RabbitMQ 死信队列基础概念与配置概述
1. 前言
Hello,大家好。本小节会为同学们介绍 RabbitMQ 中的死信队列及其基础配置。死信队列作为 RabbitMQ 中最后一个特性,其在实际工作中发挥着重要的作用。本节会从死信队列的前置概念开始,到死信队列的基础概念,最后介绍死信队列的基本使用方法和基本配置结束,详细介绍死信队列的基础概念和基本使用方法。
话不多说,让我们直入正题吧。
本节主要内容:
-
死信队列前置概念概述;
-
死信队列基础概念概述;
-
死信队列基本使用概述;
2. 死信队列前置概念概述
在正式介绍死信队列的基础概念之前,需要同学们先了解一些死信队列的前置概念,这些前置概念是后续理解死信队列的基础,同学们只有对这些前置概念有一个理解之后,才能很好地理解什么是死信队列。
什么是队列:
队列并不是只存在于 RabbitMQ 中,队列是一种计算机领域中的基本数据结构,其描述了数据在计算机内存中垂直分布的特点。 我们可以把队列看做是我们日常生活中排队做核酸的场景:当有一个人去做的时候,这个时候没有队伍,直接做就行了;当有十个人去做的时候,这个时候就需要排队了,而排队的这个过程就是队列形成的过程。
当再有人需要去做的时候,这个人只能排在队尾,不能够插队,而队前的人由于比队尾的人先到,所以队前的人就比队尾的人先做核酸,以此反复这个过程,直到所有人都做完核酸为止。
而队列描述的就是这样的场景,在上述例子中,形成队伍的过程就是我们的应用数据入队的过程,先入队的数据可以先被处理,而后入队的数据只能等待前入队的数据处理完毕之后才能进行处理,这就是队列先入先出的特点。
假设我们有 6 条数据需要入队,以下是数据入队过程:
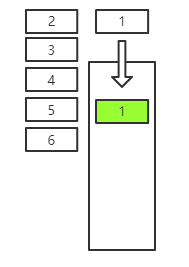
1 号数据会先入队,然后排在 1 好数据后面的 2 3 4 5 6 好数据会依次入队,入队完成后的队列如下图所示:
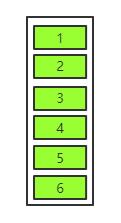
说白了,队列就是数据按照固定的排列方式在计算机中存储的一种表现形式,而队列中的数据处理原则就是先入队的数据先进行处理,后入队的数据后进行处理。RabbitMQ 中的队列也是一样的,只不过这些队列里面存储的都是被称为消息的数据,所以这些队列被称为消息队列, 即在 RabbitMQ 中,根据消息类型的不同,会形成很多不同类型的队列,但是这些队列归根到底,其本质依然是消息队列。
什么是死信:
我们知道,在 RabbitMQ 中充当主角的就是消息,在不同场景下,消息会有不同地表现。死信就是消息在特定场景下的一种表现形式,这些场景包括:消息被拒绝访问,即 RabbitMQ Server 返回 nack 的信号时、消息的 TTL 过期时、消息队列达到最大长度,消息不能入队时。
经常产生死信的场景就是上述三种场景,即消息在这三种场景中时,被称为死信。
3. 死信队列基础概念概述
通过前置概念的介绍,我们知道了死信的基础的概念,那么死信队列又是什么呢?
结合上述对队列基础概念的介绍,我们不难得出:死信队列就是用于储存死信的消息队列,在死信队列中,有且只有死信构成,不会存在其余类型的消息,这就是死信队列。
死信队列在 RabbitMQ 中并不会单独存在,往往死信队列都会绑定这一个普通的消息队列,当所绑定的消息队列中,有消息变成死信了,那么这个消息就会重新被交换机路由到指定的死信队列中去,我们可以通过对这个死信队列进行监听,从而手动的去对这一消息进行补偿。
那么,我们到底如何来使用死信队列呢?
4. 死信队列基本使用概述
在 RabbitMQ 中,死信队列的标识为 x-dead-letter-exchange ,通过观察死信队列的标识,我们不难发现,其标识最后为 exchange ,即 RabbitMQ 中的交换机,没错,RabbitMQ 中的死信队列就是由死信交换机而得出的。
要想使用死信队列,我们需要首先声明一个普通的消息队列,并将死信队列的标识绑定到这个普通的消息队列上, 这个过程需要我们在生产端进行配置,代码如下所示:
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("xx");
connectionFactory.setPort("5672");
connectionFactory.setVirtualHost("/");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChanel();
Map<String, Object> argumentsMap = new HashMap();
argumentsMap.put("x-dead-letter-exchange", "dlx_exchange");
channel.exchangeDeclare("dlx_common_exchange", "direct", true, false, null);
channel.queueDeclare("dlx_common_queue", true, false, false, argumentsMap);
channel.queueBind("dlx_common_queue", "dlx_common_exchange", routingKey);
代码解释:
第 1-5 行,我们使用 ConnectionFactory 创建了一个客户端连接 RabbitMQ Server 的连接。
第 6 行,我们使用建立好的连接,来创建了一个频道 channel 。
第 7-8 行,我们声明了一个普通队列的额外参数的 Map ,这个 Map 的 key 就是死信队列的标识,value 就是我们后续声明的真正的死信交换机的名称。
第 9-10 行,我们依次使用 channel 的 exchangeDeclare 方法和 queueDeclare 方法,分别声明了一个名为 dlx_common_exchange 的交换机和名为 dlx_common_queue 的普通消息队列,之所以名称中有 common ,是因为要对这个交换机和队列做一个标识,表示该交换机和队列是绑定了死信队列的。
第 11 行,我们使用 channel 的 queueBind 方法来讲声明的普通交换机和消息队列进行绑定,并且制定了 routingKey ,这样消息就可以经 dlx_common_exchange 根据 routingKey 来路由到 dlx_common_queue 中。
在我们声明了要绑定死信队列的普通队列之后,最后我们需要声明真正的死信队列,代码如下所示:
// 省略客户端连接 RabbitMQ Server 的过程
channel.exchangeDeclare("dlx_exchange", "direct", true, false, null);
channel.queueDeclare("dlx_queue", true, false, false, null);
channel.queueBind("dlx_queue", "dlx_exchange", routingKey);
代码解释:
第 1 行,我们使用 chanel 的 exchangeDeclare 方法来声明了一个名为 dlx_exchange 的交换机。
第 2 行,我们使用 channel 的 queueDeclare 方法来声明了一个名为 dlx_queue 的队列。
第 3 行,我们使用 channel 的 queueBind 方法,来将 dlx_exchange 的交换机与 dlx_queue 队列进行了绑定。
当我们完成上述过程之后,死信队列就配置完成了,这也是死信队列的基本使用方法。
Tips: 1. 从声明死信队列的代码段中,我们不难看出,我们所声明的交换机和队列也都是普通的,只不过我们声明的这个交换机和队列是用来存储 dlx_common_queue 队列中的死信的;
2. 死信队列的使用在实际工作中非常重要,它可以帮助我们对那些异常的消息进行监控,并根据这些监控信息制定相应的消息补偿策略,这点同学们注意;
3. 一定要注意在声明普通队列时,我们声明的名为 argumetsMap 的变量,这个是绑定死信队列的关键。
5. 小结
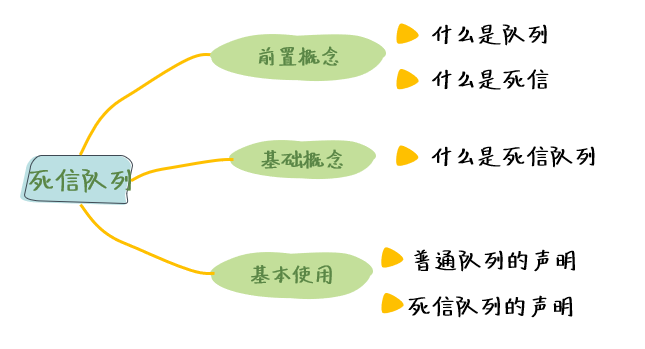
本小节为同学们介绍了 RabbitMQ 中,死信队列的前置概念、死信队列的基础概念,以及死信队列的基本使用。我们只有在了解了死信队列的前置概念之后,我们才能理解死信队列的基础概念,同时,我们只有清楚的明白了应用死信队列的步骤,我们才能正确的用好死信队列。
死信队列在实际工作中使用频率非常高,希望同学们可以清楚地理解本节中的基础概念和代码实现,这些都是应用死信队列基础中的基础,望同学们注意。