深入分析 crawl 命令的执行过程
今天我们来跟踪学习 scrapy crawl spider_name 命令的执行过程,从这个过程中我们将看到 Scrapy 的引擎模块的作用。它是整个 Scrapy 其他模块共同的沟通主体,在 Scrapy 中处于核心模块的地位,可以说 Scrapy 的引擎模块就是它的大脑。本小节就让我们一起来探索 Scrapy “大脑” 的奥秘吧 !
1. Crawler 类及其相关类
我们先简单介绍下 Scrapy 中几个常用的基础类:Crawler、CrawlerRunner、CrawlerProcess。这些是我们分析 Scrapy 源码的基础知识点。
1.1 Crawler 类
# 源码位置:scrapy/crawler.py
# ...
class Crawler:
def __init__(self, spidercls, settings=None):
if isinstance(spidercls, Spider):
raise ValueError('The spidercls argument must be a class, not an object')
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.spidercls = spidercls
self.settings = settings.copy()
self.spidercls.update_settings(self.settings)
# 初始化一些属性
# ...
# 日志格式化类
lf_cls = load_object(self.settings['LOG_FORMATTER'])
self.logformatter = lf_cls.from_crawler(self)
# 扩展管理类
self.extensions = ExtensionManager.from_crawler(self)
self.settings.freeze()
self.crawling = False
# 爬虫模块
self.spider = None
# 引擎模块
self.engine = None
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
if self.crawling:
raise RuntimeError("Crawling already taking place")
self.crawling = True
try:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
# 获取初始下载请求
start_requests = iter(self.spider.start_requests())
# 调用引擎的open_spider()方法
yield self.engine.open_spider(self.spider, start_requests)
# 生成一个Deferred对象
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise
def _create_spider(self, *args, **kwargs):
# 实例化Spider类
return self.spidercls.from_crawler(self, *args, **kwargs)
def _create_engine(self):
# 生成引擎实例
return ExecutionEngine(self, lambda _: self.stop())
@defer.inlineCallbacks
def stop(self):
"""Starts a graceful stop of the crawler and returns a deferred that is
fired when the crawler is stopped."""
if self.crawling:
self.crawling = False
yield defer.maybeDeferred(self.engine.stop)
Crawler 类的属性比较丰富,方法较少,最核心的就是这个 crawl() 方法了。可以看到它其实就完成了以下几个动作:
- 获取初始的 Request 请求;
- 调用引擎的 open_spider() 方法;
- 将引擎的 start() 方法添加到 Deferred 对象中;
1.2 CrawlerRunner
该类有比较详细的注释,源码里对它的介绍如下:
这是一个简便的辅助类,用于跟踪、管理和运行已设置中的爬虫程序。
我们先来看该类的实例化方法:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerRunner:
# ...
@staticmethod
def _get_spider_loader(settings):
""" Get SpiderLoader instance from settings """
cls_path = settings.get('SPIDER_LOADER_CLASS')
# 导入spider loader类
loader_cls = load_object(cls_path)
excs = (DoesNotImplement, MultipleInvalid) if MultipleInvalid else DoesNotImplement
try:
verifyClass(ISpiderLoader, loader_cls)
except excs:
# 打印异常信息
# ...
return loader_cls.from_settings(settings.frozencopy())
def __init__(self, settings=None):
# scrapy全局配置
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.settings = settings
# 根据爬虫名,加载相应的Spdier类
self.spider_loader = self._get_spider_loader(settings)
# 用于保存所有的Crawler对象
self._crawlers = set()
# self._active用于保存调用Crawler.crawl()方法,返回的defer对象
self._active = set()
self.bootstrap_failed = False
self._handle_twisted_reactor()
注意比较重要的属性值有:
self.settings:保存了全局的配置信息;self.spider_loader:用于根据相应的爬虫名加载对应的 Spider 类;self._crawlers:用于保存所有的 Crawler 对象,使用的是 python 中的集合类型;
接下来我们看看该类中几个重要方法:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerRunner:
# ...
@property
def spiders(self):
# 打印告警信息
# ...
return self.spider_loader
def crawl(self, crawler_or_spidercls, *args, **kwargs):
if isinstance(crawler_or_spidercls, Spider):
# 抛出异常,不能是Spider对象,只能是Spider类或者Crawler对象
# ...
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
# 调用crawl()方法生成一个Deferred对象
d = crawler.crawl(*args, **kwargs)
# 加入活跃爬虫的集合
self._active.add(d)
def _done(result):
# 执行完后的收尾工作
self.crawlers.discard(crawler)
self._active.discard(d)
self.bootstrap_failed |= not getattr(crawler, 'spider', None)
return result
# 将_done()方法加入成功和失败的回调链中
return d.addBoth(_done)
def create_crawler(self, crawler_or_spidercls):
if isinstance(crawler_or_spidercls, Spider):
# 抛出异常,不能是Spider对象,只能是Spider类或者Crawler对象
# ...
if isinstance(crawler_or_spidercls, Crawler):
# 如果是Crawler实例
return crawler_or_spidercls
# 否则创建Crawler实例
return self._create_crawler(crawler_or_spidercls)
def _create_crawler(self, spidercls):
if isinstance(spidercls, str):
spidercls = self.spider_loader.load(spidercls)
# 返回Crawler实例
return Crawler(spidercls, self.settings)
上面的代码量都比较少,比较容易理解。不用纠结代码的细节,把握代码的作用即可,对于 Scrapy 框架有一个全貌即可。来简单描述下上面的方法:
crawl():爬虫开始执行爬取动作,crawl命令调用的入口方法;create_crawler():创建一个 Crawler 实例;
在看看这个类剩余的几个方法:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerRunner:
# ...
def stop(self):
return defer.DeferredList([c.stop() for c in list(self.crawlers)])
@defer.inlineCallbacks
def join(self):
while self._active:
yield defer.DeferredList(self._active)
def _handle_twisted_reactor(self):
if self.settings.get("TWISTED_REACTOR"):
verify_installed_reactor(self.settings["TWISTED_REACTOR"])
来简单说明下上面几个方法:
-
stop()和join()方法都是停止或者同步管理的爬虫,返回一个 Deferred 对象; -
_handle_twisted_reactor:默认配置中TWISTED_REACTOR的值为 None。其校验安装的 reactor 代码也比较简单,就是导入TWISTED_REACTOR路径对应的类,然后判断 twisted 中的 reactor 是否为该类的一个实例,不是就抛出异常:# 源码位置:scrapy/utils/reactor.py # ... def verify_installed_reactor(reactor_path): from twisted.internet import reactor # 导入reactor_path位置的类 reactor_class = load_object(reactor_path) # 判断twisted中的reactor是否为其实例 if not isinstance(reactor, reactor_class): # 抛出异常 # ...
到此,这个类的相关属性及方法就介绍完毕了,接下来我们学习它的一个子类:CrawlerProcess。
1.3 CrawlerProcess
该类用于在一个进程中同时运行多个 Scrapy 爬虫,它继承自上面的 CrawlerRunner 类。先学习其 __init__() 方法:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerProcess(CrawlerRunner):
def __init__(self, settings=None, install_root_handler=True):
# 调用父类的__init__()方法
super(CrawlerProcess, self).__init__(settings)
# 给一些信号设置相应的回调方法
install_shutdown_handlers(self._signal_shutdown)
# 初始化scrapy中默认的日志配置
configure_logging(self.settings, install_root_handler)
# 打印一些基本信息
log_scrapy_info(self.settings)
def _signal_shutdown(self, signum, _):
from twisted.internet import reactor
# 注册信号回调方法
install_shutdown_handlers(self._signal_kill)
signame = signal_names[signum]
# ...
reactor.callFromThread(self._graceful_stop_reactor)
def _signal_kill(self, signum, _):
from twisted.internet import reactor
install_shutdown_handlers(signal.SIG_IGN)
signame = signal_names[signum]
logger.info('Received %(signame)s twice, forcing unclean shutdown',
{'signame': signame})
reactor.callFromThread(self._stop_reactor)
# ...
可以看到 CrawlerProcess 类对象的初始化方法中先是调用父类的 __init__() 初始化相关属性,接着注册信号的回调方法,主要是终止信号。我们来看看这个 install_shutdown_handlers() 方法的代码:
# 源码位置:scrapy/utils/ossignal.py
# ...
def install_shutdown_handlers(function, override_sigint=True):
"""Install the given function as a signal handler for all common shutdown
signals (such as SIGINT, SIGTERM, etc). If override_sigint is ``False`` the
SIGINT handler won't be install if there is already a handler in place
(e.g. Pdb)
"""
from twisted.internet import reactor
reactor._handleSignals()
# 注册SIGTERM信号的回调
signal.signal(signal.SIGTERM, function)
if signal.getsignal(signal.SIGINT) == signal.default_int_handler or \
override_sigint:
signal.signal(signal.SIGINT, function)
# Catch Ctrl-Break in windows
if hasattr(signal, 'SIGBREAK'):
# 注册SIGBREAK信号的回调
signal.signal(signal.SIGBREAK, function)
可以看到,上面的代码就是一些注册信号的回调方法。接下来我们来看 CrawlerRunner 类中比较重要的几个方法:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerProcess(CrawlerRunner):
# ...
def start(self, stop_after_crawl=True):
from twisted.internet import reactor
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
resolver_class = load_object(self.settings["DNS_RESOLVER"])
resolver = create_instance(resolver_class, self.settings, self, reactor=reactor)
resolver.install_on_reactor()
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
reactor.run(installSignalHandlers=False) # blocking call
def _graceful_stop_reactor(self):
# 先调用stop()方法停止爬虫进程
d = self.stop()
# 最后回调停止reactor的方法
d.addBoth(self._stop_reactor)
return d
def _stop_reactor(self, _=None):
from twisted.internet import reactor
try:
reactor.stop()
except RuntimeError: # raised if already stopped or in shutdown stage
pass
# ...
来看这个 start() 方法,其中比较重要的就是调用了 reactor.run() 方法。_graceful_stop_reactor() 和 _stop_reactor() 从名字上就可以看出它们是关于停止 reactor 的方法。
2. crawl 命令追踪
现在我们要追踪前面多次使用的 scrapy crawl xxxx 命令的执行过程。根据前面的学习成果,我们知道 crawl 命令会调用 scrapy/commands/crawl.py 文件中 Command 类的 run() 方法:
# 源码位置:scrapy/commands/crawl.py
# ...
class Command(BaseRunSpiderCommand):
# ...
def run(self, args, opts):
# 没带参数或者带多了参数,抛出异常
# ...
# 获取爬虫名
spname = args[0]
# 核心是调用self.crawler_process执行爬取动作
crawl_defer = self.crawler_process.crawl(spname, **opts.spargs)
if getattr(crawl_defer, 'result', None) is not None and issubclass(crawl_defer.result.type, Exception):
# 如果结果异常或者没有结果,设置退出码为1
self.exitcode = 1
else:
# 调用self.crawler_process的start()方法
self.crawler_process.start()
if self.crawler_process.bootstrap_failed or \
(hasattr(self.crawler_process, 'has_exception') and self.crawler_process.has_exception):
self.exitcode = 1
首先我们从早先的调用代码中可以知道 self.crawler_process 其实是 CrawlerProcess 类的一个实例:
# 源码位置:scrapy/cmdline.py
# ...
def execute(argv=None, settings=None):
# ...
# 核心,设置command类的核心处理类
cmd.crawler_process = CrawlerProcess(settings)
# ...
这样命令的核心执行方法其实就是调用 CrawlerProcess 对象的 crawl() 方法。我们从一小节的学习中可知:CrawlerProcess 对象的 crawl() 方法其实是父类 (CrawlerRunner) 中的 crawl() 方法,且其调用的核心就两行语句:
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
这个 crawler 是 Crawler 类的一个实例,最后在调用 self._crawl() 方法时,通过代码可知该方法其实是调用 Crawler 对象的 crawl() 方法开始执行 Scrapy 爬虫程序:
# 源码位置:scrapy/crawler.py
# ...
class CrawlerRunner:
# ...
def _crawl(self, crawler, *args, **kwargs):
# ...
d = crawler.crawl(*args, **kwargs)
# ...
到此,我们知道 crawl 命令执行的核心方法其实是 Crawler 对象中的 crawl() 方法。 接下来,我们就是要从这个 crawl() 方法入手。
前面我们已经介绍过 crawl() 方法,该方法会先根据传入的爬虫名来创建 Spider 实例以及 Engine 实例:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
接着是得到起始的爬取 URL:
start_requests = iter(self.spider.start_requests())
这部分调用的正是 Spider 对象的 start_requests()方法获取初始的 URLs,我们也可以在自定义的爬虫中通过重写该方法来获取自定义的初始 URLs。
在接下来就是两个 yield 语句,这两句也是核心:
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
这样子,我们的跟踪目标就要转入到 Scrapy 源码的核心目录下了,其调用的是引擎模块中的两个方法,位于我们之前接触的 engine.py 文件中。来分别看着两个方法的代码:
# 源码位置: scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
if not self.has_capacity():
raise RuntimeError("No free spider slot when opening %r" % spider.name)
logger.info("Spider opened", extra={'spider': spider})
# 获取CallLaterOnce的实例,延迟调用一次
nextcall = CallLaterOnce(self._next_request, spider)
# 获取调度器
scheduler = self.scheduler_cls.from_crawler(self.crawler)
# 通过Spider中间件后,获取初始的urls,对应着数据流图的1
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
# 打开调度器
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
# 统计用的
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
# 延迟调用self._next_request()方法,内部使用reactor.callLater()方法实现
slot.nextcall.schedule()
slot.heartbeat.start(5)
看上面的代码,在 open_spider() 方法中我们可以看到,在我们调用的 Spider 对象中产生的起始请求在经过 Spider 中间件处理后再给回引擎模块;接着我们还会打开调度器以及爬取开关 (self.scraper.open_spider()) 和统计开关 (self.crawler.stats.open_spider())。
紧接着就是内部使用 reactor.callLater() 方法实现对 self._next_request() 方法的延迟调用:
# 源码位置:scrapy/utils/reactor.py
# ...
class CallLaterOnce:
"""Schedule a function to be called in the next reactor loop, but only if
it hasn't been already scheduled since the last time it ran.
"""
def __init__(self, func, *a, **kw):
self._func = func
self._a = a
self._kw = kw
self._call = None
def schedule(self, delay=0):
'''设置延迟调用'''
from twisted.internet import reactor
if self._call is None:
self._call = reactor.callLater(delay, self)
def cancel(self):
if self._call:
self._call.cancel()
def __call__(self):
# 在对象调用后,self._call设置为空,并调用方法
self._call = None
return self._func(*self._a, **self._kw)
# ...
看完上面的代码后,我们可知接下来就要进入 self._next_request() 方法中执行。继续来看该方法的代码:
# 源码位置:scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
def _next_request(self, spider):
slot = self.slot
# 不正确的情况,直接return
# ...
while not self._needs_backout(spider):
"""爬虫不需要返回,然后会从调度器获取下一个请求"""
if not self._next_request_from_scheduler(spider):
break
if slot.start_requests and not self._needs_backout(spider):
try:
request = next(slot.start_requests)
except StopIteration:
slot.start_requests = None
except Exception:
slot.start_requests = None
logger.error('Error while obtaining start requests',
exc_info=True, extra={'spider': spider})
else:
self.crawl(request, spider)
if self.spider_is_idle(spider) and slot.close_if_idle:
self._spider_idle(spider)
注意:一开始的调度器中并没有请求的 URLs,因此 _next_request() 方法每次调用时会从 start_requests 中获取请求,然后调用 self.crawl() 方法。我们来看看具体的 self.crawl() 方法的代码:
# 源码位置:scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
def crawl(self, request, spider):
if spider not in self.open_spiders:
raise RuntimeError("Spider %r not opened when crawling: %s" % (spider.name, request))
# 将请求加入调度器队列
self.schedule(request, spider)
# 继续调用self._next_request()方法
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signals.request_scheduled, request=request, spider=spider)
# 这里就是简单将请求压入调度
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signals.request_dropped, request=request, spider=spider)
这个代码就非常清楚了,self.crawl() 方法并不直接下载对应 url 的网页,而是将其推入调度器的下载队列,然后再调回 self._next_request() 方法 (对应着就是 self.slot.nextcall.schedule() 这一句)。而真正执行下载任务的代码为:
while not self._needs_backout(spider):
"""爬虫不需要返回,然后会从调度器获取下一个请求"""
if not self._next_request_from_scheduler(spider):
break
这段代码会循环从调度器中获取下一个请求,如果没有则跳出循环往下执行。如果有请求,则会执行 self._download() 方法去下载对应的网页,而这个方法正是在第24节中介绍过的下载网页的入口。
另外,我们还剩下一个 yield 没介绍,就是引擎的启动:yield defer.maybeDeferred(self.engine.start)。该方法比较简单,就是记录下起始时间以及设置 self.running 标志:
# 源码位置:scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
@defer.inlineCallbacks
def start(self):
"""Start the execution engine"""
if self.running:
raise RuntimeError("Engine already running")
# 记录引擎开始执行时间
self.start_time = time()
# 发送引擎执行信号
yield self.signals.send_catch_log_deferred(signal=signals.engine_started)
# 设置running标识
self.running = True
self._closewait = defer.Deferred()
yield self._closewait
来总结下 crawl 命令的执行流程:
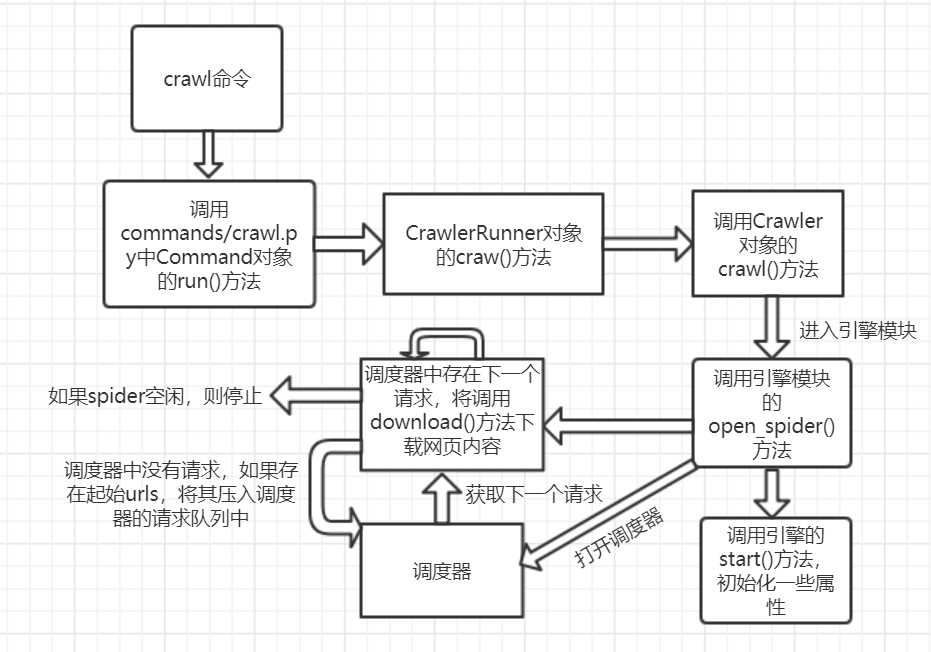
对于 crawl 命令的追踪到这里就结束了。当然,这里我们还有一些内容没有介绍到,比如调度器如何实现请求的入队、出队等,再比如 Spider 模块和 Engine 模块的交互过程等,这些就留给读者课后继续探索了。
3. 小结
本小节中我们主要介绍了 scrapy/crawler.py 文件中的代码以及追踪了 scrapy crawl xxx 命令的执行过程。通过追踪这个命令,我们可以了解 Scrapy 爬虫的整个运行流程,回过头来在看 Scrapy 的架构图以及数据流图,是不是又多了一份理解与认识?当然,对于 Scrapy 框架源码我们还有许多代码没有介绍到,比如 scrapy 的扩展模块 (scrapy/extensions)、链接抽取模块 (scrapy/linkextractors)。这些部分并不属于 Scrapy 的核心部分,也不是学习 Scrapy 的重点,读者有兴趣可以课后认真研究这些模块的代码,以增强对 Scrapy 框架的认识。好了,整个 Scrapy 框架的的介绍到此就结束了,我们青山不改,江湖再会!