数据库。原生的 Scrapy 的去重功能是基于内存的集合实现,并不适合分布式的。scrapy-redis 通过 Redis 来实现数据共享,利用 Redis 的集合类型来实现 元素的去重,其代码位于 scrapy_redis/dupefilter.py 文件中。我们可以看看其去重的最核心方法:
# 源码位置:scrapy_redis/dupefilter.py
# ...
class RFPDupeFilter(BaseDupeFilter):
# ...
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)
# ...
从代码可知,请求会存入到 Redis 的集合中,从而实现去重功能,是不是非常简单?
2.4 scrapy-redis 中的调度器
回忆我们的 scrapy 框架中调度器的功能:接收 scrapy 引擎传过来的请求 (入队),然后从队列中选出一个请求 (出队) 发送给引擎去执行下载。此时我们的请求队列是在 Redis 中的,不能想象,这里 scrapy-redis 插件也是需要对 scrapy 的调度器模块进行略微的调整,主要改造调度请求的入队和出队过程。此外,调度器还具备去重功能,因此这里也会使用前面改造的去重过滤器来实现对请求的去重。具体代码如下:
# 源码位置:scrapy_redis/scheduler.py
# ...
class Scheduler(object):
# ...
# 请求入队
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
# 请求出队
def next_request(self):
block_pop_timeout = self.idle_before_close
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
# ...
我们看到这里 scrapy-redis 实现的调度器模块,其请求入队操作过程为:
- 先判断是否需要去重,如果需要则使用 scrapy-redis 实现的去重过滤器进行判断;
- 判断是否需要统计;
- 使用 scrapy-redis 中基于 redis 实现的请求队列进行入队操作;
出队操作则是调用 scrapy-redis 中实现的请求队列进行出队 (pop() 方法)。scrapy-redis 中调度器的核心步骤就是这两步,大家看懂了吗?
2.5 scrapy-redis 中的 Item Pipeline
最后我们来看 scrapy-redis 中定义的 item pipeline。前面我们在头条新闻爬虫的改造中只是在配置中添加了 scrapy-redis 中的 item pipeline,这样爬虫抓取的结果会保存到 redis 中,那么该 pipeline 是如何实现的呢?其代码位于 scrapy_redis/pipelines.py 文件中,我们来一览究竟:
# 源码位置:scrapy_redis/pipelines.py
# ...
class RedisPipeline(object):
def __init__(self, server,
key=defaults.PIPELINE_KEY,
serialize_func=default_serialize):
"""Initialize pipeline.
Parameters
----------
server : StrictRedis
Redis client instance.
key : str
Redis key where to store items.
serialize_func : callable
Items serializer function.
"""
self.server = server
self.key = key
self.serialize = serialize_func
@classmethod
def from_settings(cls, settings):
params = {
'server': connection.from_settings(settings),
}
if settings.get('REDIS_ITEMS_KEY'):
params['key'] = settings['REDIS_ITEMS_KEY']
if settings.get('REDIS_ITEMS_SERIALIZER'):
params['serialize_func'] = load_object(
settings['REDIS_ITEMS_SERIALIZER']
)
return cls(**params)
@classmethod
def from_crawler(cls, crawler):
return cls.from_settings(crawler.settings)
def process_item(self, item, spider):
return deferToThread(self._process_item, item, spider)
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item
def item_key(self, item, spider):
"""Returns redis key based on given spider.
Override this function to use a different key depending on the item
and/or spider.
"""
return self.key % {'spider': spider.name}
这段代码也是简洁明了,首先是初始化三个属性值:
server:redis 客户端实例,用于对 redis 进行操作;key:结果保存到 redis 中的 key 名;serialize:指定结果序列化类;
作为 scrapy 中的 pipeline,最核心的处理函数就是 process_item() 方法。在该 pipeline 中,该方法只有一条语句:
deferToThread(self._process_item, item, spider)
deferToThread() 方法是 Twisted 框架提供的一个方法,其含义如下:
Run a function in a thread and return the result as a Deferred
其实就是开启一个线程执行相应的方法,并将结果作为一个 Deferred 返回。我们并不关心这个 Deferred 是啥,在最后一部分源码篇中会介绍到,这里我们只关心处理 item 的操作是 self._process_item() 这个方法。该方法的逻辑非常简单明了:
- 生成保存到 Redis 中的 key;
- 将 item 值序列化以便能保存到 Redis 中;
- 调用 redis 的
rpush()方法将序列化结果保存到相应列表中;
看完了 scrapy-redis 中 RedisPipeline 的代码,是不是知道为什么结果会保存到 redis 中了吧?就这样,我们几乎学完了 scrapy-redis 插件的全部源码,下来我们来看一看 scrapy-redis 插件的架构图,进一步理解该插件:
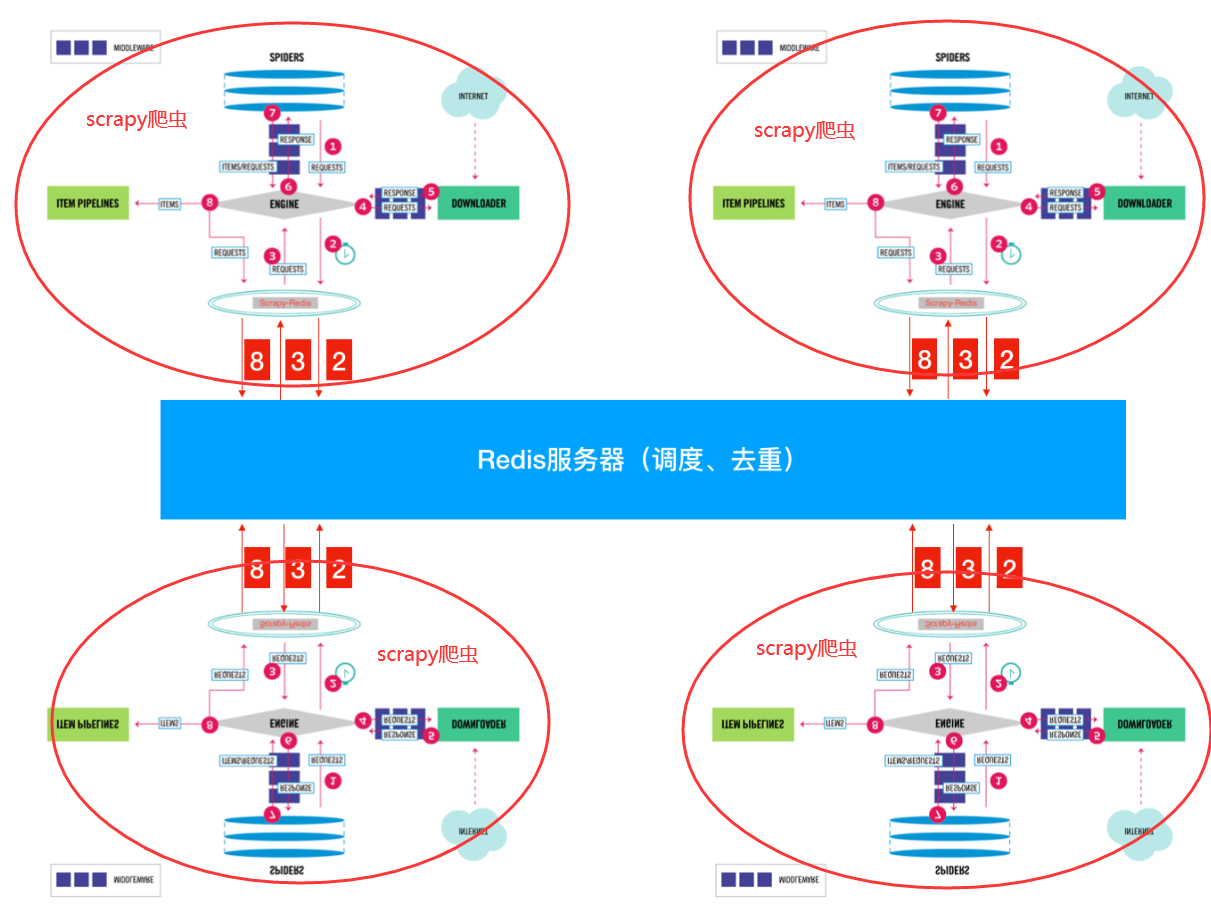
3. 小结
本小节中我们改造了前面的爬取头条热点新闻的代码,将其改造成一个分布式的爬虫。接下来我们分析了 Scrapy-Redis 插件的源码,对该插件的内部原理有了深刻的了解。
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出