Splash服务初体验
今天我们来看看 Splash 服务在 Scrapy 框架中的应用。本次实践的网站依旧是头条新闻的热点新数据,这次我们不用在分析热点新闻数据的获取以及各种加密、解密这么麻烦的事情了,直接使用渲染后的结果提取数据,方便省事。
1. Splash 介绍
Splash 是一个 JavaScript 渲染服务,是一个带有 HTTP API 的轻量级浏览器,同时它对接了 Python 中的 Twisted和 QT 库。利用它,我们同样可以实现动态渲染页面的抓取。该服务最简单且最常用的搭建方式是使用 docker,我们直接来看如何在一台云主机上安装并启动 Splash 服务。
安装 Docker,可以参考文献1,操作环境为 CentOS 7.8,亲测有效;
# 安装必要的依赖包
[root@server2 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加docker的安装源
[root@server2 ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
Loaded plugins: fastestmirror
adding repo from: https://download.docker.com/linux/centos/docker-ce.repo
grabbing file https://download.docker.com/linux/centos/docker-ce.repo to /etc/yum.repos.d/docker-ce.repo
repo saved to /etc/yum.repos.d/docker-ce.repo
# 安装最新版本的 docker
[root@server2 ~]# sudo yum install docker-ce
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
Package 3:docker-ce-19.03.12-3.el7.x86_64 already installed and latest version
Nothing to do
启动 docker 服务,然后可以使用 docker 命令:
[root@server2 ~]# systemctl start docker
使用 docker 安装 Splash 服务:
[root@server2 ~]# sudo docker run -p 8050:8050 scrapinghub/splash
2020-08-02 12:28:27+0000 [-] Log opened.
2020-08-02 12:28:27.980032 [-] Xvfb is started: ['Xvfb', ':1020290545', '-screen', '0', '1024x768x24', '-nolisten', 'tcp']
QStandardPaths: XDG_RUNTIME_DIR not set, defaulting to '/tmp/runtime-splash'
2020-08-02 12:28:28.171896 [-] Splash version: 3.4.1
2020-08-02 12:28:28.249359 [-] Qt 5.13.1, PyQt 5.13.1, WebKit 602.1, Chromium 73.0.3683.105, sip 4.19.19, Twisted 19.7.0, Lua 5.2
2020-08-02 12:28:28.249582 [-] Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0]
2020-08-02 12:28:28.249670 [-] Open files limit: 1048576
2020-08-02 12:28:28.249718 [-] Can't bump open files limit
2020-08-02 12:28:28.278146 [-] proxy profiles support is enabled, proxy profiles path: /etc/splash/proxy-profiles
2020-08-02 12:28:28.278310 [-] memory cache: enabled, private mode: enabled, js cross-domain access: disabled
2020-08-02 12:28:28.429778 [-] verbosity=1, slots=20, argument_cache_max_entries=500, max-timeout=90.0
2020-08-02 12:28:28.430058 [-] Web UI: enabled, Lua: enabled (sandbox: enabled), Webkit: enabled, Chromium: enabled
2020-08-02 12:28:28.430491 [-] Site starting on 8050
2020-08-02 12:28:28.430580 [-] Starting factory <twisted.web.server.Site object at 0x7f37918771d0>
2020-08-02 12:28:28.430855 [-] Server listening on http://0.0.0.0:8050
注意:本人的机器上已经安装了 Splash 服务镜像,所以使用 docker run 命令将直接启动该镜像。如果是第一次启动,则会先去镜像仓库拉去该镜像,然后再启动,这会有一点耗时。
完成上面的操作后,我们来直接访问云主机的8050端口,来看看相关的页面并进行说明:
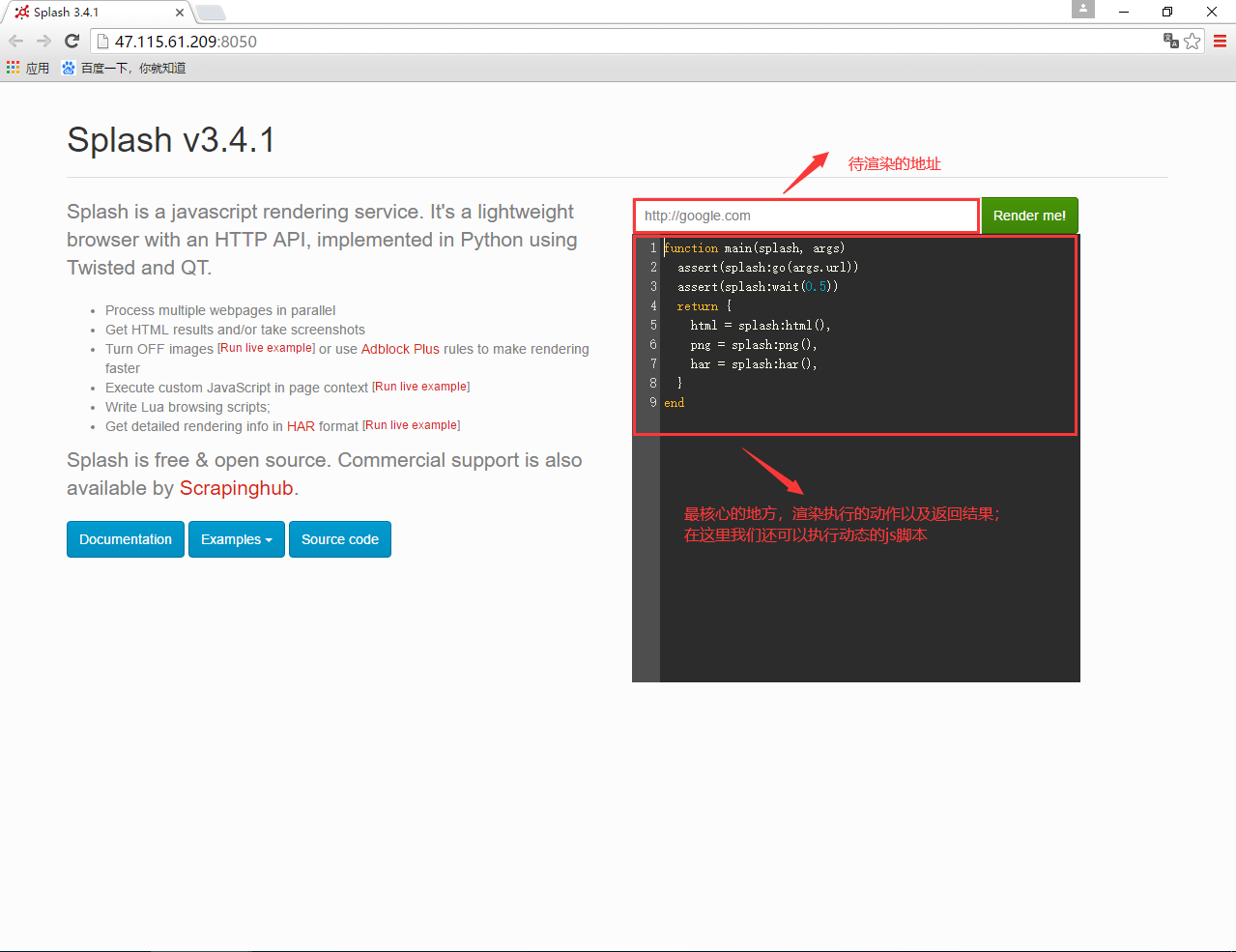
其中最核心的地方就是待渲染的 url 地址和对应的控制脚本了。我们来实际操作一番,来看下面的演示视频:
这个视频中我只是简单地将头条热点新闻的网址放到了待渲染的 URL 地址输入框中,然后修改等待渲染的时间为 2秒,直接点击【Render Me!】按钮,过一会就看到了被渲染的头条热点新闻页面。脚本中默认返回 HTML、图片以及请求的统计结果,这些我们在结果页面中都看到了。接下来我们就在 Scrapy 中结合这个 Splash 服务来爬取看到的热点新闻数据。
2. Scrapy-Splash 插件
上面我们已经看到了 Splash 的强大之处,而这正是 Scrapy 框架所无法做到的,它只能爬取静态的网页而无法直接爬取经过动态渲染的网页数据,因此有了这种 Scrapy 和 Splash 的结合使用的想法,也产生了 Scrapy-Splash 插件。Scrapy-Splash 插件使用的正是Splash HTTP API,因此我们在编写对应的爬虫程序时需要启动一个 Splash 服务,然后 scrapy-splash 模块会通过调用 api 的方式将我们需要渲染的网页以及相应的脚本带过去执行,然后拿到渲染后的页面,再交给 Scrapy 框架去执行。
我们去官网看看 Scrapy-Splash 插件的使用:
安装 scrapy-splash 插件:`pip install scrapy-splash`;
另外该插件在 Scrapy 中的配置和使用均在 github 上有详细的介绍,许多关于 scrapy-splash 的使用文章内容均来源于此,这里就不做过多介绍,我们直接在实战中使用即可,至于背后的配置读取原理,就需要各位去仔细阅读插件源码了。
3. 再战今日头条热点新闻爬取
上一部分我们费了九牛二虎之力爬取的头条热点新闻,今天要使用 scrapy-splash 插件和 splash 服务轻轻松松完成。我们省去前面创建 scrapy 爬虫的过程,直接看重点:
首先是定义 items:
import scrapy
class ToutiaoSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
source = scrapy.Field()
comments = scrapy.Field()
passed_time = scrapy.Field()
然后是爬虫的核心代码:
from scrapy import Spider
from scrapy_splash.request import SplashRequest
from toutiao_spider.items import ToutiaoSpiderItem
script = """
function main(splash, args)
assert(splash:go(args.url))
splash:wait(2)
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
"""
class TouTiaoSpider(Spider):
name = "toutiao_spider"
def start_requests(self):
splah_args = {
"lua_source": script,
# 这个非常重要
'wait': 5,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}
yield SplashRequest(url="https://www.toutiao.com/ch/news_hot/", args=splah_args, headers=headers)
def parse(self, response):
news_list = response.css('div.wcommonFeed ul li')
print("共{}条数据".format(len(news_list)))
for news in news_list:
title = news.css('div.title-box a::text').extract_first()
source = news.css('div.footer a:nth-child(2)::text').extract_first()
comments = news.css('div.footer a:nth-child(3)::text').extract_first()
passed_time = news.css('div.footer span::text').extract_first()
if not title:
continue
items = ToutiaoSpiderItem()
items['title'] = title.strip()
# 使用split()再join()的方式是为了清除前后的\xa0
items['source'] = "".join(source.split())
items['comments'] = "".join(comments.split())
items['passed_time'] = "".join(passed_time.split())
print(f'抓取数据到:{items}')
# yield items
这里的代码相比 Scrapy 代码变化的只有一个地方,就是对应生成的 Request 请求,我们需要替换成 scrapy-splash 插件中的 SplashRequest 类。在该类中最重要的就是 args 参数,这里我们会带上相应的 lua 执行脚本,也就是前面 Splash 服务的网页上看到的那个脚本。此外,这里我换成了 CSS 选择器去解析网页数据,其实和 xpath 方式并没有什么不同;
最后来看 settings.py 中的配置,和官方推荐的方式保持一致即可,不过我做了一些改动:
-
指定 SPLASH_URL,即 Splash 服务地址,这里对应的值为
http://47.115.61.209:8050/; -
添加 scrapy-splash 的中间件:
SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } -
添加 scrapy-splash 的下载中间件:
DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } -
另外,scrapy-splash 也提供了一个重复过滤器类:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
不过这样爬取时我们遇到了如下的报错:
2020-08-02 22:07:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.toutiao.com/robots.txt> (referer: None)
2020-08-02 22:07:26 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.toutiao.com/ch/news_hot/>
2020-08-02 22:07:26 [scrapy.core.engine] INFO: Closing spider (finished)
头条网站使用 robots 协议禁止我们爬取它的网站,当然我们只需要无视这样的协议,继续执行爬取动作即可。在 settings.py 中将遵守 robots 协议的开关禁止即可:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
来看看最后的执行效果:
PS D:\shencong\scrapy-lessons\code\chap16\toutiao_spider> scrapy crawl toutiao_spider
给大家留一个课后作业:今日头条的新闻是需要鼠标向下滑动,然后才会加载更多热点新闻,那么我们如何利用这个 Splash 服务来能实现抓取更多的头条热点数据呢?
4. 小结
本小节中我们使用 Splash 服务来辅助我们爬取渲染后的网页,这样可以极大的减少我们去分析网页数据的获取方式,简化了网站爬取的难度。今天介绍的 Splash 服务还有许许多多我们需要去深入和学习的,比如对渲染后的页面执行 js 动作等等,只有掌握了这些,才能更好的利用 Splash 为我们获得想要的数据。
5. 参考文献
[1] Centos7上安装docker
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出