第一个基于 Scrapy 框架的爬虫
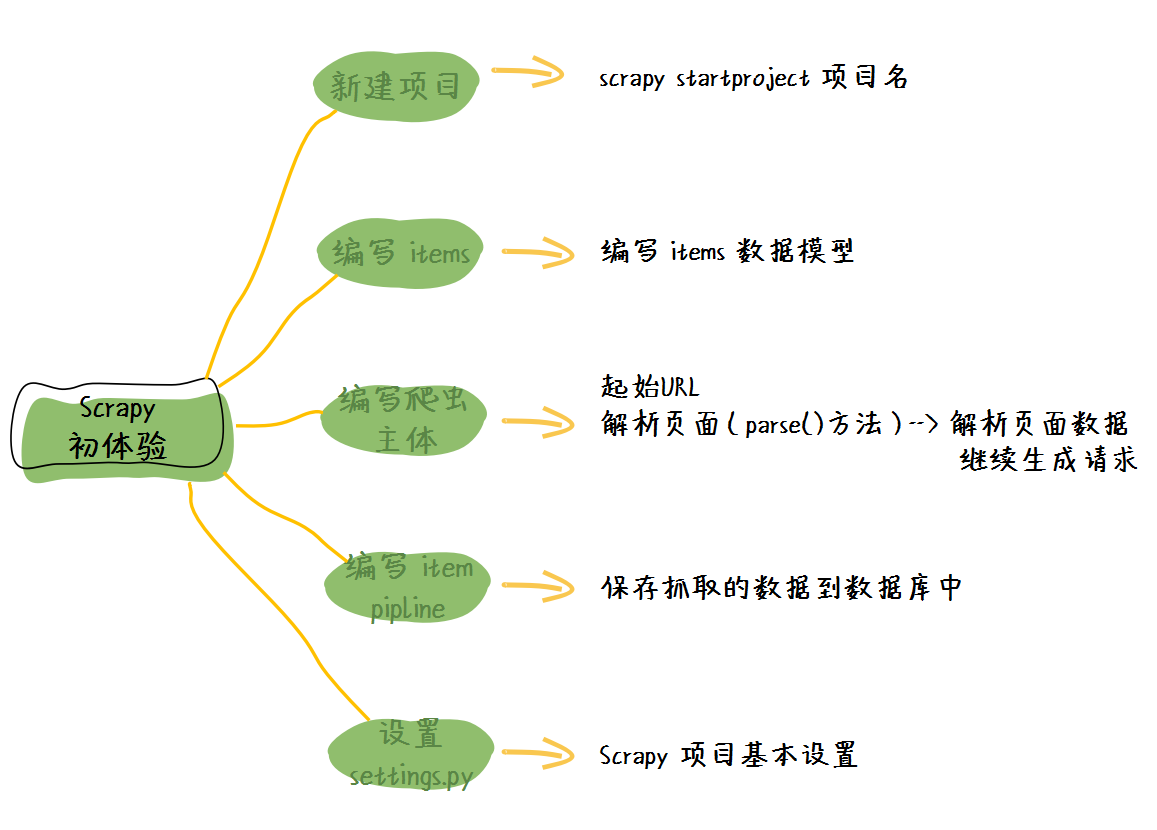
今天我们在上一节的基础上使用 Scrapy 框架来完成对互动出版网的计算机类书籍爬取。这里请跟着我们先熟悉一遍 Scrapy 框架的使用,至于细节后面会慢慢介绍到。
1. 新建 Scrapy 项目
Scrapy 框架和 Django 框架类似,先使用命令行来开启一个项目的最小工程。这里会创建 python 的虚拟环境,如果不熟悉 pyenv 工具的同学,可以参考这里的文章。
# 新建scray-test目录,后续会保存scrapy项目的相关代码
[root@server ~]# mkdir scrapy-test
[root@server ~]# cd scrapy-test/
# 安装scrapy的虚拟环境
[root@server scrapy-test]# pyenv virtualenv 3.8.1 scrapy-test
[root@server scrapy-test]# pyenv activate scrapy-test
pyenv-virtualenv: prompt changing will be removed from future release. configure `export PYENV_VIRTUALENV_DISABLE_PROMPT=1' to simulate the behavior.
# 使用 pip 命令安装 Scrapy 框架
(scrapy-test) [root@server scrapy-test]# pip install scrapy
使用命令行创建一个新的 Scrapy 项目:
(scrapy-test) [root@server scrapy-test]# scrapy startproject china_pub
New Scrapy project 'china_pub', using template directory '/root/.pyenv/versions/3.8.1/envs/scrapy-test/lib/python3.8/site-packages/scrapy/templates/project', created in:
/root/scrapy-test/china_pub
You can start your first spider with:
cd china_pub
scrapy genspider example example.com
查看创建好的 Scrapy 项目的文件结构:
(scrapy-test) [root@server scrapy-test]# tree .
.
└── china_pub
├── china_pub
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── __pycache__
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
我们可以看到 Scrapy 命令给我们创建的项目目录和文件,这里我们来简单分析下这些目录和文件的含义,后面在介绍 Scrapy 框架的架构图后,会对这些目录以及 Scrapy 的运行有着深刻的理解:
- items.py:items.py 文件中一般用于定义 Item 对象,它用来指定爬取的数据的结构;
- middlewares.py:中间件文件,主要是处理 request 和 response 的中间过程;
- pipelines.py:项目的管道文件,它会对 items.py 中里面定义的数据进行进一步的加工与处理。启用该 pipline 时需要在 settings.py 中进行配置;
- settings.py:项目的配置文件,比如设置处理 Item 对象的 piplines、请求头的 ‘’User-Agent" 字段、代理、Cookie等;
- spider 目录:主要是存放爬取的动作及解析网页数据的代码。
2. 第一个基于 Scrapy 框架的爬虫
首先我们来看 Scrapy 项目的 spider 目录部分,新建一个 Python 文件,命名为:china_pub_crawler.py。这个文件中我们会用到 Scrapy 框架中非常重要的 Spider 类:
class ChinaPubCrawler(Spider):
name = "China-Pub-Crawler"
start_urls = ["http://www.china-pub.com/Browse/"]
def parse(self, response):
pass
# ...
我们实现一个 ChinaPubCrawler 类,它继承了 Scrapy 框架的 Spider 类,在这里我们会用到 Spider 类的两个属性和一个方法:
- name: 爬虫名称,后续在运行 Scrapy 爬虫时会根据名称运行相应的爬虫;
- start_urls:开始要爬取的 URL 列表,这个地址可以动态调整;
parse():该方法是默认的解析网页的回调方法。当然这里我们也可以自定义相应的函数来实现网页数据提取;
我们思考下前面完成互动出版网的步骤:第一步是请求 http://www.china-pub.com/Browse/ 这个网页数据,从中找出计算机分类的链接 URL。这一步我们可以这样实现:
class ChinaPubCrawler(Spider):
name = "China-Pub-Crawler"
start_urls = ["http://www.china-pub.com/Browse/"]
def parse(self, response):
"""
解析得到计算机互联网分类urls,然后重新构造请求
"""
for url in response.xpath("//div[@id='wrap']/ul[1]/li[@class='li']/a/@href").getall():
# 封装请求,交给引擎去下载网页;注意设置处理解析网页的回调方法
yield Request(url, callback=self.book_list_parse)
def book_list_parse(self, response):
pass
我们将起点爬取的 URL 设置为 http://www.china-pub.com/Browse/,然后使用默认的 parse() 解析这个网页的数据,提取到计算机分类的各个 URL 地址,然后使用 Scrapy 框架的 Request 类封装 URL 请求发送给 Scrapy 的 Engine 模块去继续下载网页。在 Request 类中我们可以设置请求网页的解析方法,这里我们会专门定义一个 book_list_parse() 类来解析图书列表的网页。
为了能提取相应的图书信息数据,我们要定义对应的图书 Item 类,位于 items.py 文件中,代码内容如下:
# -*- coding: utf-8 -*-
import scrapy
class ChinaPubItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
book_url = scrapy.Field()
author = scrapy.Field()
isbn = scrapy.Field()
publisher = scrapy.Field()
publish_date = scrapy.Field()
vip_price = scrapy.Field()
price = scrapy.Field()
这里正是我们前面定义的图书信息的 key 值,只不过这里用一种比较规范的方式进行了定义。
现在还有一个问题要解决:如何实现分页的图书数据请求?我们在 book_list_parse() 方法中可以拿到当前解析的 URL,前面我们分析过:请求的 URL 中包含请求页信息。
我们只需要将当前 URL 的页号加1,然后在构造 Request 请求交给 Scrapy 框架的引擎去执行即可,那么这样不会一直请求下去吗?我们只需要检查 response 的状态码,如果是 404,表示当前页号已经无效了,此时我们就不用再构造下一个的请求了,来看代码的实现:
import re
from scrapy import Request
from scrapy.spiders import Spider
from ..items import ChinaPubItem
class ChinaPubCrawler(Spider):
name = "China-Pub-Crawler"
start_urls = ["http://www.china-pub.com/Browse/"]
def parse(self, response):
"""
解析得到计算机互联网分类urls,然后重新构造请求
"""
for url in response.xpath("//div[@id='wrap']/ul[1]/li[@class='li']/a/@href").getall():
yield Request(url, callback=self.book_list_parse)
def book_list_parse(self, response):
# 如果返回状态码为404,直接返回
if response.status == 404:
return
# 解析当前网页的图书列表数据
book_list = response.xpath("//div[@class='search_result']/table/tr/td[2]/ul")
for book in book_list:
item = ChinaPubItem()
item['title'] = book.xpath("li[@class='result_name']/a/text()").extract_first()
item['book_url'] = book.xpath("li[@class='result_name']/a/@href").extract_first()
book_info = book.xpath("./li[2]/text()").extract()[0]
item['author'] = book_info.split('|')[0].strip()
item['publisher'] = book_info.split('|')[1].strip()
item['isbn'] = book_info.split('|')[2].strip()
item['publish_date'] = book_info.split('|')[3].strip()
item['vip_price'] = book.xpath("li[@class='result_book']/ul/li[@class='book_dis']/text()").extract()[0]
item['price'] = book.xpath("li[@class='result_book']/ul/li[@class='book_price']/text()").extract()[0]
yield item
# 生成下一页url,交给Scrapy引擎再次发送请求
url = response.url
regex = "(http://.*/)([0-9]+)_(.*).html"
pattern = re.compile(regex)
m = pattern.match(url)
if not m:
return []
prefix_path = m.group(1)
current_page = m.group(2)
suffix_path = m.group(3)
next_page = int(current_page) + 1
next_url = f"{prefix_path}{next_page}_{suffix_path}.html"
print("下一个url为:{}".format(next_url))
yield Request(next_url, callback=self.book_list_parse)
请求所有的 URL,解析相应数据,这些我们都有了,还差最后一步:数据入库!这一步我们使用 item Pipeline 来实现将得到的 item 数据导入到 MongoDB 中。编写的 item Pipeline 一般写在 pipelines.py 中,来看看代码样子:
import pymongo
class ChinaPubPipeline:
def open_spider(self, spider):
"""连接mongodb,并认证连接信息,内网ip"""
self.client = pymongo.MongoClient(host='192.168.88.204', port=27017)
self.client.admin.authenticate("admin", "shencong1992")
db = self.client.scrapy_manual
# 新建一个集合保存抓取到的图书数据
self.collection = db.china_pub_scrapy
def process_item(self, item, spider):
# 处理item数据
try:
book_info = {
'title': item['title'],
'book_url': item['book_url'],
'author': item['author'],
'isbn': item['isbn'],
'publisher': item['publisher'],
'publish_date': item['publish_date'],
'vip_price': item['vip_price'],
'price': item['price'],
}
self.collection.insert_one(book_info)
except Exception as e:
print("插入数据异常:{}".format(str(e)))
return item
def close_spider(self, spider):
# 关闭连接
self.client.close()
最后为了使这个 pipeline 生效,我们需要将这个 pipeline 写到 settings.py 文件中:
# settings.py
# ...
ITEM_PIPELINES = {
'china_pub.pipelines.ChinaPubPipeline': 300,
}
# ...
最后,我们还需要在请求的头部加上一个 User-Agent 参数,这个设置在 settings.py 中完成:
# settings.py
# ...
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
# ...
整个爬虫代码就基本完成了,接下来开始我们激动人心的数据爬取吧!
3. 运行 Scrapy 项目,爬取数据
运行这个 scrapy 爬虫的命令如下:
(scrapy-test) [root@server scrapy-test]# scrapy crawl China-Pub-Crawler
# 开始源源不断的爬取数据
# ...
下面来看我们的视频演示效果:
通过今天的一个简单小项目,大家对 Scrapy 框架是否有了初步的印象?后面我们会仔细剖析 Scrapy 框架的各个模块以及实现原理,让大家真正理解和掌握 Scrapy 框架。
4. 小结
本节中我们基于 Scrapy 框架完成了和上一小节类似的功能:爬取互动出版网的计算机类书籍信息并保存到 MongoDB 中。可以看到很明显的区别是,Scrapy 中的代码看起来比较规范和高大上,且我们不再去使用 requests 这样的库去请求网页数据,这些都在 Scrapy 内部帮我们做好了。对于爬取一个大型网站时,Scrapy 还有更多的功能帮我们简化代码,比如登录、Cookie 管理、代理请求等等。好了,第一部分的内容就介绍到这里了,接下来我们就开始 Scrapy 框架的剖析之旅了!
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出