-

- 神话锦 2022-11-14
查询
简单查询
查询id号
条件查询
查询满足条件的数据
聚合查询
查询满足条件的数据的统计结果
- 0赞 · 0采集
-

- weixin_慕瓜3590361 2021-09-04
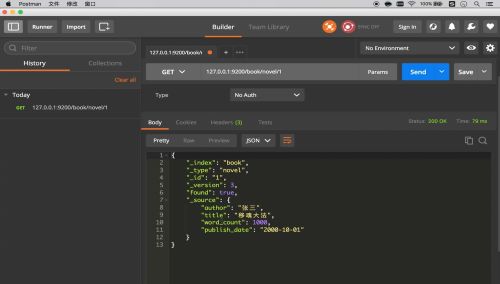
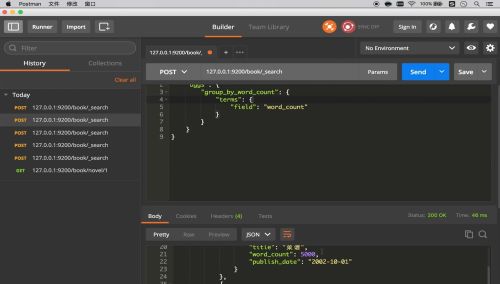
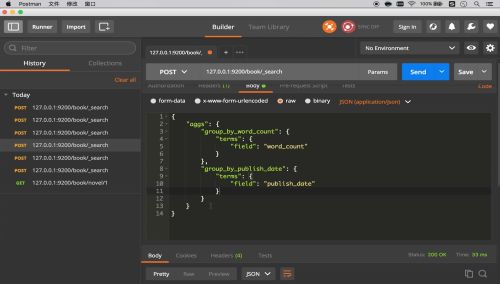
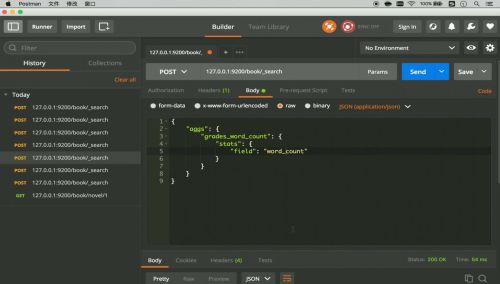
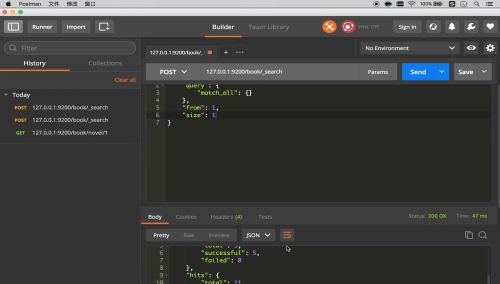
简单查询
条件查询
聚合查询




- 0赞 · 0采集
-

- 正是在下 2021-07-12
elasticsearch
查询,按id 查询

查询所有数据

查询具体数量的数据

关键词查询

排序

聚合查询
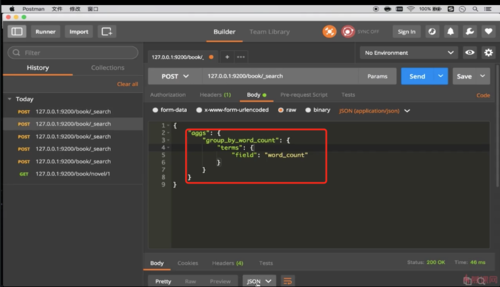
多个聚合条件

结果


- 0赞 · 1采集
-

- 芒果椰汁丶 2021-05-24
post 查询都需要有 query 字段表示查询参数,以下表示查询所有:

// 增加查询参数 "from":指定从哪里返回 "size":返回几条数据
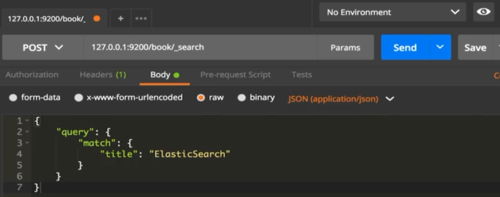
查询标题为 ElasticSearch 的数据
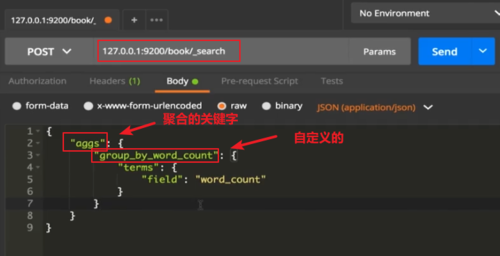
聚合查询(aggs:聚合查询关键词)
把书籍信息按字数聚合
- 0赞 · 0采集
-

- 叶0528 2021-04-23

PUT http://127.0.0.1:9200/book/novel/9
{
"author":"很胖瓦力",
"title":"ElasticSearch精通",
"word_count":3000,
"publish_date":"2017-08-15"
}
- 0赞 · 0采集
-

- dou桠 2021-01-30
- 三种查询
-
截图0赞 · 0采集
-

- 慕粉2344332688 2020-06-25
aggs: {
stats: {
}
}
- 0赞 · 0采集
-

- 慕少7339756 2020-02-19
聚合查询
数学统计:最大最小值等
-
截图0赞 · 0采集
-
- 慕少7339756 2020-02-19
聚合查询(aggregation) group_by
-
截图0赞 · 0采集
-
-
- 慕少7339756 2020-02-19
用from 和 size,规定返回的数据的开头和个数
-
截图0赞 · 0采集
-
- 慕少7339756 2020-02-19
查询返回结果
took: 花费时间
hits: 结果内容
hits.total: 查询结果总数量
hits.hits: 结果数组,默认只返回10条
hits.hits._id: document id
hits.hits._version: document 版本号
hits.hits._source: 具体数据(document),不包含id
-
截图0赞 · 0采集
-
- 慕少7339756 2020-02-19
条件查询:查询全部数据
-
截图0赞 · 0采集
-
- 慕少7339756 2020-02-19
按id查询
-
截图0赞 · 0采集
-

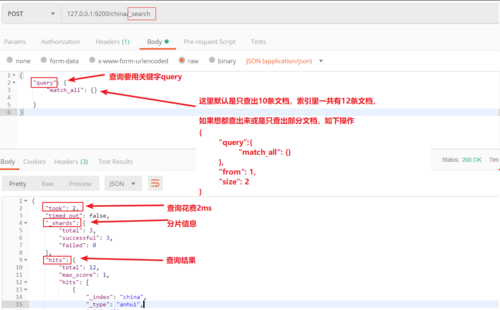
- xy856890 2019-12-25
ES中的查询用法2


- 0赞 · 0采集
-
- xy856890 2019-12-25
ES中的查询用法1


- 0赞 · 0采集
-

- 慕用1426806 2019-11-17
聚合查询:
- "aggs" 是聚合查询的关键词,类似 MySQL 的 group,返回的聚合信息在 response body 的 "aggregations" 字段中
- "aggs" 中还可以使用很多函数,如 stats,min 等
-
截图0赞 · 0采集
-
- 慕用1426806 2019-11-17
条件查询排序
-
截图0赞 · 0采集
-
- 慕用1426806 2019-11-17
条件查询-带查询条件
-
截图0赞 · 0采集
-
- 慕用1426806 2019-11-17
条件查询的 Body1
-
截图0赞 · 0采集
-
- 慕用1426806 2019-11-17
查询分类:
- 简单查询:GET http://<ip>:<port>/index/type/id
- 条件查询:POST http://<ip>:<port>/index/_search
- 复合查询
- 0赞 · 0采集
-

- 匪曰思存 2019-11-05
hits默认返回十条数据。
- 0赞 · 0采集
-

- 霜花似雪 2019-11-02
ES简单查询
-
截图0赞 · 0采集
-

- 慕粉4558069 2019-08-26
- 查询 match matchall
-
截图0赞 · 0采集
-

- Loistein 2019-08-19
查询
简单查询
GET 127.0.0.1:9200/book/novel/1
条件查询
POST 127.0.0.1:9200/book/_search
返回所有
{
"query":{
"match_all":{}
}
}
返回第几条到第几条数据
{
"query":{
"match_all":{}
},
"from":1,
"size":1
}
关键字查询:
{
"query":{
"match":{
"title":"ElasticSearch"
}
}
}
指定排序规则:
{
"query":{
"match":{
"title":"ElasticSearch"
}
},
"sort":[
{"publish_date":{"order":"desc"}}
]
}
聚合查询
按照列名称聚合
{
"aggs":{
"group_by_word_count":{
"terms":{
"field":"word_count"
}
},
"group_by_publish_date":{
"terms":{
"field":"publish_date"
}
}
}
}
返回统计值,比如最大、最小、平均值
{
"aggs":{
"grades_word_count":{
"stats":{
"field":"word_count"
}
}
}
}
返回最小值
{
"aggs":{
"grades_word_count":{
"min":{
"field":"word_count"
}
}
}
}
- 1赞 · 0采集
-

- 慕尼黑7108623 2019-04-05
ES查询关键字query.
match匹配查询条件
sort自定义排序条件
-
截图0赞 · 1采集
-

- qq_有梦想的民工_0 2019-04-02
查询 简单查询 get /novel/1 条件查询 post 聚合查询 post { "age":{ "group_by_word_count":{ "terms":{ "field":"word_count" } }, "group_by_publish_date":{ "terms":{ "field":"publish_date" } } } }- 0赞 · 1采集
-

- DataTime 2018-11-30
基础概念
集群:是一组具有相同cluster.name的节点的集合,他们协同工作,共享数据并提供故障转移和扩展功能,一个节点也可以组成一个集群。
节点:是一个运行着的elastic search的实例。
索引:类似于关系数据库中的数据库,它是我们存储和索引关联数据的地方。

聚合:允许你在数据上生成复杂的分析统计。
文档:它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasticsearch中),文档不仅有数据,它还包含了元数据,三个必须的元数据节点如下:

分片:
备份:
基本用法
使用RESTFul API风格
API基本格式:http://<ip>:<port>/<索引>/<类型>/<文档id>
常用HTTP动词:GET/PUT/POST/DELETE
创建索引
数据(插入、修改、删除、查询)
- 0赞 · 0采集
-

- 北极的大企鹅 2018-11-17
添加数据:
1、http://localhost:9200/book/novel/1
{
"doc":{
"word_count": 1000,
"author":"张三",
"title": "移魂大法",
"public_date": "2010-10-01"
}
}
2、http://localhost:9200/book/novel/2
{
"doc":{
"word_count": 2000,
"author":"李三",
"title": "Java入门",
"public_date": "2010-10-01"
}
}
3、http://localhost:9200/book/novel/3
{
"doc":{
"word_count": 2000,
"author":"张四",
"title": "Python入门",
"public_date": "2005-10-01"
}
}
4、http://localhost:9200/book/novel/4
{
"doc":{
"word_count": 1000,
"author":"李四",
"title": "Elasticsearch大法好",
"public_date": "2010-10-01"
}
}
5、http://localhost:9200/book/novel/5
{
"doc":{
"word_count": 5000,
"author":"王五",
"title": "菜谱",
"public_date": "2002-10-01"
}
}
6、http://localhost:9200/book/novel/6
{
"doc":{
"word_count": 10000,
"author":"赵六",
"title": "剑谱",
"public_date": "1997-01-01"
}
}
7、http://localhost:9200/book/novel/7
{
"doc":{
"word_count": 1000,
"author":"张三丰",
"title": "太极拳",
"public_date": "1997-01-01"
}
}
8、http://localhost:9200/book/novel/8
{
"doc":{
"word_count": 3000,
"author":"瓦力",
"title": "Elasticsearch入门",
"public_date": "2017-08-20"
}
}
9、http://localhost:9200/book/novel/9
{
"doc":{
"word_count": 3000,
"author":"很胖的瓦力",
"title": "Elasticsearch精通",
"public_date": "2017-08-15"
}
}
10、http://localhost:9200/book/novel/10
{
"doc":{
"word_count": 1000,
"author":"牛魔王",
"title": "芭蕉扇",
"public_date": "2000-10-01"
}
}
11、http://localhost:9200/book/novel/11
{
"doc":{
"word_count": 1000,
"author":"孙悟空",
"title": "七十二变",
"public_date": "2000-10-01"
}
}
- 4赞 · 6采集
-

- EternalPolaris 2018-09-23
聚合函数聚合
-
截图0赞 · 1采集




























