-
 码上有媳妇
码上有媳妇
- 这markers[idx]的值不对.不知道好像哪里还有问题.
注意loc函数的端点是闭区间
- 2021-08-30 1回答·899浏览
-
 慕瓜957411
慕瓜957411
- 课程文档在哪里下载?
- 2021-06-07 0回答·718浏览
-
 qq_慕无忌9118984
qq_慕无忌9118984
- error
#注意看我y和X这两行的注释:要么全是df.loc,要么全是df.iloc,核对一下自己代码
import matplotlib.pyplot as plt
import numpy as np
y = df.loc[0:100, 4].values #loc/iloc得统一
y = np.where(y == 'Iris-setosa', -1, 1)
#抽出第0列和第2列
X = df.loc[0:100, [0, 2]].values # loc/iloc得统一
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('花瓣长度')
plt.ylabel('花茎长度')
plt.legend(loc='upper left')
#plt.show()- 2021-06-03 1回答·817浏览
-
 putao398728
putao398728
- 数据显示问题
 fdfdfd
fdfdfd- 2021-02-04 2回答·932浏览
-
putao398728
- 老师您好,请问数据在哪里获得
数据文件(iris.data.csv):https://graph-bed-1256708472.cos.ap-chengdu.myqcloud.com/pythondata%2Firis.data.csv
- 2021-02-04 1回答·917浏览
-
 慕运维9029871
慕运维9029871
- 源代码下载
- 2020-11-03 0回答·927浏览
-
 qq_慕仔6550724
qq_慕仔6550724
- 这两个错误怎么解决呀,在线求助,急
- 2020-10-07 0回答·639浏览
-
 慕移动7343345
慕移动7343345
- ‘’self‘’ is not defined name什么鬼?
你代码写错了
- 2020-07-27 1回答·1066浏览
-
 Du1in9
Du1in9
- 报错'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB
两行code解决问题,只显示error级别的通知
from matplotlib.axes._axes import _log as matplotlib_axes_logger matplotlib_axes_logger.setLevel('ERROR')- 2020-07-20 1回答·2551浏览
-
 慕慕9595314
慕慕9595314
- 上式中的z(i)中的i怎么理解?
可以理解为每一层神经网络的权重的集合
- 2020-02-10 1回答·1301浏览
-
 耿雨
耿雨
- 运行了没有任何结果
这两天把这里 机器学习_实现简单神经网络 看完了,错误代码比较多,新手不太懂,比较费时间
提供下 项目仓库 地址:https://git.imooc.com/xinjian/AdalineGD.git
有需要的同学可以去看看- 2020-02-07 1回答·967浏览
-
慕慕9595314
- 没有讲ppn相关的内容
ppn = Perceptron(eta=0.1, n_iter=10) ppn.fit(X, y) plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') plt.xlabel("Epochs") plt.ylabel("error count") plt.show()from matplotlib.colors import ListedColormapdef plot_decision_region(X, y, classifier, resolution=0.02): marker = ('s', 'x', 'o', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') # len(np.unique(y)=2 cmap = ListedColormap(colors[:len(np.unique(y))]) # 花茎的长度 x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() # 花瓣的长度 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() print(x1_min, x1_max) print(x2_min, x2_max) # (备注) xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) # 输出语句 print(np.arange(x1_min, x1_max, resolution).shape) print(np.arange(x1_min, x1_max, resolution)) print(xx1.shape) print(xx1) print(np.arange(x2_min, x2_max, resolution).shape) print(np.arange(x2_min, x2_max, resolution)) print(xx2.shape) print(xx2)# 执行语句plot_decision_region(X, y, ppn, resolution=0.02)备注: 将np.arange()中的向量扩展成一个矩阵 a = np.arange(x1_min, x1_max, resolution) 向量元素为185个 xx1[255, 185],将a中的元素作为一行,重复255行 b = np.arange(x2_min, x2_max, resolution) 向量元素为255个 xx2[255, 185],将b中的元素作为一列,重复185列
谢谢采纳~
- 2020-02-07 4回答·1688浏览
-
 石明昊
石明昊
- 缺少的那一节
我也用的python3.7,这是我的代码,谢谢采纳~
import numpy as np class Perceptron(object): # 注释1 def __init__(self, eta = 0.01, n_iter = 10): self.eta = eta self.n_iter = n_iter def fit(self, X, y): # 注释2 self.w_ = np.zeros(1 + X.shape[1]) self.errors_ = [] for _ in range(self.n_iter): errors = 0 # 注释3 for xi, target in zip(X, y): update = self.eta * (target - self.predict(xi)) # 注释4 self.w_[1:] += update * xi self.w_[0] += update errors += int(update != 0.0) self.errors_.append(errors) def net_input(self, X): # 注释5 return np.dot(X, self.w_[1:]) + self.w_[0] def predict(self, X): return np.where(self.net_input(X) >= 0.0, 1, -1)
注释1: eta:学习率 n_iter:权重向量的训练次数 w_:神经分叉权重向量 errors_:用于记录神经元判断出错次数 注释2: 输入训练数据,培训神经元,X是输入样本向量,y是对应的样本分类 X:shape[n_samples, n_features] 比如:X:[[1, 2, 3], [4, 5, 6]] 那么:n_samples: 2,n_features: 3,y:[1, -1] 初始化权重向量为0,加1是因为提到的w0,即步调函数的阈值 注释3: 比如:X:[[1, 2, 3], [4, 5, 6] 所以y:[1, -1],zip(X, y):[[1, 2, 3, 1]. [4, 5, 6, -1]] update = n * (y - y') 注释4: xi是一个向量 update * xi等价于:[ w1 = x1*update, w2 = x2*update, ...] 注释5: z = w0*1 + w1*x1 + w2*x2 + ... np.dot()是做点积
- 2019-11-20 1回答·1265浏览
-
 qq_莫非
qq_莫非
- 阈值和权重的区别是什么?
- 已采纳 慕移动2103324 的回答
真正的w是权重,阈值是权重与输入点积后的一个评判标准,只是为了计算方便,才人为的将它记为w0,放在了点积计算中。
原公式是w1*x1 + w2*x2 + ... + wm*xm ?>= 阈值,两边同时加上阈值的相反数,左边就变成了w1*x1 + w2*x2 + ... + wm*xm - 阈值 ?>= 0,再人为的定义“-阈值”记为“w0”,就变成了现在这个样子。(我打不出阈值的那个符号,就先用中文代替下吧)
- 2019-10-24 2回答·3854浏览
-
 慕神2257579
慕神2257579
- 跟着老师打的,可是为什么会报错NameError: name 'X' is not defined?
x小写
- 2019-10-21 1回答·2587浏览
-
 qq_老六_2
qq_老六_2
- 我同样的问题,报错“”Perceptron object has no attribute predict“,如何解决啊?急急急
把predict函数拿出来,和fit函数并列
- 2019-09-25 2回答·1833浏览
-
 慕娘9054796
慕娘9054796
- 输入样本的正确分类y怎么得到的?
- 2019-09-22 3回答·1048浏览
-
慕神2257579
- 'Perceptron' object has no attribute 'predict'
predict函数和fit函数对齐就可以了。刚刚才发现的。
- 2019-09-03 1回答·2602浏览
-
 Mrsls
Mrsls
- 让图形在单独的窗口中显示
这个要用自适应的窗口来处理
- 2019-08-06 1回答·1100浏览
-
 慕粉8371238
慕粉8371238
- 后面的dot(X,w_[i])是个什么操作?
- 2019-07-29 2回答·944浏览
-
 叶程序
叶程序
- 为什么where()里面要>=0.0而不是大于等于w[0]呢,不是每次都要更新阈值吗????
w[0]其实就是bias, net_input(x)的结果就是最终样本权值计算的结果,predict就是作者说的激活函数,函数的y值是[-1,1]
- 2019-04-06 1回答·1401浏览
-
 KiKi00
KiKi00
- 最后结果图像不一样呀
from matplotlib.colors import ListedColormap
from matplotlib.colors import ListedColormap def plot_decision_region(X, y, classifier, resolution=0.02): colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) z = classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T) z = z.reshape(xx1.shape) plt.contourf(xx1, xx2, z, alpha=0.4, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.xlim(xx2.min(), xx2.max()) plt.scatter(X[:50,0],X[:50,1],color='red',marker='o',label='setosa') plt.scatter(X[50:100,0],X[50:100,1],color='blue',marker='x',label='versicolor') # 执行语句 plot_decision_regions(X,y,ppn,resolution=0.02) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.xlabel('花茎长度') plt.ylabel('花瓣长度') plt.legend(loc='upper left') plt.show()- 2019-03-30 2回答·1454浏览
-
 qq_燕窝_2
qq_燕窝_2
- typeerror
设置的类型不对呀
- 2019-03-11 1回答·905浏览
-
qq_燕窝_2
- dimension is 100 but corresponding boolean dimension is 101
将y = df.loc[0:100, 4].values改为y = df.iloc[0:100, 4].values
看出区别了吗?loc前面多个i。不然y的维度为101。
当然你也可以直接改成y = df.loc[0:99, 4].values
- 2019-03-11 2回答·2782浏览
-
 YMLiu
YMLiu
- 和方差求偏导公式中的小问题
同问,
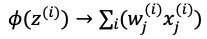 中的求和下标应该为j
中的求和下标应该为j因为
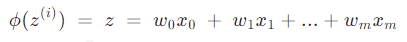
- 2019-03-11 3回答·1700浏览
-
 慕慕5364095
慕慕5364095
- 关于w0第一次更新的问题
知道啦。
这个学习过程其实就是在算θ的过程
- 2019-03-08 1回答·1284浏览
-
 qq_时间太快_0
qq_时间太快_0
- 为什么会这样啊
self.errors就是每个实例所对应的属性
- 2019-02-26 1回答·1217浏览
-
 慕工程1492897
慕工程1492897
- pnn训练没讲
看看你的定义初始化函数 def __init__;
你可能写成了def __int__
- 2019-02-21 2回答·1866浏览
-
慕工程1492897
- classifier是什么?找不到对它的定义啊
他就是一个参数变量,代表类对象,感知器算法中是一个Perceptron对象,适应性神经元算法中是一个AdlineGD对象。
- 2019-02-21 1回答·1419浏览
-
慕工程1492897
- 这句有问题吗?
for _ in range(self.n_iter):
errors = 0
- 2019-02-20 1回答·1013浏览























