使用RabbitMQ优化用户注册功能
1. 前言
Hello,大家好。在上个小节中,我们对传统的用户登录功能做了基本的流程介绍,以及使用 RabbitMQ 伪代码对传统的用户登录功能进行了优化。
考虑到用户登录功能往往会和用户注册功能同步出现,所以,本小节会为同学们介绍,如何使用 RabbitMQ 消息中间件,去优化我们使用传统的方式,来实现的用户注册的功能点,包括对传统用户注册功能的概述,以及使用 RabbitMQ 进行优化的关键步骤,希望同学们可以对本节内容有所了解。
本节主要内容:
-
传统用户注册功能概述;
-
使用 RabbitMQ 优化传统用户注册功能。
2.传统用户注册功能概述
2.1 传统实现方案介绍
和用户登录功能那样,在我们现在的信息化系统项目中,项目的首要功能模块,基本上都会要求我们来设计并实现一个完备的用户模块,而这个用户模块中,必定会包含用户注册与用户登录功能点。
只有在项目中实现了用户注册与用户登录这两个最基本的功能点,我们的项目功能才能继续向后进行开发,因为项目后续的功能,或多或少都会与这两个功能点相联系。
所以,这就要求我们在实现用户注册与用户登录功能时,要从多方面进行考虑, 如果有一点我们没有考虑到,很可能在进行项目后续功能开发时,还要回过头去,修改这两个基本功能,从而与项目后续的功能相结合。
那么,传统的用户注册功能的实现方案是什么样的呢?
传统用户注册功能流程介绍
传统的用户注册功能,其实和传统的用户登录功能差别并不大,我们首先接触用户注册功能,大部分的同学都是在自己学校的实验课上,都是通过老师讲授的方式来对用户注册功能有所了解,但是,这种实现方式都会存在诸多问题,下面让我们来看一下这种方式是如何实现的。
对于用户注册功能来说,我们从事后端开发的同学,我们首先需要接收前端传递过来的数据,也就是用户的注册数据,然后我们会根据这一用户注册数据来进行相应的逻辑检验。
这些逻辑校验包括对用户所填写的注册用户名、邮箱、手机等用户唯一关键信息属性的校验。如果用户所填写的用户名在系统中已经存在了,那么用户就不能使用该用户名进行注册了,邮箱和手机则同理,这里不再赘述。
在对注册用户名、注册邮箱,以及注册手机进行唯一性校验之后,我们还需要对用户所填写注册邮箱和注册手机号进行逻辑合法校验,即用户所填写的邮箱到底是不是一个可用的邮箱,以及用户所填写的手机到底是不是一个可用的手机号。下面,我们来通过一个功能流程图来体现上述的业务流转过程:
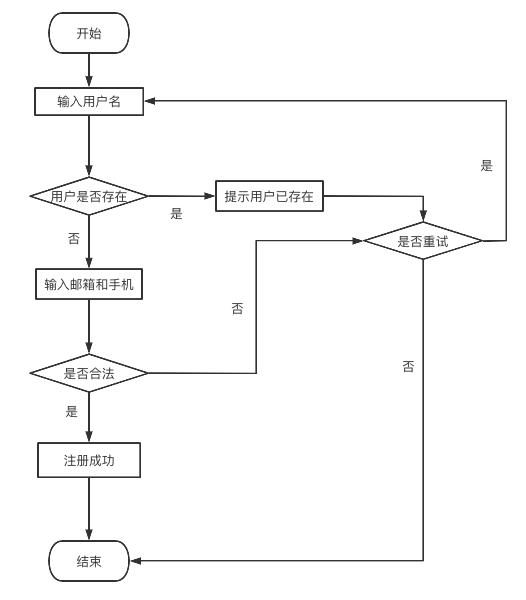
通过上述功能流程图,我们可以很清楚地理解上述传统用户注册功能的实现过程,如果没有理解的同学,建议多看几次,理解这一流程之后我们再继续学习下面的内容。
传统用户注册功能代码实现
以 SpringBoot 框架为例,我们来实现一下上述的用户注册功能,实现代码如下所示:
实现代码:
public Response<String> userRegister(User registUser){
int userExistsCount = userMapper.selectUserExixtsByUsername(registUser.getUsername());
if (userExistsCount > 0){
return Response.createByError("用户已存在");
}
int userEmailCount = userMapper.selectUserEmailByUsernameEmail(registUser.getUsername(), registUser.getEmail());
if (userEmailCount > 0){
return Response.createByError("邮箱已存在");
}
int userPhoneCount = userMapper.selectUserPhoneByUsernamePhone(registUser.getUsername(), registUser.getPhone());
if (userPhoneCount > 0){
return Response.createByError("手机已存在");
}
int userRegist = userMapper.insert(registUser);
if (userRegist > 0){
return Response.createBySuccess("用户注册成功");
}
return Response.createByError("系统错误,用户注册失败");
}
代码解释:
第 1 行,我们定义了一个名为 userRegister 的方法来处理用户注册的业务逻辑,该方法的返回值是 Response 类型,并且泛型被指定为 String 类型,这表明,我们的方法最终会返回注册业务逻辑的字符串数据。
与用户登录方法不同,在该方法中,我们只需要定义一个参数,那就是 User 类型的 registUser 参数。该参数负责接收前端传递到后台的用户注册数据,并且程序会根据这个数据做一些逻辑判断。
第 2-24 行,我们分别使用了不同的数据库查询方法,来分别对用户的注册用户名、注册邮箱,以及注册手机进行了逻辑唯一性校验,即检测这些关键字段属性是不是已经存在于系统中了,如果系统中已经有了,那表明,可能当前需要注册的用户已经注册过了,不能重复注册。
第 25-30 行,如果前面的逻辑校验都通过,那么我们就要使用 MyBatis 自带的 insert 方法,将这一合法的用户注册数据,插入到我们的数据库中所对应的用户数据表中,并且在数据插入数据库成功之后,提示用户,当前用户已经注册成功了。
如果在将用户注册数据插入到数据库的过程中,出现了任何问题,导致用户注册数据无法插入到数据库中,则提示当前注册的用户:系统错误,用户注册失败。此时,需要等待系统管理员解决。
Tips: 1. 在用户所填写的用户注册数据通过逻辑检验时,我们应该将用户注册数据插入到我们的数据库中,而不是直接放入到缓存中去,否则,我们刚刚注册的用户是无法进行登录的;
2. 传统的用户注册功能,在用户注册成功之后,我们不需要将用户注册成功的数据进行返回,或者进行一个状态的处理,这点需要同学们注意;
3. 在将用户注册数据插入到数据库的过程中,我们使用了 MyBatis 自带的 insert 方法,同学们可以了解一下这个 insert 方法的作用。
通过上述代码的编写,我们基本上实现了传统的用户注册功能,但是这种注册功能是最简单的实现,完全没有考虑其他因素,如果我们在实际项目中这样来实现,那么在开发后续功能时,必定会出现一些意料之中的问题。
那么,我们采用这种实现方式所实现的用户注册功能到底有哪些弊端呢?下面就让我们一探究竟。
2.2 传统实现方案中存在的弊端
和用户登录功能相似,我们传统的实现用户注册功能的业务逻辑还是正确的, 不管我们再怎么对用户注册功能进行优化,这个传统的用户注册功能业务流程始终不会发生改变,发生改变的只是我们的代码实现层。
那么,传统实现方案中存在的弊端,也就存在于我们的功能代码实现层上。
传统用户注册功能中存在的弊端,整体来说,最核心的也就只有一种弊端了。
那就是,无论我们的用户注册功能所在的场景是不是在高并发环境中,都会直接对我们的数据库的访问压力造成较高的冲击, 如果在高并发环境中,我们的数据库可能会随着用户注册请求数量的激增,而直接崩溃,这是非常致命的一点。
我们先来说非高并发环境下,用户注册数据在逻辑检测通过之后,会直接访问我们的数据库,并将用户注册数据插入到我们的数据库中,正常环境下我们的数据库还是能扛得住的,但是,即使能扛得住,数据库的压力在此时也是较高的。
那么,在高并发环境下,由于我们没有在用户数据和数据库之间做处理,这就导致,当大量请求都在同一时刻到来时,我们的数据库的压力会直线上升,并最终导致数据库崩溃,这会直接造成我们的用户注册功能直接卡死,无法完成用户注册功能。
针对这种情况,我们又该如何优化呢?下面就让我们来看一下,如何使用 RabbitMQ 来优化这一弊端。
3 使用 RabbitMQ 优化传统用户注册功能
我们注意到,对于用户注册功能而言,无论是在普通环境,还是在高并发环境,我们的传统逻辑,都是在用户注册数据校验正确后,直接地将用户数据插入到数据库中,中间并没有一层过渡的措施。
正是由于我们缺少这一措施,我们的数据库压力才会持续升高,而这一持续升高的结果,和普通环境和高并发环境并没有太大的本质因素,所以,我们的优化重点就放在了这一中间措施上面。
针对这一问题,我们同样的有两种角度可以考虑:
角度一:使用缓存承载中间压力
在众多缓存中间件中,使用频率和普适度最高的,要数 redis 缓存中间件了。
对于用户注册而言,当用户提交的注册数据通过了我们的逻辑校验之后,我们可以使用 redis 来将该用户注册数据进行存储,并在一个固定的时间内,将位于 redis 缓存中的用户注册数据,同步插入到我们的数据库中, 这样既可实现 redis 缓存数据与数据库数据之间的同步。
与此同时,当我们添加了 redis 缓存中间件之后,我们所对应的用户登录功能也要进行相应的调整,即从之前用户登录时,对数据库所做的校验,换做优先对 redis 缓存中的用户注册数据进行校验。
Tips: 在将用户注册数据存入 redis 缓存中间件前,我们应该设置好我们的 redis 缓存 key 值的生成策略,目的就是将不同业务场景所对应的 key 值进行区分。
当我们这样设置之后,合法的用户注册数据会被优先存储到 redis 缓存中间件中,然后,在某一固定时间周期内,系统会自动将 redis 缓存中间中的数据同步到我们的数据库中,这样一来,我们的 redis 缓存中间件就承担了大部分的数据库压力。
这是第一种优化思路,接下来让我们看第二种优化思路,即通过消息队列来分发数据,从而减少数据库的压力。
角度二:采用消息队列分发数据压力
此种优化措施,就需要使用我们的 RabbitMQ 了。
在角度一中所提到的优化措施,在很多业务场景中是没有大问题的,但是在高并发环境下,会出现一个问题,那就是由于数据同步的延迟,导致的用户无法登录的问题。 所以,当用户注册功能处于高并发环境下时,我们必须要使用 RabbitMQ 消息队列来进行优化了。
我们都知道,高并发环境下的请求数量是非常多的,那么,对于一个用户注册功能接口而言,在高并发环境下接收的用户请求也是非常多的。
我们可以使用 RabbitMQ 来作为一个消息队列,当合法的用户注册数据需要插入数据库时,我们可以将数据发送到我们的 RabbitMQ 的消息队列中去,然后我们定义的消费者会从消息队列中获取并消费该数据。
当消费者将消息队列中的用户注册数据进行消费之后,我们可以将这一数据直接插入到数据库中,无须经过角度一中提到的 redis 缓存中间件层,因为我们的 RabbitMQ 消息队列已经对数据压力进行了分发。
即,当有一个用户注册请求需要处理时,RabbitMQ 就会在消息队列中存储这个请求所对应的合法的用户注册数据,并在消息进行消费之后,再将数据进行持久化存储。
这样一来,通过集成 RabbitMQ 消息队列,将用户注册时的数据压力通过消息队列进行分发,从而达到减小数据库压力的目的。
我们来简单看下这种问题的优化代码,优化代码如下所示:
实现代码:
public Response<String> userRegister(User registUser){
int userExistsCount = userMapper.selectUserExixtsByUsername(registUser.getUsername());
if (userExistsCount > 0){
return Response.createByError("用户已存在");
}
int userEmailCount = userMapper.selectUserEmailByUsernameEmail(registUser.getUsername(), registUser.getEmail());
if (userEmailCount > 0){
return Response.createByError("邮箱已存在");
}
int userPhoneCount = userMapper.selectUserPhoneByUsernamePhone(registUser.getUsername(), registUser.getPhone());
if (userPhoneCount > 0){
return Response.createByError("手机已存在");
}
boolean isAck = false;
rabbitTemplate.convertAndSend("userRegistQueue", "user.register", user);
// 省略消费者消费数据过程 isAck = true;
if(isAck) {
int userRegist = userMapper.insert(registUser);
if(userRegist > 0) {
return Response.createBySuccess("用户注册成功");
}
return Response.createByError("系统错误,用户注册失败");
}
return Response.createByError("系统错误,用户注册失败");
}
代码解释:
第 1-19 行,像传统用户注册那样,我们对用户所提交的注册数据进行了校验,直到用户的注册数据通过了我们的逻辑检测为止。
第 20 行,我们声明了一个 boolean 类型的变量 isAck ,并且将他的默认值设为了 false ,该变量表示我们的消息是否已经被消费了。
第 21 行,我们使用 rabbitTemplate 的 convertAndSend 方法,将合法的用户注册数据发送到 RabbitMQ 的消息队列中去,等待消费者消费。
第 22 行,我们对 isAck 进行了检测,当消费者成功从消息队列中获取并消费了用户注册数据的消息之后,isAck 标志位会被置位 true 。
第 23-28 行,如果 isAck 标志位为 true ,则将用户注册数据插入到我们的数据库中,并提示用户注册成功,如果用户数据在插入数据库过程中遇到问题,导致数据无法插入,则提示用户:系统错误,用户注册失败。
由于消费者的实现比较复杂,考虑到篇幅原因,所以在这里代码就没有给出。
Tips: 使用 RabbitMQ 消息队列去优化用户注册功能时,一定要根据上述代码片段的先后顺序来进行优化,特别是使用 RabbitMQ 代码部分,同学们注意。
4. 小结
本小节为同学们详细介绍了传统的用户注册功能的基本概念和基本实现方法,以及在传统的用注册功能中所出现的可优化的问题,针对核心问题,我们分别介绍了不同问题的不同优化措施,并针对可以使用 RabbitMQ 进行优化的场景,我们使用了 Spring 生态中的 RabbitMQ 中的方法来进行了优化。