Scrapy 抓取今日头条:抓取每日热点新闻
今天我们来基于 Scrapy 框架完成一个新闻数据抓取爬虫,本小节中我们将进一步学习 Scrapy 框架的,来抓取异步 ajax 请求的数据,同时学习 Scrapy 的日志配置、邮件发送等功能。
1. 今日头条热点新闻数据抓取分析
今天的爬取对象是今日头条的热点新闻,下面的视频演示了如何找到头条新闻网站在获取热点新闻的 HTTP 请求:
从视频中我们可以看到头条新闻获取网站的接口示例如下:
https://www.toutiao.com/api/pc/feed/?category=news_hot&utm_source=toutiao&widen=1&max_behot_time=1597152177&max_behot_time_tmp=1597152177&tadrequire=true&as=A1955F33D209BD8&cp=5F32293B3DE80E1&_signature=_02B4Z6wo0090109cl1gAAIBCcqbHy0H-dDdPWZPAAIzuFTZSh6NBsUuEpf13PktqrmxS-ZD4dEDZ6Ezcpyjo31hg62slsekkigwdRlS0FHfPsOvx.KRyeJBdEf5QI8nLcwEMyziL1YdPK6VD8f
像这样的 http 请求时比较难模拟的,我们需要知道请求中所有参数的获取规则,特别是一些进行加密的方式,需要从前端中找出来并手工实现。比如这里的 URL,前几个参数都是固定值,其中 as、cp 和 _signature 则非常难获取,需要有极强的前端功底,网上也有大神对这些值的生成进行了分析和解密,当然这些不是我们学习的重点。
最后一个问题:一次请求得到10条左右的新闻数据,那么像实现视频中那样更新更多新闻的请求,该如何完成呢?仔细分析下连续的刷新请求,我们会发现上述的 URL 请求结果中有这样一个参数:max_behot_time。
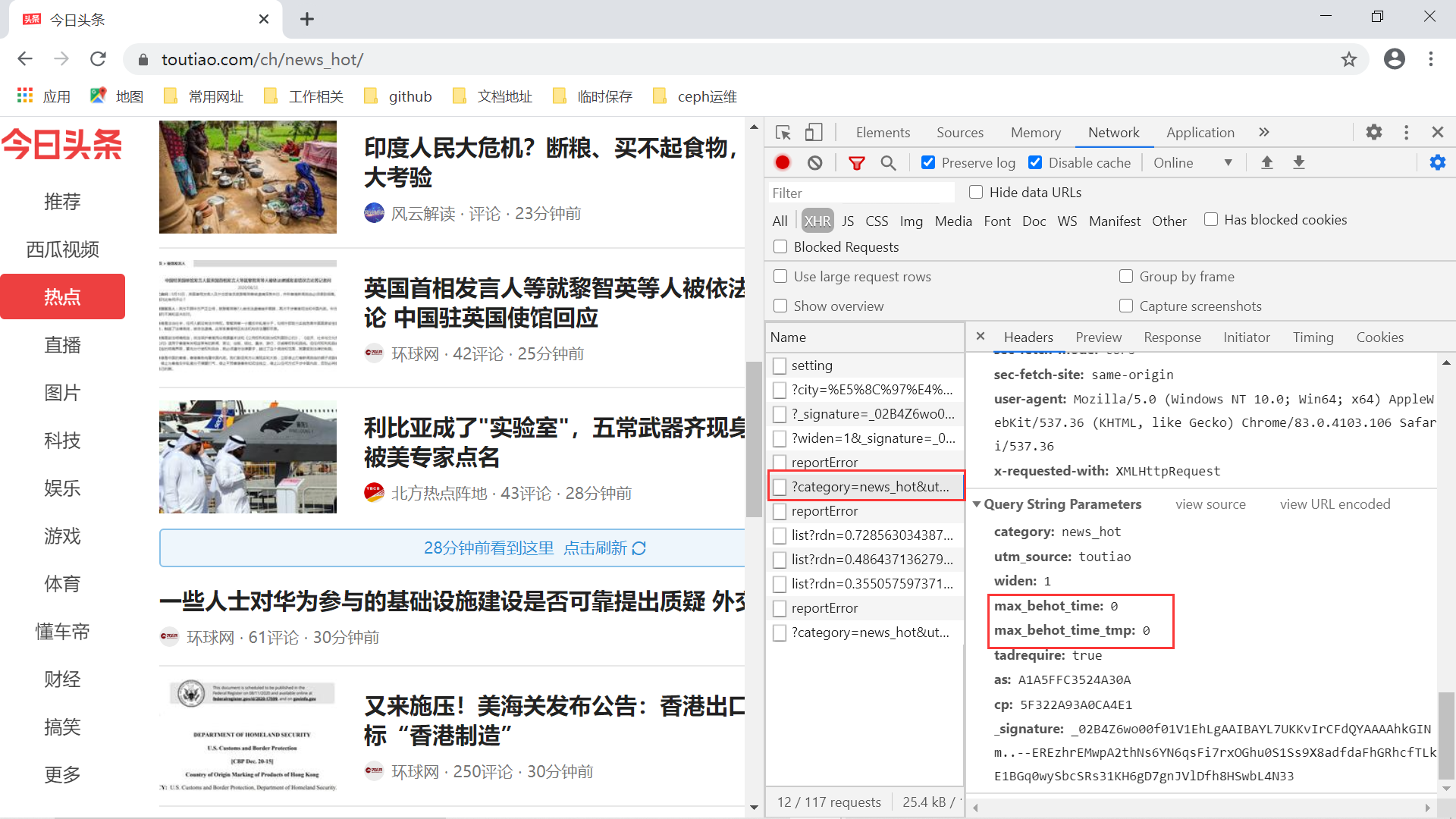
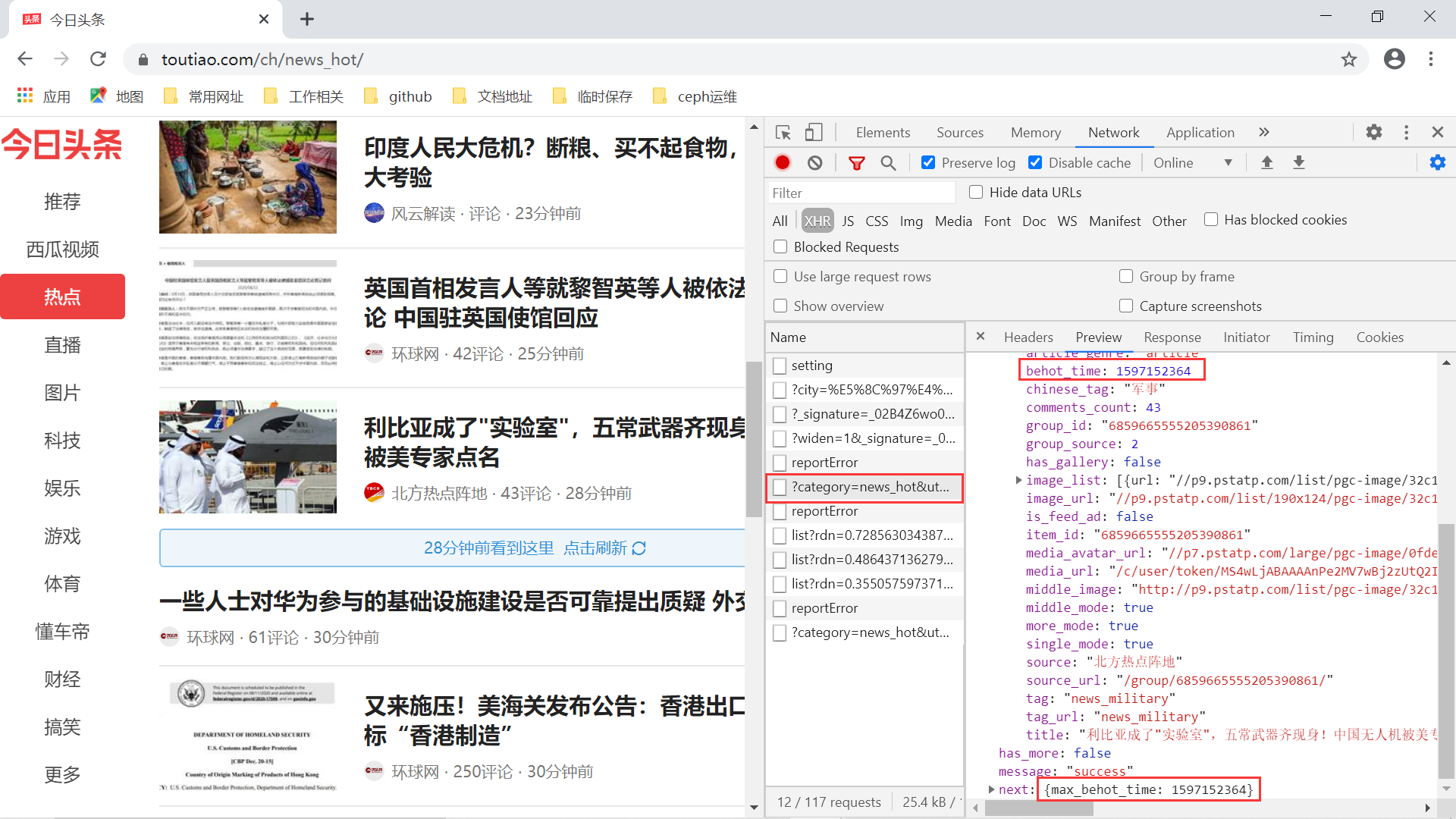
关于这个参数,我们得到两条信息:
- 第一次请求热点新闻数据时,该参数为0;
- 接下来的每次请求,带上的
max_behot_time值为上一次请求热点新闻数据结果中的 next 字段中的max_behot_time键对应的值。它表示的是一个时间戳,其实就是意味着请求的热点新闻数据需要在这个时间之后;
有了这样的信息,我们来基于 requests 库,纯手工实现一把头条热点新闻数据的抓取。我们按照如下的步骤来完成爬虫代码:
-
准备基本变量,包括请求的基本 URL、请求参数、请求头等;
hotnews_url = "https://www.toutiao.com/api/pc/feed/?" params = { 'category': 'news_hot', 'utm_source': 'toutiao', 'widen': 1, 'max_behot_time': '', 'max_behot_time_tmp': '', } headers = { 'referer': 'https://www.toutiao.com/ch/news_hot/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36' } cookies = {'tt_webid':'6856365980324382215'} max_behot_time = '0'注意:上面的 cookies 中的
tt_webid字段值可以通过右键看到,不过用处不大。
tt_webid值的获取 -
准备三个个方法:
get_request_data()、get_as_cp()和save_to_json()。其中第二个函数是网上有人对头条的 js 生成 as 和 cp 参数的代码进行了翻译,目前看来似乎还能使用;def get_request_data(url, headers): response = requests.get(url=url, headers=headers) return json.loads(response.text) def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js zz = {} now = round(time.time()) e = hex(int(now)).upper()[2:] a = hashlib.md5() a.update(str(int(now)).encode('utf-8')) i = a.hexdigest().upper() if len(e) != 8: zz = {'as':'479BB4B7254C150', 'cp':'7E0AC8874BB0985'} return zz n = i[:5] a = i[-5:] r = '' s = '' for i in range(5): s = s + n[i] + e[i] for j in range(5): r = r + e[j + 3] + a[j] zz ={ 'as': 'A1' + s + e[-3:], 'cp': e[0:3] + r + 'E1' } return zz def save_to_json(datas, file_path, key_list): """ 保存 json 数据 """ print('写入数据到文件{}中,共计{}条新闻数据!'.format(file_path, len(datas))) with codecs.open(file_path, 'a+', 'utf-8') as f: for d in datas: cleaned_data = {} for key in key_list: if key in d: cleaned_data[key] = d[key] print(json.dumps(cleaned_data, ensure_ascii=False)) f.write("{}\n".format(json.dumps(cleaned_data, ensure_ascii=False))) -
最后一步就是实现模拟刷新请求数据。下一次的请求会使用上一次请求结果中的
max_behot_time值,这样能连续获取热点新闻数据,模拟头条页面向下的刷新过程;# 模拟向下下刷新5次获取新闻数据 refresh_count = 5 for _ in range(refresh_count): new_params = copy.deepcopy(params) zz = get_as_cp() new_params['as'] = zz['as'] new_params['cp'] = zz['cp'] new_params['max_behot_time'] = max_behot_time new_params['max_behot_time_tmp'] = max_behot_time request_url = "{}{}".format(hotnews_url, urlencode(new_params)) print(f'本次请求max_behot_time = {max_behot_time}') datas = get_request_data(request_url, headers=headers, cookies=cookies) max_behot_time = datas['next']['max_behot_time'] save_to_json(datas['data'], "result.json", key_list) time.sleep(2)

最后来看看完整抓取热点新闻数据的代码运行过程,如下:
2. 基于 Scrapy 框架的头条热点新闻数据爬取
还是按照我们以前的套路来进行,第一步是使用 startproject 命令创建热点新闻项目:
[root@server ~]# cd scrapy-test/
[root@server scrapy-test]# pyenv activate scrapy-test
pyenv-virtualenv: prompt changing will be removed from future release. configure `export PYENV_VIRTUALENV_DISABLE_PROMPT=1' to simulate the behavior.
(scrapy-test) [root@server scrapy-test]# scrapy startproject toutiao_hotnews
New Scrapy project 'toutiao_hotnews', using template directory '/root/.pyenv/versions/3.8.1/envs/scrapy-test/lib/python3.8/site-packages/scrapy/templates/project', created in:
/root/scrapy-test/toutiao_hotnews
You can start your first spider with:
cd toutiao_hotnews
scrapy genspider example example.com
(scrapy-test) [root@server scrapy-test]#
接着,根据我们要抓取的新闻数据字段,先定义好 Item:
import scrapy
class ToutiaoHotnewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
abstract = scrapy.Field()
source = scrapy.Field()
source_url = scrapy.Field()
comments_count = scrapy.Field()
behot_time = scrapy.Field()
有了 Item 之后,我们需要新建一个 Spider,可以使用 genspider 命令生成,也可以手工编写一个 Python 文件,代码内容如下:
# 代码位置:toutiao_hotnews/toutiao_hotnews/spiders/hotnews.py
import copy
import hashlib
from urllib.parse import urlencode
import json
import time
from scrapy import Request, Spider
from toutiao_hotnews.items import ToutiaoHotnewsItem
hotnews_url = "https://www.toutiao.com/api/pc/feed/?"
params = {
'category': 'news_hot',
'utm_source': 'toutiao',
'widen': 1,
'max_behot_time': '',
'max_behot_time_tmp': '',
'as': '',
'cp': ''
}
headers = {
'referer': 'https://www.toutiao.com/ch/news_hot/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}
cookies = {'tt_webid':'6856365980324382215'}
max_behot_time = '0'
def get_as_cp():
# 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
e = hex(int(now)).upper()[2:]
a = hashlib.md5()
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
if len(e) != 8:
zz = {'as':'479BB4B7254C150',
'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s = s + n[i] + e[i]
for j in range(5):
r = r + e[j + 3] + a[j]
zz ={
'as': 'A1' + s + e[-3:],
'cp': e[0:3] + r + 'E1'
}
return zz
class HotnewsSpider(Spider):
name = 'hotnews'
allowed_domains = ['www.toutiao.com']
start_urls = ['http://www.toutiao.com/']
# 记录次数,注意停止
count = 0
def _get_url(self, max_behot_time):
new_params = copy.deepcopy(params)
zz = get_as_cp()
new_params['as'] = zz['as']
new_params['cp'] = zz['cp']
new_params['max_behot_time'] = max_behot_time
new_params['max_behot_time_tmp'] = max_behot_time
return "{}{}".format(hotnews_url, urlencode(new_params))
def start_requests(self):
"""
第一次爬取
"""
request_url = self._get_url(max_behot_time)
self.logger.info(f"we get the request url : {request_url}")
yield Request(request_url, headers=headers, cookies=cookies, callback=self.parse)
def parse(self, response):
"""
根据得到的结果得到获取下一次请求的结果
"""
self.count += 1
datas = json.loads(response.text)
data = datas['data']
for d in data:
item = ToutiaoHotnewsItem()
item['title'] = d['title']
item['abstract'] = d.get('abstract', '')
item['source'] = d['source']
item['source_url'] = d['source_url']
item['comments_count'] = d.get('comments_count', 0)
item['behot_time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(d['behot_time']))
self.logger.info(f'得到的item={item}')
yield item
if self.count < self.settings['REFRESH_COUNT']:
max_behot_time = datas['next']['max_behot_time']
self.logger.info("we get the next max_behot_time: {}, and the count is {}".format(max_behot_time, self.count))
yield Request(self._get_url(max_behot_time), headers=headers, cookies=cookies)
这里的代码之前一样,第一次构造 Request 请求在 start_requests() 方法中,接下来在根据每次请求结果中获取 max_behot_time 值再进行下一次请求。另外我使用了全局计算变量 count 来模拟刷新的次数,控制请求热点新闻次数,防止无限请求下去。此外,Scrapy logger 在每个 spider 实例中提供了一个可以访问和使用的实例,我们再需要打印日志的地方直接使用 self.logger 即可,它对应日志的配置如下:
# 代码位置:toutiao_hotnews/settings.py
# 注意设置下下载延时
DOWNLOAD_DELAY = 5
# ...
#是否启动日志记录,默认True
LOG_ENABLED = True
LOG_ENCODING = 'UTF-8'
#日志输出文件,如果为NONE,就打印到控制台
LOG_FILE = 'toutiao_hotnews.log'
#日志级别,默认DEBUG
LOG_LEVEL = 'INFO'
# 日志日期格式
LOG_DATEFORMAT = "%Y-%m-%d %H:%M:%S"
#日志标准输出,默认False,如果True所有标准输出都将写入日志中,比如代码中的print输出也会被写入到
LOG_STDOUT = False
接下来是 Item Pipelines 部分,这次我们将抓取到的新闻保存到 MySQL 数据库中。此外,我们还有一个需求就是选择当前最新的10条新闻发送到本人邮件,这样每天早上就能定时收到最新的头条新闻,岂不美哉。首先我想给自己的邮件发送 HTML 格式的数据,然后列出最新的10条新闻,因此第一步是是准备好模板热点新闻的模板页面,具体模板页面如下:
# 代码位置: toutiao_hotnews/html_template.py
hotnews_template_html = """
<!DOCTYPE html>
<html>
<head>
<title>头条热点新闻一览</title>
</head>
<style type="text/css">
</style>
<body>
<div class="container">
<h3 style="margin-bottom: 10px">头条热点新闻一览</h3>
$news_list
</div>
</body>
</html>
"""
要注意一点,Scrapy 的邮箱功能只能发送文本内容,不能发送 HTML 内容。为了能支持发送 HTML 内容,我继承了原先的 MailSender 类,并对原先的 send() 方法稍做改动:
# 代码位置: mail.py
import logging
from email import encoders as Encoders
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
from email.mime.nonmultipart import MIMENonMultipart
from email.mime.text import MIMEText
from email.utils import COMMASPACE, formatdate
from scrapy.mail import MailSender
from scrapy.utils.misc import arg_to_iter
logger = logging.getLogger(__name__)
class HtmlMailSender(MailSender):
def send(self, to, subject, body, cc=None, mimetype='text/plain', charset=None, _callback=None):
from twisted.internet import reactor
#####去掉了与attachs参数相关的判断语句,其余代码不变#############
msg = MIMEText(body, 'html', 'utf-8')
##########################################################
to = list(arg_to_iter(to))
cc = list(arg_to_iter(cc))
msg['From'] = self.mailfrom
msg['To'] = COMMASPACE.join(to)
msg['Date'] = formatdate(localtime=True)
msg['Subject'] = subject
rcpts = to[:]
if cc:
rcpts.extend(cc)
msg['Cc'] = COMMASPACE.join(cc)
if charset:
msg.set_charset(charset)
if _callback:
_callback(to=to, subject=subject, body=body, cc=cc, attach=attachs, msg=msg)
if self.debug:
logger.debug('Debug mail sent OK: To=%(mailto)s Cc=%(mailcc)s '
'Subject="%(mailsubject)s" Attachs=%(mailattachs)d',
{'mailto': to, 'mailcc': cc, 'mailsubject': subject,
'mailattachs': len(attachs)})
return
dfd = self._sendmail(rcpts, msg.as_string().encode(charset or 'utf-8'))
dfd.addCallbacks(
callback=self._sent_ok,
errback=self._sent_failed,
callbackArgs=[to, cc, subject, len(attachs)],
errbackArgs=[to, cc, subject, len(attachs)],
)
reactor.addSystemEventTrigger('before', 'shutdown', lambda: dfd)
return dfd
紧接着就是我们的 pipelines.py 文件中的代码:
import logging
from string import Template
from itemadapter import ItemAdapter
import pymysql
from toutiao_hotnews.mail import HtmlMailSender
from toutiao_hotnews.items import ToutiaoHotnewsItem
from toutiao_hotnews.html_template import hotnews_template_html
from toutiao_hotnews import settings
class ToutiaoHotnewsPipeline:
logger = logging.getLogger('pipelines_log')
def open_spider(self, spider):
# 使用自己的MailSender类
self.mailer = HtmlMailSender().from_settings(spider.settings)
# 初始化连接数据库
self.db = pymysql.connect(
host=spider.settings.get('MYSQL_HOST', 'localhost'),
user=spider.settings.get('MYSQL_USER', 'root'),
password=spider.settings.get('MYSQL_PASS', '123456'),
port=spider.settings.get('MYSQL_PORT', 3306),
db=spider.settings.get('MYSQL_DB_NAME', 'mysql'),
charset='utf8'
)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
# 插入sql语句
sql = "insert into toutiao_hotnews(title, abstract, source, source_url, comments_count, behot_time) values (%s, %s, %s, %s, %s, %s)"
if item and isinstance(item, ToutiaoHotnewsItem):
self.cursor.execute(sql, (item['title'], item['abstract'], item['source'], item['source_url'], item['comments_count'], item['behot_time']))
return item
def query_data(self, sql):
data = {}
try:
self.cursor.execute(sql)
data = self.cursor.fetchall()
except Exception as e:
logging.error('database operate error:{}'.format(str(e)))
self.db.rollback()
return data
def close_spider(self, spider):
sql = "select title, source_url, behot_time from toutiao_hotnews where 1=1 order by behot_time limit 10"
# 获取10条最新的热点新闻
data = self.query_data(sql)
news_list = ""
# 生成html文本主体
for i in range(len(data)):
news_list += "<div><span>{}、<a href=https://www.toutiao.com{}>{} [{}]</a></span></div>".format(i + 1, data[i][1], data[i][0], data[i][2])
msg_content = Template(hotnews_template_html).substitute({"news_list": news_list})
self.db.commit()
self.cursor.close()
self.db.close()
self.logger.info("最后统一发送邮件")
# 必须加return,不然会报错
return self.mailer.send(to=["2894577759@qq.com"], subject="这是一个测试", body=msg_content, cc=["2894577759@qq.com"])
这里我们会将 MySQL 的配置统一放到 settings.py 文件中,然后使用 spider.settings 来读取响应的信息。其中 open_spider() 方法用于初始化连接数据库,process_item() 方法用于生成 SQL 语句并提交插入动作,最后的 close_spider() 方法用于提交数据库执行动作、关闭数据库连接以及发送统一新闻热点邮件。下面是我们将这个 Pipeline 在 settings.py 中开启以及配置数据库信息、邮件服务器信息,同时也要注意关闭遵守 Robot 协议,这样爬虫才能正常执行。
ROBOTSTXT_OBEY = False
# 启动对应的pipeline
ITEM_PIPELINES = {
'toutiao_hotnews.pipelines.ToutiaoHotnewsPipeline': 300,
}
# 数据库配置
MYSQL_HOST = "180.76.152.113"
MYSQL_PORT = 9002
MYSQL_USER = "store"
MYSQL_PASS = "数据库密码"
MYSQL_DB_NAME = "ceph_check"
# 邮箱配置
MAIL_HOST = 'smtp.qq.com'
MAIL_PORT = 25
MAIL_FROM = '2894577759@qq.com'
MAIL_PASS = '你的授权码'
MAIL_USER = '2894577759@qq.com'
来看看我们这个头条新闻爬虫的爬取效果,视频演示如下:
3. 小结
本小节中我们继续带领大家完成一个 Scrapy 框架的实战案例,继续学习了 Scrapy 中关于日志的配置、邮件发送等功能。这一小节,大家有收获了吗?
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出