1. 前言
Redis 相对于传统的关系型数据库(例如 MySQL )而言,还具有设置过期时间的特性,在项目实战中,我们经常关心的三元组是 {key,value,expire_time}。这里的过期时间(expire_time)是的具体执行方式,涉及到 Redis 的缓存过期策略。
2. 缓存过期策略
面试官提问: Redis 里的 Key 超过失效时间,是如何处理的呢?
题目解析:
首先,我们要明白缓存过期的目的是为了在 Key 超过 expire_time 后,从内存中删除,减少内存空间的占用。其次,要分析不同策略的定义、优点和缺点。Redis 的过期策略主要有三种实现方式:
(1)定时删除:
- 定义:对于每一个有过期时间的 Key,创建一个定时器,到过期时间立即删除;
- 优点:保存内存可以尽快释放,减少过期 Key 对内存空间的占用;
- 缺点:占用大量的 CPU 资源去处理定时器,影响缓存的吞吐量,这和 Redis 设计追求性能的设定不符,所以一般不会采用这种策略。
(2)惰性删除:
- 定义:过期的 Key 不做处理,只有当访问这个 Key 时才会判断是否过期,过期则清除;
- 优点:删除操作只有在访存的时候才可能执行,对 CPU 的占用做到了最小。
- 缺点:如果内存中大量的 Key 均过期,且一段时间内没有被访问,会占用大量内存。
(3)定期删除:
- 定义:每隔一段时间全量扫描设置了过期时间的 Key,如果失效则从内存中删除,否则不做处理;
- 优点:通过限制定时的频率,来减少对 CPU 的占用和对内存的占用;
- 缺点:作为一种折中的方案,在内存友好方面,不如定时删除策略;在 CPU 友好方面,不如惰性删除。使用时的表现非常依赖配置的定期频率。
3. 内存淘汰机制
面试官提问: Redis 的内存淘汰机制有哪些,能枚举说明吗?
题目解析:
我们需要注意,缓存过期策略和内存淘汰机制是容易混淆的两个概念,两者的目的不同。
- 缓存过期策略:针对过期 Key ,从内存中移除的方式。
- 内存淘汰机制:针对 Redis 内存不足时,业务还在继续往 Redis 追加内容,如何处理已有的内容。
在 Redis 的 redis.conf 文件中,我们能找到八种可配置的内存淘汰机制:
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key;
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key;
- volatile-lfu:当内存不足以容纳新写入数据时,在过期密集的键中,使用 LFU 算法进行删除 key;
- allkeys-lfu:当内存不足以容纳新写入数据时,对所有的 key 执行 LFU 算法筛选过期;
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期的键中,随机删除一个 key;
- allkeys-random:当内存不足以容纳新写入数据时,随机删除一个或者多个 key;
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除;
- noeviction:当内存不足以容纳新写入数据时,新写入操作直接报错,无法写入。
上述算法按照特性可以分为几类:LRU/LFU 算法、随机删除算法、优先淘汰历史数据算法、报错处理算法。
在项目中推荐两种 LRU 算法,即如果 Redis 用作持久化数据库,不配置缓存过期时间,采用 allkeys-lru ;如果 Redis 作为缓存数据库,配置了 Key 过期时间,采用 volatile-lru 算法。
4. LRU 算法
面试官提问: 缓存过期的 LRU 算法原理是什么?
题目解析:
既然在 Redis 中谈到了 LRU ,就不可避免解释其原理。LRU(Least Recently Used,最近最少使用算法)是最常见的缓存淘汰算法,核心思想是 "如果数据最近被访问过,那么将来被访问的可能性也更高"。
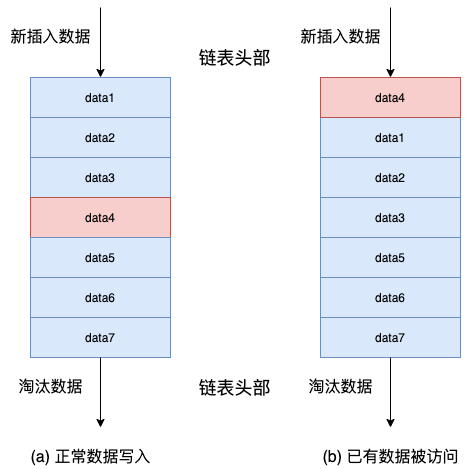
LRU 算法的核心步骤在于:
- 新数据直接插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将被命中的数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
从性质上总结,越靠近链表头部的数据越是不容易被淘汰,越靠近链表尾部的数据越是容易淘汰。
5. 小结
本章介绍了 Redis 缓存过期策略和内存淘汰策略,需要大家区分两种策略解决的问题,同时需要针对 LRU 算法原理进行说明,必要性能够做到手写 LRU 算法的伪代码。