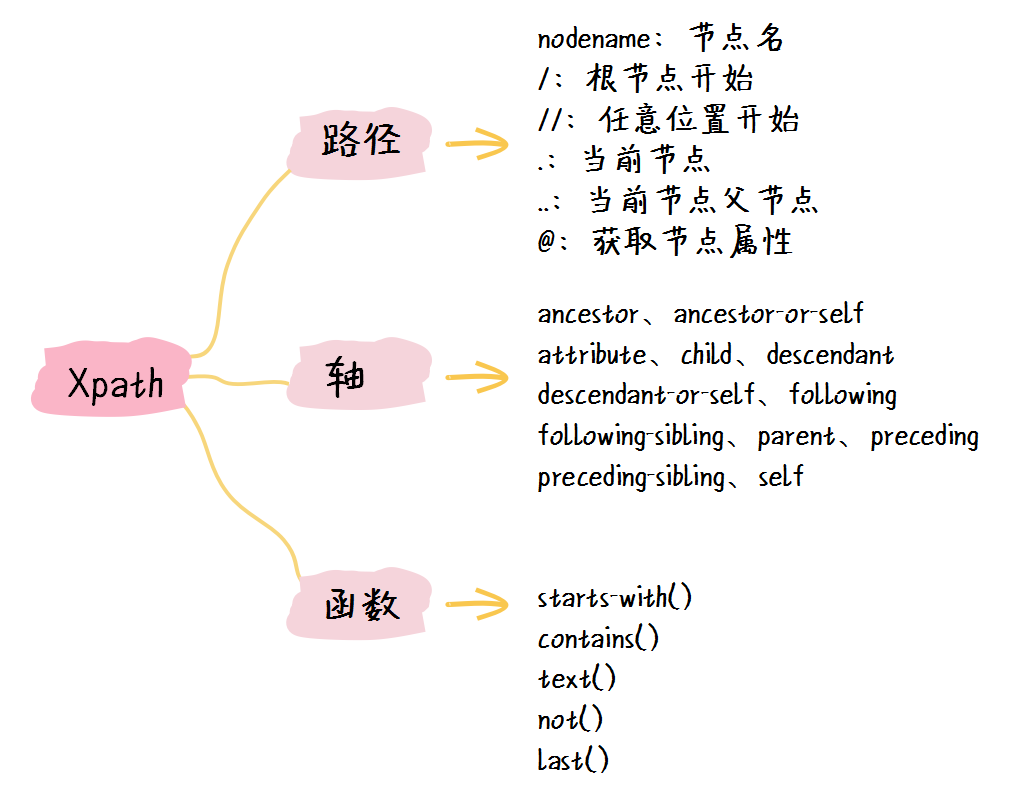
Scrapy 默认的网页解析器 Xpath
Xpath 是 Scrapy 框架中默认的网页解析器,只有掌握了 Xpath 选择器,我们才能快速从网页元素中提取我们想要的数据。
1. xpath 选择器介绍
首先来看看 Xpath 的字面介绍:
XPath 即为 XML 路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。XQuery 和 XPointer 均构建于 XPath 表达式之上。
来看看 xpath 最常用的路径表达式规则:
| 表达式 | 描述 |
|---|---|
| nodename | 选择此元素的所有子节点 |
| / | 从根节点开始选择 |
| // | 从匹配选择的当前节点选择文档中的节点 |
| . | 当前节点 |
| … | 当前节点的父节点 |
| @ | 选取属性 |
来看下面几个例子:
| 路径表达式 | 含义 |
|---|---|
| p | 选择所有 p 节点 |
| //body | 选择所有的body元素节点/ |
| //*[@class=“red-color”]/… | 选择所有class属性值为 “red-color” 节点的父节点 |
在 xpath 中可以使用通配符来提取相关节点元素:
| 路径表达式 | 含义 |
|---|---|
| //* | 找出所有节点 |
| //*[@*] | 匹配任何有属性的节点 |
| //*[@class=“red-color”] | 提取所有class属性值为 “red-color” 的节点 |
另外,在 xpath 中我们还可以使用运算符,来辅助选取节点:
| 路径表达式 | 含义 |
|---|---|
| //div | //p | 选取div或者p元素的节点 |
| //p[1 + 1]/text() | 获取第二个p元素节点的文本值 |
| //*[@value > 10] | 找出所有 value 值大于10的节点 |
其中 xpath 支持的表达式除了 +、- *、div 和 mod 等基本运算符外,还有比较运算符,如 =、!=、>=、<=、> 、> 、and、or等。
在 xpath 中有一个叫做轴的概念,表示相对于当前节点的节点集。下面是一些基本轴的定义:
| 轴名称 | 含义 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等) |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
| attribute | 选取当前节点的所有属性 |
| child | 选取当前节点的所有子元素 |
| descendant | 选取当前节点的所有后代元素(子、孙等) |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身 |
| following | 选取文档中当前节点的结束标签之后的所有节点 |
| following-sibling | 选取文档中当前节点的结束标签之后的所有同级节点 |
| parent | 选取当前节点的父节点 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点 |
| preceding-sibling | 选取当前节点之前的所有同级节点 |
| self | 选取当前节点 |
轴的用法是:轴名称::节点测试。来看下面几个例子:
| 路径表达式 | 含义 |
|---|---|
| //body/div[2]/following-sibling::* | body节点下第二个div节点之后的所有同级节点 |
| //body/p[1]/child::span[last()]/text() | body节点下的第一个p节点下的最后一个span子节点的文本值 |
| //body/p[1]/span/child::text() | body节点下的第一个p节点下的所有span子节点的文本值 |
| //body/p/attribute::* | body节点下所有p节点的属性值 |
最后,在 xpath 中还有一些辅助我们更好搜索节点的函数:
| 函数 | 含义 |
|---|---|
| starts-with() | 获取某个字符串开头的节点 |
| contains() | 包含某个字符串的节点,可以是属性包含、文本包含等等 |
| text() | 获取节点的文本值 |
上述辅助函数的实例如下:
| 路径表达式 | 含义 |
|---|---|
| //p[contains(@class, “red”)] | 获取class属性值包含"red"的所有p节点值 |
| ‘//span[contains(text(), “蓝色”)]/text()’ | 获取文本值包含"蓝色"的所有span节点的文本 |
| ‘//span[starts-with(text(), “蓝”)]/text()’ | 获取文本值以"蓝"开头的所有span节点的文本 |
此外,当然还有许多方面没有讲到,后续会在实战中进行说明。上面的基础部分一定要熟记和灵活运用,足以应付常见的页面数据提取。下面就进入实战环节,使用 Python 来实操 xpath 路径表达式。
2. xpath 解析实战
lxml 是 Python 中的一个解析库,支持 HTML 和 XML 的解析,支持 XPath 解析方式,而且解析效率非常高。本节将安装该模块解析 html 文本并提取相应的数据。
[store@server2 ~]$ sudo pip3 install lxml
WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead.
Collecting lxml
Downloading http://mirrors.cloud.aliyuncs.com/pypi/packages/55/6f/c87dffdd88a54dd26a3a9fef1d14b6384a9933c455c54ce3ca7d64a84c88/lxml-4.5.1-cp36-cp36m-manylinux1_x86_64.whl (5.5MB)
100% |████████████████████████████████| 5.5MB 82.9MB/s
Installing collected packages: lxml
Successfully installed lxml-4.5.1
我们先准备好素材,也就是要解析的 HTML 文档。为了更有代入感,我直接使用慕课网 wiki 页面的数据进行操作,获取数据的方式如下图所示:
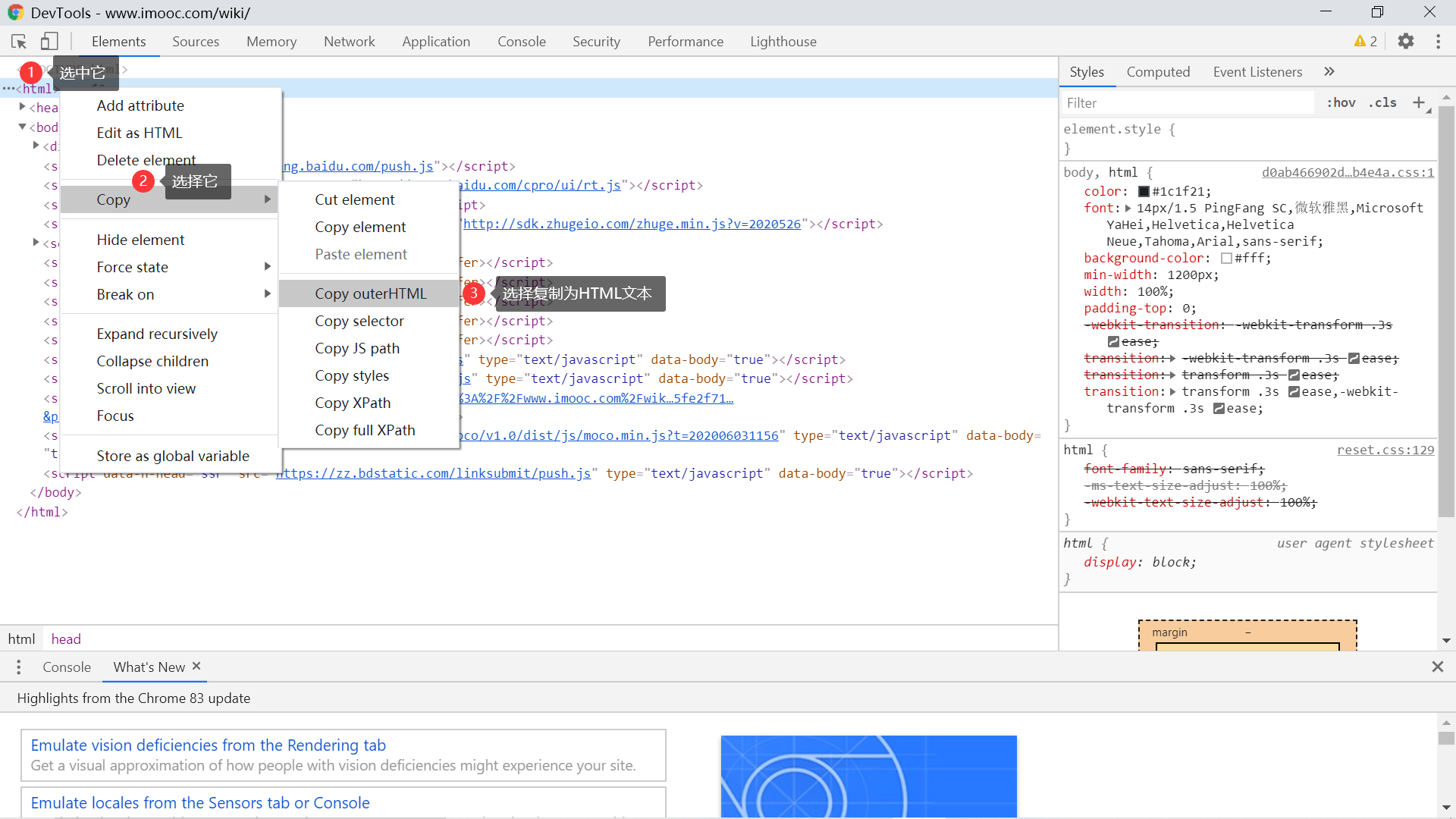
最后保存到一个 test.html 文本,然后我们要准备一段 Python 代码:
from lxml import etree
tree = etree.parse('test.html', etree.HTMLParser(encoding='utf8'))
def print_result(exp, results):
print('xpath表达式为:{},其匹配结果为:'.format(exp))
for res in results:
print(res.strip())
print('')
def test_xpath_expression(exp):
results = tree.xpath(exp)
print_result(exp, results)
将这个 Python 文件命名为 test_xpath.py 和 test.html 放在同一级目录下:
[store@server2 ~]$ ls
shen test.html test_xpath.py
接下来我们就可以进行激动人心的测试了,来完成一个简单的实验:
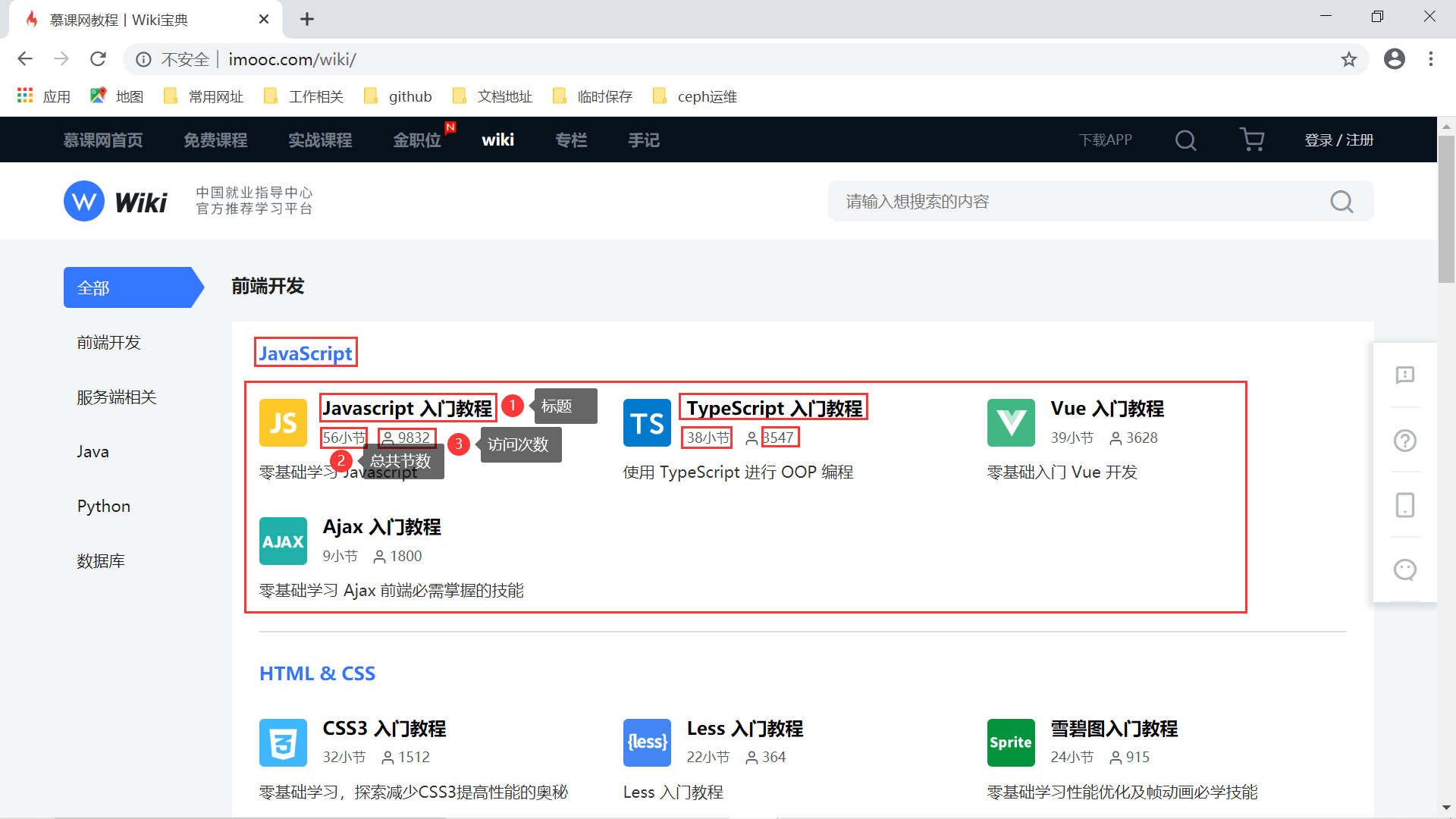
第一个实验的目标就是拿到 javascript 分类下的教程的三个数据:标题、总节数以及访问次数。通过 F12 查看相关的 HTML 结构,我们可以通过如下的 Xpath表达式获取相应的数据:
Python 3.6.8 (default, Apr 2 2020, 13:34:55)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from test_xpath import test_xpath_expression
>>> exp1 = '//h2[@class="language-title"]/text()'
>>> test_xpath_expression(exp1)
xpath表达式为://h2[@class="language-title"]/text(),其匹配结果为:
JavaScript
HTML & CSS
服务器
开发工具
其他后端语言
基础应用
框架应用
基础应用
Python Web 开发
MySQL
接下来看一看元素的结构:
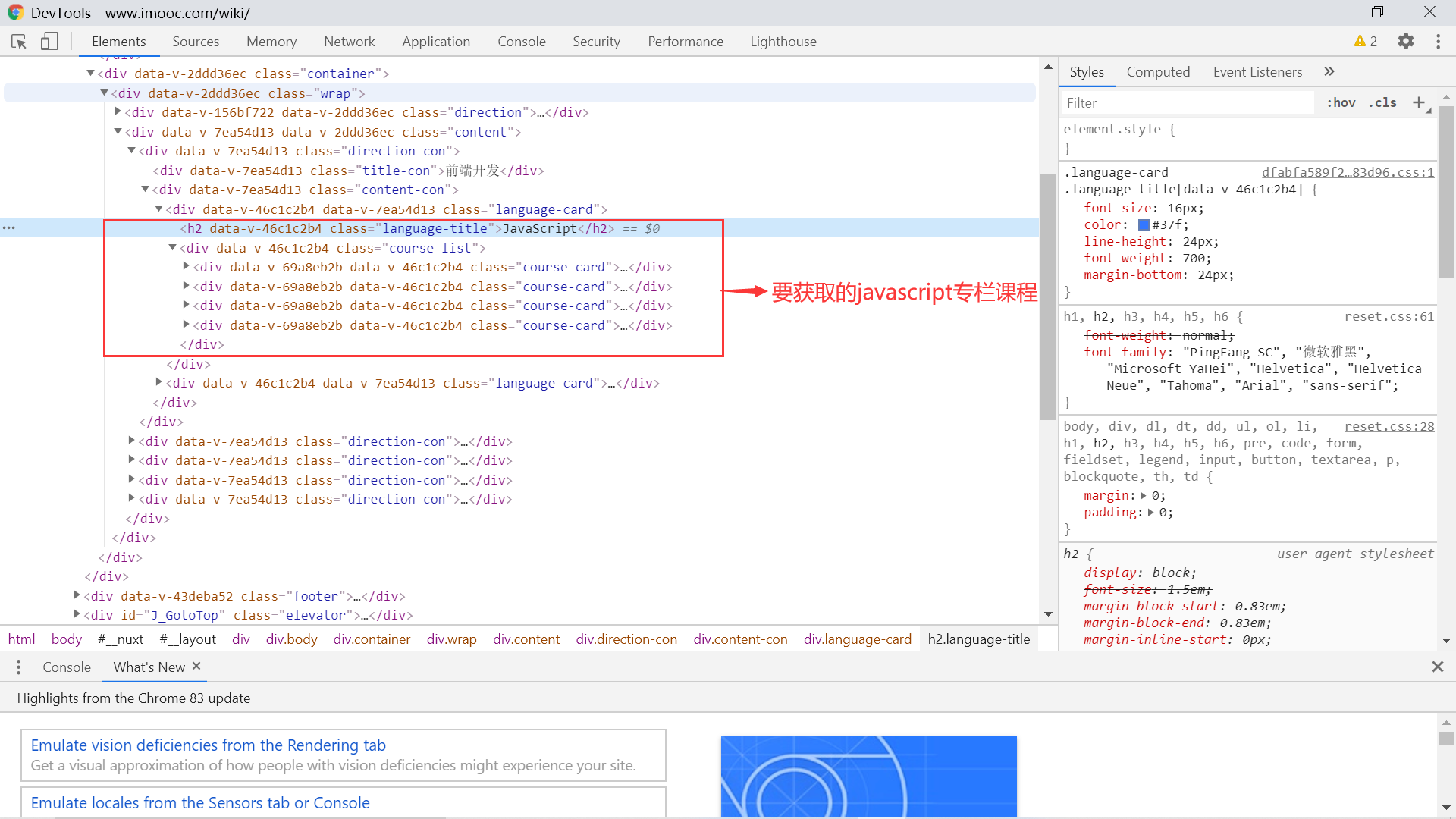
可以看到 javascript 专栏标题是 h2 节点,这个节点同级下有一个 div,它下面的四个 div 节点正是那四个专栏。我们首先匹配下这四个专栏元素:
>>> exp1 = '//h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]'
>>> test_xpath_expression(exp1)
xpath表达式为://h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"],其匹配结果为:
<Element div at 0x7f7015bf8808>
<Element div at 0x7f700c656788>
<Element div at 0x7f700c6567c8>
<Element div at 0x7f700c656808>
那么我们来进一步分析每个 div 内部如何得到教程标题、总节数以及访问次数这些数据:

可以看到,在前面找到 div 节点的基础上在往下两层,找到 class 属性值为 text 的 div 节点,所有的数据都在这个节点中:
- 标题:上面找到的 div 节点下的第一个 a 节点的文本值;
- 教程总节数:上面找到的 div 节点下的第一个 p 节点下第一个 span 元素的文本值;
- 总访问次数:上面找到的 div 节点下的第一个 p 节点下第二个 span 元素的文本值;
这样我们就能进行写出提取相应数据的 Xpath 路径表达式了,测试如下:
>>> exp1 = '//h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/a[1]/text()'
>>> test_xpath_expression(exp1)
xpath表达式为://h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/a[1]/text(),其匹配结果为:
Javascript 入门教程
TypeScript 入门教程
Vue 入门教程
Ajax 入门教程
>>> exp2 = '//h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/p/span[1]/text()'
>>> test_xpath_expression(exp2)
xpath表达式为://h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/p/span[1]/text(),其匹配结果为:
56小节
38小节
39小节
9小节
>>> exp3 = '//h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/p/span[2]/text()'
>>> test_xpath_expression(exp3)
xpath表达式为://h2[contains(text(), "JavaScript")]/following-sibling::div/div[@class="course-card"]/child::div/div[@class="text"]/p/span[2]/text(),其匹配结果为:
9832
3547
3628
1800
接下来我们整理下 Python 代码,将整个 wiki 页面上的教程都解析出来,并将数据整理成 json 格式。预期最后的结果应该是这样的:
{
'前端开发': {
'JavaScript': [
{'title': 'JavaScript入门教程', 'total_chapters': 56, 'total_visited': 9001},
{...},
{...},
{...}
],
'HTML & CSS': [ ... ]
}
'服务端相关': {
},
...
}
这样的难度再次增加,其核心的获取数据的过程和上面一致。后面获取其他数据的结果过程不作分析,大家有兴趣仔细研究下代码,然后动手实操。话不多说,上代码:
# 代码文件:test_xpath2.py
from lxml import etree
def get_direction_data(direction_tree):
"""
获取一个方向下的课程数据
:return:
"""
direction_data = {}
cards = direction_tree.xpath('.//div[@class="language-card"]')
for card in cards:
title = card.xpath('.//h2[@class="language-title"]/text()')[0]
course_list = card.xpath('.//div[@class="course-card"]')
courses = []
for course in course_list:
course_title = course.xpath('.//div[@class="text"]/a[1]/text()')[0]
course_total_chaps = course.xpath('.//div[@class="text"]/p/span[1]/text()')[0]
course_total_visit_count = course.xpath('.//div[@class="text"]/p/span[2]/text()')[0]
courses.append({
'course_title': course_title.strip(),
'course_total_chaps': course_total_chaps.strip(),
'course_total_visit_count': int(course_total_visit_count.strip())
})
direction_data[title] = courses
return direction_data
def get_all_data():
"""
解析慕课网wiki数据
:return:
"""
result = {}
html = etree.parse('test.html', etree.HTMLParser(encoding='utf8'))
directions = html.xpath('//div[@class="direction-con"]')
for direction in directions:
# 提取方向key,注意一定要有点号,表示从当前元素开始提取
direction_name = direction.xpath('./div[@class="title-con"][1]/text()')
if direction_name:
result[direction_name[0]] = get_direction_data(direction)
return result
运行的结果如下:
[store@server2 ~]$ python3
Python 3.6.8 (default, Apr 2 2020, 13:34:55)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from test_xpath2 import get_all_dat
>>> get_all_data()
{'前端开发': {'JavaScript': [{'course_title': 'Javascript 入门教程', 'course_total_chaps': '56小节', 'course_total_visit_count': 9832}, {'course_title': 'TypeScript 入门教程', 'course_total_chaps': '38小节', 'course_total_visit_count': 3547}, {'course_title': 'Vue 入门教程', 'course_total_chaps': '39小节', 'course_total_visit_count': 3628}, {'course_title': 'Ajax 入门教程', 'course_total_chaps': '9小节', 'course_total_visit_count': 1800}], 'HTML & CSS': [{'course_title': 'CSS3 入门教程', 'course_total_chaps': '32小节', 'course_total_visit_count': 1512}, {'course_title': 'Less 入门教程', 'course_total_chaps': '22小节', 'course_total_visit_count': 364}, {'course_title': '雪碧图入门教程', 'course_total_chaps': '24小节', 'course_total_visit_count': 915}]}, '服务端相关': {'服务器': [{'course_title': 'Nginx 入门教程', 'course_total_chaps': '24小节', 'course_total_visit_count': 4500}, {'course_title': 'HTTP 入门教程', 'course_total_chaps': '16小节', 'course_total_visit_count': 456}, {'course_title': 'Docker 入门教程', 'course_total_chaps': '25小节', 'course_total_visit_count': 1067}, {'course_title': 'Shell 入门教程', 'course_total_chaps': '17小节', 'course_total_visit_count': 2060}, {'course_title': 'Linux 入门教程', 'course_total_chaps': '25小节', 'course_total_visit_count': 1430}], '开发工具': [{'course_title': 'Gradle 入门教程', 'course_total_chaps': '12小节', 'course_total_visit_count': 1121}, {'course_title': 'Vim 入门教程', 'course_total_chaps': '14小节', 'course_total_visit_count': 1491}, {'course_title': 'RESTful 规范教程', 'course_total_chaps': '13小节', 'course_total_visit_count': 1316}, {'course_title': 'Markdown 入门教程', 'course_total_chaps': '31小节', 'course_total_visit_count': 733}, {'course_title': 'Maven 入门教程', 'course_total_chaps': '17小节', 'course_total_visit_count': 155}, {'course_title': 'GitHub 入门教程', 'course_total_chaps': '9小节', 'course_total_visit_count': 261}], '其他后端语言': [{'course_title': 'C 语言入门教程', 'course_total_chaps': '45小节', 'course_total_visit_count': 1933}, {'course_title': 'Go 入门教程', 'course_total_chaps': '36小节', 'course_total_visit_count': 691}, {'course_title': 'Ruby 入门教程', 'course_total_chaps': '26小节', 'course_total_visit_count': 410}]}, 'Java': {'基础应用': [{'course_title': 'Java 入门教程', 'course_total_chaps': '39小节', 'course_total_visit_count': 5229}, {'course_title': 'Android 入门教程', 'course_total_chaps': '29小节', 'course_total_visit_count': 553}, {'course_title': '算法入门教程', 'course_total_chaps': '11小节', 'course_total_visit_count': 628}], '框架应用': [{'course_title': 'Spring Boot 入门教程', 'course_total_chaps': '25小节', 'course_total_visit_count': 4861}, {'course_title': 'Spring 入门教程', 'course_total_chaps': '21小节', 'course_total_visit_count': 850}, {'course_title': 'Hibernate 入门教程', 'course_total_chaps': '23小节', 'course_total_visit_count': 619}, {'course_title': 'MyBatis 入门教程', 'course_total_chaps': '23小节', 'course_total_visit_count': 895}]}, 'Python': {'基础应用': [{'course_title': 'Python 入门语法教程', 'course_total_chaps': '24小节', 'course_total_visit_count': 3617}, {'course_title': 'Python 原生爬虫教程', 'course_total_chaps': '19小节', 'course_total_visit_count': 2001}, {'course_title': 'Python 进阶应用教程', 'course_total_chaps': '29小节', 'course_total_visit_count': 726}], 'Python Web 开发': [{'course_title': 'Django 入门教程', 'course_total_chaps': '33小节', 'course_total_visit_count': 668}, {'course_title': 'NumPy 入门教程', 'course_total_chaps': '21小节', 'course_total_visit_count': 152}]}, '数据库': {'MySQL': [{'course_title': 'MySQL 入门教程', 'course_total_chaps': '32小节', 'course_total_visit_count': 3638}, {'course_title': 'SQL 入门教程', 'course_total_chaps': '47小节', 'course_total_visit_count': 2406}]}}
是不是实现了预期效果?爬取网页,解析数据的过程和这个类似。掌握好今天的内容,你就已经掌握了爬虫的一个核心步骤。
3. 小结
本小节中,我们重点介绍了 Xpath 选择器的一些基本知识,包括通用的路径表达式规则、运输符、轴的概念以及 Xpath 选择器中常用的辅助函数。接下来我们用一段 Html 文本结合 Python 代码进行了实战演示,帮助我们更好的理解 xpath 选择器,本节课程就到这里,希望大家有所收获。