1. 前言
在小型项目中(例如大部分 toB 业务),Redis 被作为缓存,我们无需过多关注缓存的性能,但是对于高并发的场景(例如 toC 的在线电商业务),在商品秒杀或者库存抢购的时候,Redis 也可能存在诸多潜在的问题,例如缓存穿透、缓存雪崩。
2. 缓存问题
2.1 缓存穿透
面试官提问: Redis 的缓存穿透是什么意思?有什么解决方案?
题目解析:
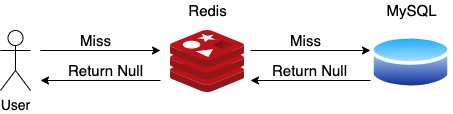
首先给出缓存穿透的定义:用户查询一个本来在数据库就没有的数据,导致每次请求要首先从缓存中查找,发现没有之后再从持久化数据库(例如 MySQL)中查找,最后返回空的过程。比如针对一个不存在的 user_id 查询用户信息,请求每次都会击穿缓存打到数据库上。
然后分析缓存穿透的危害:因为持久化数据库的读能力普遍低于缓存,缓存穿透越多,缓存命中率越低,这类请求可能被黑客利用从而打垮数据库。
针对缓存穿透问题,业界有一些公认的解决方案:
(1)缓存空值:第一次查询,在缓存和数据库均查不到数据,我们将 key=user_id,value=null 这个键值对放入缓存,并且设置一个短期过期时间(例如 10 分钟);第二次以及过期时间内的查询,流量会命中缓存,并且返回空结果。
这是最简单粗暴的方法,如果对缓存的存储数据有严格要求,一般不采用这种方案。
(2)预置布隆过滤器:布隆过滤器存储缓存中所有的 key ,请求打进来之后,首先经过布隆过滤器过滤,如果不存在,直接在该层拦截
请求,请求流量不会打到缓存以及数据库。如果存在,则走正常的缓存、数据库查询逻辑。

2.2 缓存雪崩
面试官提问: Redis 的缓存雪崩是什么意思?有什么解决方案?
题目解析:
正如上文的分析,缓存的核心作用是为底层数据库挡住大部分的外部流量,减轻数据库的压力。
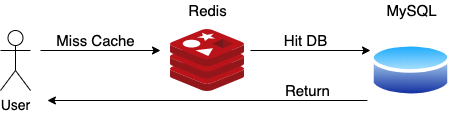
如果缓存因为某种原因失效,例如 Redis Server 宕机或者在某个时间段大量的缓存 Key 过期,原本被缓存过滤的流量会直接打到数据库上,给数据库造成压力,严重情况下可能导致数据库宕机。
预防缓存雪崩也有多种方案:
(1)保证 Redis 的高可用,例如搭建 Redis Cluster,维护多集群。
(2)对服务请求进行限流,例如使用 Java 的 Hystrix 库,Hystrix 能够提供熔断、限流、降低三种手段保证当极端情况发生时,打到数据库的请求流量不会超过数据库的承受能力。
- 熔断:Hystrix 记录某个接口的请求失败率,当失败率过高之后,拒绝后续请求,直接给出一个预设返回值;
- 限流:当请求 QPS 超过缓存的能力或者预先计算的上限后,将后续的的请求放入缓存队列,防止请求高并发打进业务逻辑代码;
- 降级:对于被拒绝访问的请求,直接返回一个预设结果。降级最常见的应用例子是,电商秒杀的场景,当并发数超过业务服务能够承受的阈值后,请求直接被网关层拦截,返回 "当前人数太多,请稍后重试" 的提示文案。
总结来说,预防缓存雪崩的本质方案有:
- 加锁:加锁只是为了降低并发打到数据库的流量,并没有提高系统的吞吐量,当有 100 个用户请求过来时,每次只能处理 1 个请求,用户体验差,生产环境基本不使用加锁方案;
- 队列:Hystrix 限流的本质就请求放入缓存队列,依次请求,生产环境必备方案;
- 拒绝服务:当请求超过队列能够处理的范畴后,直接拦截用户请求,用户体验也差,一般是生产环境的兜底方案。
3. 小结
本章节介绍了使用 Redis 作为缓存容易遇到的两大问题,缓存穿透和缓存雪崩。需要区分的是,缓存穿透是针对单个 Key 而言,缓存雪崩是多个 Key 失效,两者产生的原因也不同。