1. 前言
除了计算机网络、操作系统等基础知识的考察,各种流行的中间件也深受面试官的青睐。之前的章节已经对缓存中间件的代表 Redis 的面试题进行了分析,本章节将介绍常用的消息中间件,即 RabbitMQ 的基础定义以及使用原因。
2. 消息队列使用场景
面试官提问: 为什么要使用消息队列?能说说消息队列解决了什么问题?
题目解析:
任何工具都有诞生的背景,例如非关系型数据库是为了解决性能以及扩展性问题产生。
常见的消息队列有 RabbitMQ、RocketMQ、Kafka 等,消息队列也是针对特定问题有不同的使用场景,可以抽象为异步处理、应用解耦、流量削峰三种场景。
2.1 异步处理 & 应用解耦
以最常见的在网站注册新用户场景为例,如果经过了基本的业务逻辑之后,要通过短信和邮件的方式验证是否用户本人注册,每个流程的请求响应耗时为 100ms,在同步的方式下总共需要耗时 300ms。

其中发送验证短信以及发送验证邮件两个步骤并没有强制的先后依赖关系,所以同步请求的效率相对较低,使用消息队列可以将验证短信和邮件的模块拆开,经过消息队列中转分发请求,假设消息队列的读写时间为 20ms,总流程的耗时被优化到 220ms。
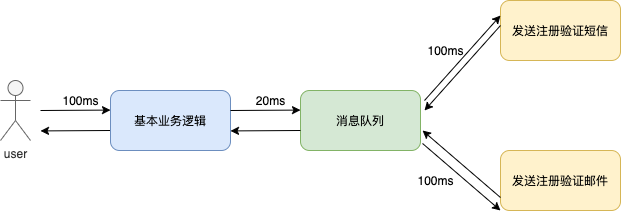
上述异步请求的过程本质上也是应用解耦的过程,最基础的应用架构中可以将短信注册模块和邮件注册模块都可以耦合在注册业务逻辑中,但是如果有其他的服务也需要使用短信注册功能,就只能调用注册业务的短信模块接口。此时,程序的鲁棒性相对较差,当注册业务模块的服务器宕机之后,会造成所有服务的短信模块都不可用,所以需要将短信模块解耦出来,同理,邮件模块也需要被拆分为单独的服务。候选人需要注意一点,这种拆分本质上都是为了应用服务的高可用。
2.2 流量削峰
互联网存在很多高并发场景,例如在 12306 抢购春运火车票,或者阿里淘宝的双十一秒杀活动,系统服务在短时间收到大量的用户请求,如果数据库不能抗住相对日常的 N 倍流量被打垮,会导致服务不可用。为了避免这种情况发生,有熔断、降级、以及流量削峰等多种解决方案,消息队列是最常见的流量削峰方案。
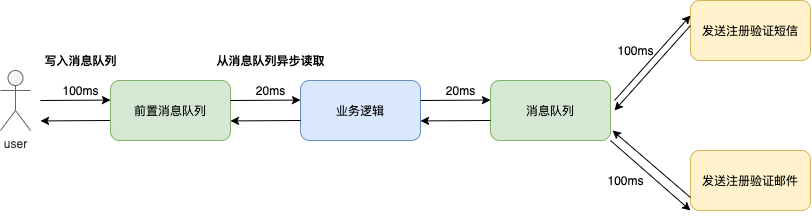
还是以用户注册的例子,例如在双十一凌晨时间,大量新用户通过活动链接进入了网站的注册页面,在收到用户请后后,首先将请求写入消息队列,如果请求数量超过消息队列的容量,那么多余的请求直接放弃并且跳转到错误页面,这也是常用的降级方案。
业务代码从消息队列中拿到用户请求,再进行后续的业务逻辑。消息队列在用户和业务逻辑中之间作为中间件模块,防止大量流量直接打到底层数据库。
3. 常用消息队列
面试官提问: 常用的消息队列有哪些?
题目解析:
最常见的消息队列有 ActiveMQ、RabbitMQ、RocketMQ 以及 Kafka,我们一般关注的是 RabbitMQ 以及 Kafka,我们关注基本定义以及两者之间的特性差别。
- RabbitMQ:基于 Erlang 语言开发的消息发布和订阅系统,基于 AMQP 协议实现。AMQP 协议一般在对数据一致性要求高、对性能要求较低的场景使用;
- Kafka:LinkedIn 公司开源的消息发布和订阅系统,一般在对数据一致性要求较低、海量数据的处理场景中使用。
下面对比分析下两种消息队列的特性差异。
3.1 吞吐量对比
- RabbitMQ:单机吞吐量在万级别,比 Kafka 低一个数量级;
- Kafka:单机吞吐量在十万级别,数据的存储和读取都是依靠本地硬盘的顺序读写,处理效率高。
3.2 应用场景对比
- RabbitMQ:企业内部微服务,例如内部人员管理系统的消息通讯场景。因为基于 Erlang 开发语言,对小型企业来说,开发维护成本相对较高;
- Kafka:大数据系统中常用,例如日志处理以及数据实时分析场景,目前 Kafka 几乎是日志采集场景的首选消息队列。
4. 小结
本章节介绍了消息队列的基本使用场景,需要理解消息队列的核心是异步处理以及解耦能力。我们对比了 RabbitMQ 和 Kafka 两种消息队列的特性,在后续的章节主要会对 RabbitMQ 的常见题目进行分析。