Selenium 自动化测试工具介绍
今天我们来介绍下 Selenium 自动化测试工具并借助该工具完成一个简单的案例,这个案例和笔者的工作相关,也算挺有意思的。
1. Selenuim 介绍与使用
Selenium 是一个用于 Web 应用程序自动化测试工具,提供一系列的测试函数。这些函数非常灵活,能够完成界面元素定位、窗口跳转、结果比较。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。该自动化测试工具具有如下几个鲜明的特点:
- 支持多种浏览器:IE、Firefox、Safari、Chrome 等主流浏览器都是支持的;
- 支持多种变成语言:支持主流的编程语言,如 Java、Python、Ruby、PHP 等;
- 支持多种操作系统:如 Windows、Linux、IOS 以及 Android 等;
- 开源免费:selenuim 在 github 上进行了开源,star 和 fork 数都彰显了该项目的流行度。Selenium框架由多个工具组成,包括:Selenium IDE,Selenium RC,Selenium WebDriver和SeleniumRC。
我们直接来在使用 Python 操作 Selenuim:
安装 selenium 模块:pip install selenium -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com;
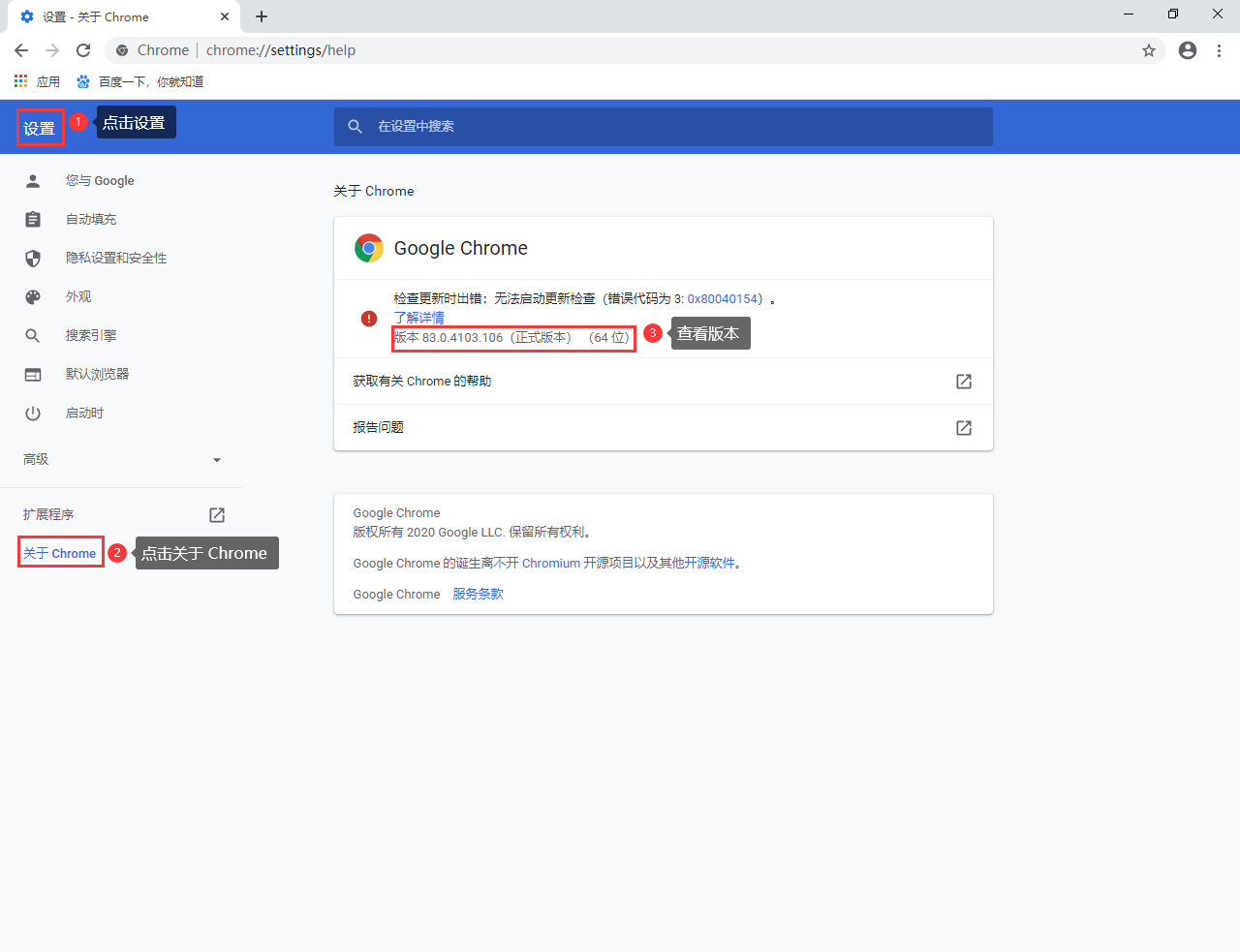
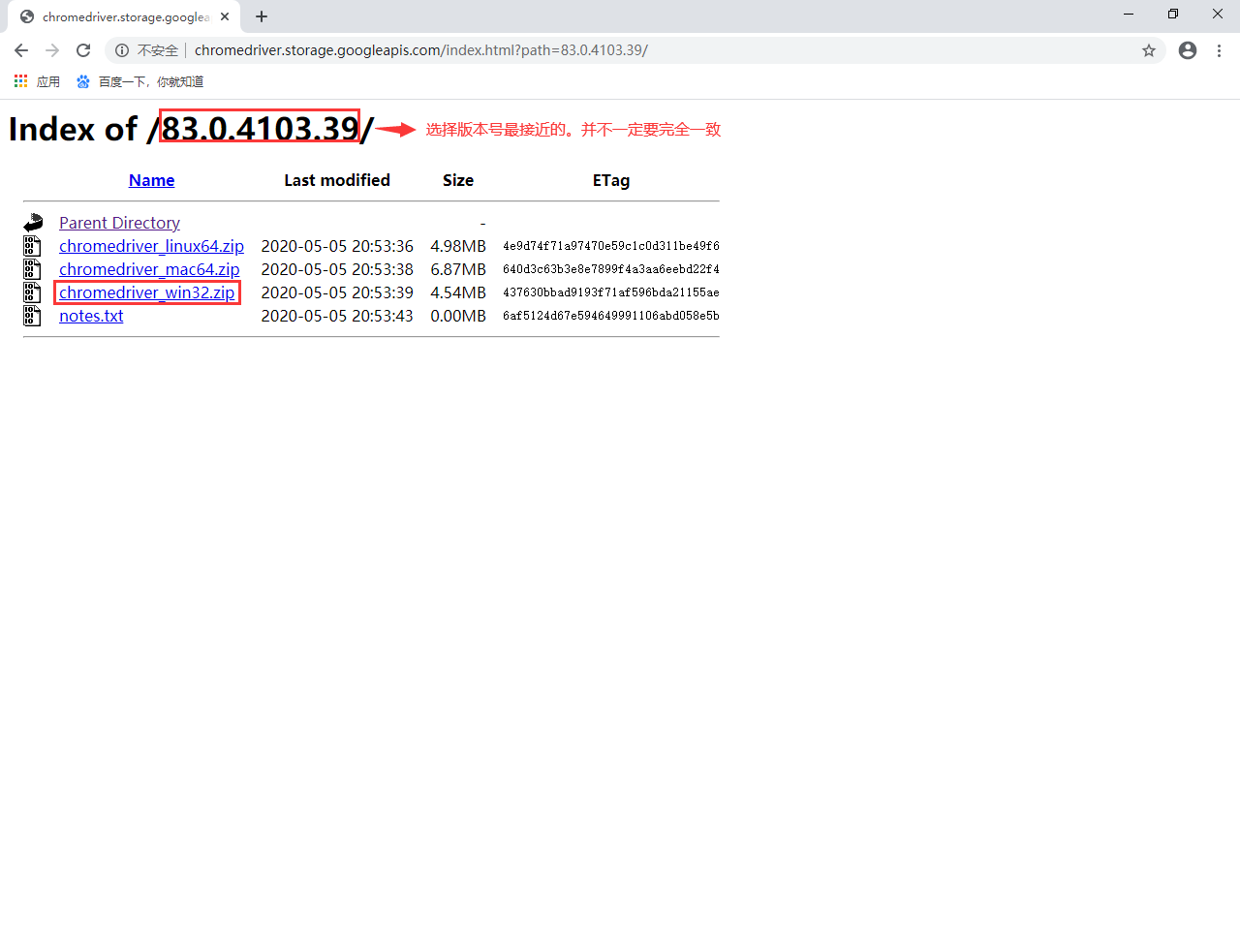
接下来,我们要使用 Google 浏览器完成 selenium 的自动化操作,因此需要安装相应的 webdriver。对应 Google 浏览器的 webdriver 的下载地址为:下载。找到对应的 Chrome driver 版本,下载即可:
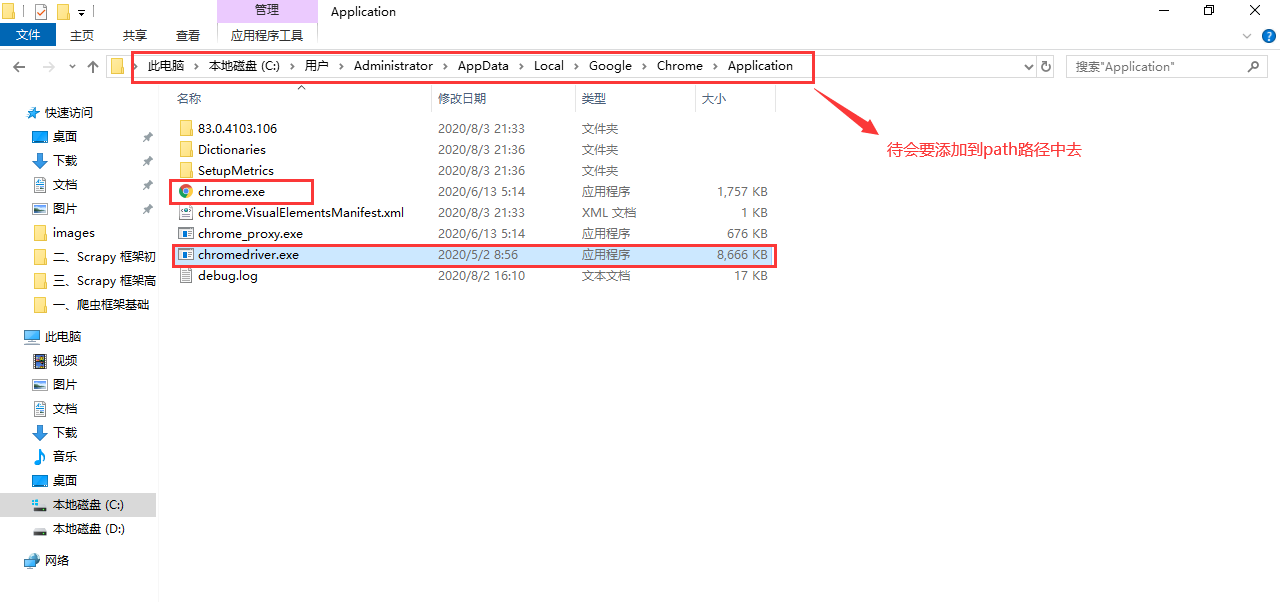
下载了 webdriver 包后解压得到 chromedriver.exe,将其放到和 Chrome 浏览器相同的路径下:
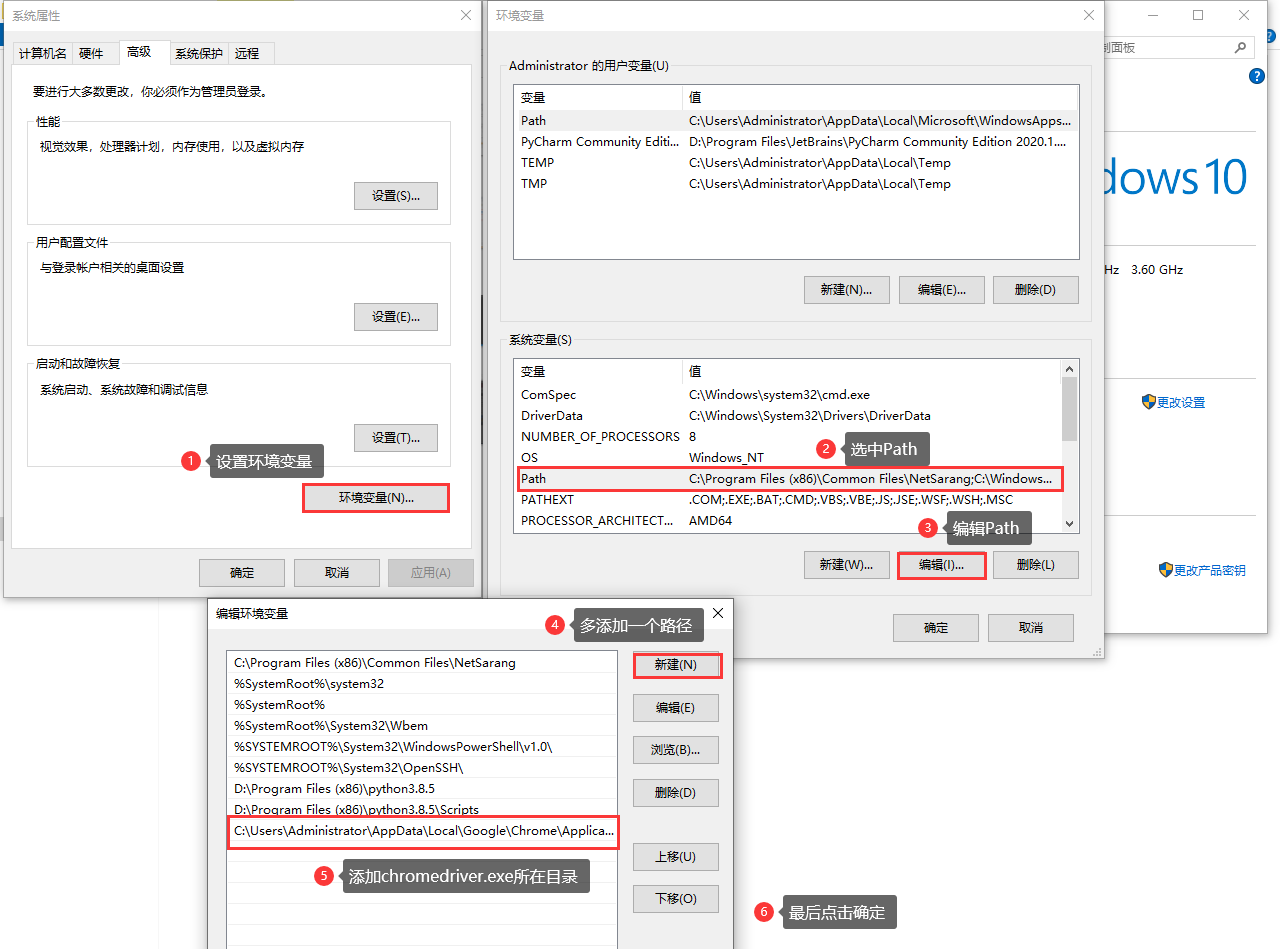
接下来将上面的这个路径添加到系统变量 Path 中去,确保能找到 chromedriver.exe 这个文件:
接下来,我们完成一段简单的 Selenium 自动化测试代码,帮助我们更好的理解 Selenium 这个工具:
"""
selenium工具测试
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
# 请求百度页面
driver.get("https://www.baidu.com")
# 找到输入框位置
input = driver.find_element_by_id("kw")
# 输入"慕课网 wiki宝典"
input.send_keys("慕课网 wiki宝典")
# 找到<百度一下>按钮
button = driver.find_element_by_id("su")
# 点击
button.click()
# 直到出现分页元素
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "page"))
)
# 找到搜索内容的第一条结果
wiki_page = driver.find_element_by_xpath('//div[@id="content_left"]/div[1]/h3/a')
# 点击跳转到慕课网的wiki页面
wiki_page.click()
上面的代码比较简单,我们只需要了解下 selenium 工具提供的基本函数就能够理解,代码中已经做好了相关注释,我们直接来运行看看效果如何:
是不是有点意思?这段代码帮我们自动启动 Chrome 浏览器,跳转到百度页面,然后再输入框中输入 “慕课网 wiki”,然后点击百度一下。在搜索的页面中选择第一个点击,进入到慕课网的 wiki 页面中。这整个过程就是由代码控制完成,没有人为操作,这是不是就是我们想象的自动化测试呢?自信点,就是这样的!
2. 基于 Selenium 完成发票认证
接下来,我们基于 Scrapy 和 Selenium 来完成笔者工作中的一个需求。我们每个月有一笔通信发票的报销,需要使用对自己在营业厅中买的发票进行校验,然后要截图留存。报销的时间有时候是3个月一次,有时候是半年,所以累积下来有不少发票,这些发票都需要校验和截图才能报销。
我们应届生刚工作的时候,我们大部分新员工都是手工截图,非常笨拙,且耗时。由于是搞技术的公司,于是有前端人员写了相关的前端插件来自动化截图和生成发票校验文档,然后在公司内广泛应用。我也写了这样一段基于 Selenium 的自动化截图代码,不过代码依赖 chrome 和 webdriver,所以组内的部分人会把发票的起始编号和张数发给我,我运行程序截好图后将图片打包发给他们自己放到 word 文档中去。
来看看发票校验的网站的截图如下:
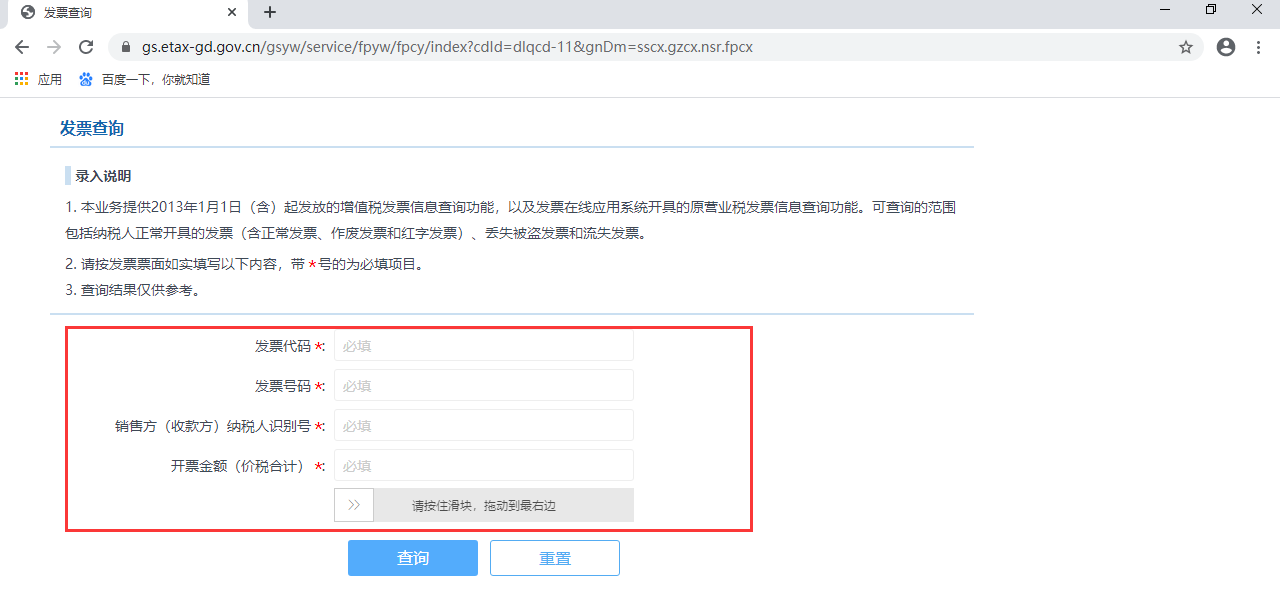
验证的方式非常机械,正是因为机械操作,才给了我们自动化的可能、看上图中的四个输入框,表示的含义分别为:
- 发票代码:固定值;
- 发票号码:通常而言,从移动营业厅拿的通信发票是连续的,这样就可以用 for 循环实现;
- 纳税人识别号:这个是个固定值;
- 发票面额:固定50元。假设我买300元的卡,就会对应6张发票;
我们填好每张发票的相应信息,只有一个变量。在查询之前,需要先拖动滑块进行验证,验证通过,再点击查询就可以进行认证。得到了认证结果后,截张图,如此进行下去,直到所有的发票都校验截图完毕。令人欣慰的是这里的滑块验证只需要做一次,得到了相应的认证截图后,每次调整下一张发票的发票号码,在截一张图即可。看下面的做法:
因此,我们得到了这样的机械化动作:
- 打开发票校验页面;
- 输入第一张发票的四个参数,然后拖动滑块到最右端完成校验;
- 截图留存;
- 改动第二个输入框的发票号码,为下一个发票编号,然后直接截图;重复,直到最后一张发票截图成功;
对应这样的动作我们翻译成相应的 Selenium 自动化代码如下:
"""
测试 selenium 工具
"""
import time
import random
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
# 固定值
ticket_code = "144011690802"
identification_number = "91440101618652334F"
face_value = 50
# 起始编号
ticket_start_num = 15415104
# 发票总数
total_count = 10
def click_space(driver):
"""
点击下空白处,使得输入框失去焦点
"""
driver.find_elements_by_xpath('//div[@class="check-main"]/table/tbody/tr[1]/td[1]')[0].click()
def fill_input(driver, idx):
"""
填充输入框
"""
input_value = [ticket_code, idx, identification_number, face_value]
table = driver.find_elements_by_xpath('//div[@class="check-main"]/table/tbody')[0]
for i in range(1, len(input_value) + 1):
input = table.find_elements_by_xpath(f'./tr[{i}]/td[2]/input')[0]
input.clear()
input.send_keys(input_value[i - 1])
click_space(driver)
def get_track(distance):
"""
参考文献2代码,模拟人移动鼠标
:distance为传入的总距离
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 3 / 5
# 计算间隔
t = 0.4
# 初速度
v = 1
while current < distance:
if current < mid:
# 加速度为一个随机值
a = random.randint(2, 6)
else:
# 加速度为一个随机负值
a = -1 * random.randint(1, 2)
v0 = v
# 当前速度
v = v0 + a * t
# 移动距离
move = v0 * t + 0.5 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
def move_to_gap(slider, tracks):
"""
参考文献2代码
:slider是要移动的滑块,tracks是要传入的移动轨迹
"""
action = ActionChains(driver)
action.click_and_hold(slider).perform()
for x in tracks:
ActionChains(driver).move_by_offset(xoffset=x,yoffset=0).perform()
time.sleep(0.1)
ActionChains(driver).release().perform()
# 发票校验地址
verify_address = "https://gs.etax-gd.gov.cn/gsyw/service/fpyw/fpcy/index"
# 想屏蔽selenium标识,避免被服务端检测到,似乎没起作用
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ['enable-automation'])
driver = webdriver.Chrome(options=options, executable_path="C:/Users/spyinx/AppData/Local/Google/Chrome/Application/chromedriver.exe")
driver.maximize_window()
# 第一步先去发票查询页面
driver.get(verify_address)
# 等待滑块出现
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, 'nc_1_n1z'))
)
# 填充输入框
fill_input(driver, ticket_start_num)
# 等待几秒后
driver.implicitly_wait(5)
# 找到滑动按钮,模拟鼠标按下不松开
slider = driver.find_element_by_id('nc_1_n1z')
move_to_gap(slider, get_track(300))
driver.implicitly_wait(2)
driver.find_element_by_id("CxBtn").click()
# 查询第一个需要滑动滑块
driver.get_screenshot_as_file(f"{ticket_start_num}.png")
for i in range(1, total_count):
ticket_num = ticket_start_num + i
fill_input(driver, ticket_num)
driver.get_screenshot_as_file(f"{ticket_num}.png")
driver.implicitly_wait(1)
上面的代码已经做好了详细的注释,请查找相关资料了解 Selenium 提供的相关方法,比如定位页面元素的方法、对页面元素点击(click)、输入框情况 (clear) 以及输入元素(send_keys) 以及鼠标的相关操作方法。下面我们直接来看代码的演示效果,最后的截图也全部得到。
注意:由于这个滑动验证码是接入的阿里滑动验证码插件,具备超强的反爬虫能力,能识别出是浏览器否被 selenium 控制。本次测试重复了无数次,才终于有一次没有出现滑块校验错误,才成功录下此视频。具体的可以搜索大神如何破解阿里的滑动验证码,不过大部分代码已经过时,无法突破验证。
总而言之,上面的操作是不是一定程度上能帮助我们减少手工操作,节约了时间成本?如果大家感兴趣的话,可以尝试使用 Selenium 完成京东商城的自动登录操作,这里会有滑动图片缺口补全的校验,会稍微有点复杂,对你们来说也是一个不错的挑战。
3. 小结
本小节中我们介绍了自动化工具 Selenuim 的使用, 同时结合 Scrapy 框架了完成了一个简单的案例。这个案例来源于笔者公司的一个小需求,学习好技术有时能给我们工作和生活带来许多意想不到的惊喜,这也是我们能不断追求技术的一个动力。
爬虫框架基础篇
Scrapy 爬虫框架介绍
使用 Requests 库请求网址
Scrapy 默认的网页解析器 Xpath
Redis 数据库的基本操作
MongoDB 数据库的基本操作
一个简单的爬虫实例:互动出版网爬虫
第一个基于 Scrapy 框架的爬虫
Scrapy 框架初级篇
Scrapy 运行架构与数据处理流程简介
Scrapy 框架的 Shell 工具使用
Scrapy 常用命令及其分析
Scrapy中的Request和Response
Scrapy 中的 Pipline 管道
Scrapy 中的中间件
Scrapy 配置介绍及常见优化配置
Scrapy 抓取起点中文网:实现登录和认证
Scrapy 抓取今日头条:抓取每日热点新闻
Scrapy 框架高级篇
网站反爬虫绕过技术分析
Splash 服务初体验
深入使用 Splash 服务
Selenium 自动化测试工具介绍
Scrapy与 Selenium 的结合使用
Scrapy 的分布式实现
Scrapy 框架源码篇
Twisted 框架基础
深入分析 Scrapy 下载器原理
深入理解 Scrapy 中间件
深入分析 Scrapy 的 Pipeline 原理
深入分析 crawl 命令的执行过程
代码预览
退出