-

- 慕斯卡6411321 2023-11-26
结论部分记在这里
- 0赞 · 0采集
-

- 慕少7339756 2023-08-01

逻辑回归,不需要指定 函数(线性、几次方、指数等)
code: https://github.com/hanbingjiao/ML-Python3-LogisticRegression-Demo/
- 0赞 · 0采集
-

- 小小程序员一枚 2020-07-14
CSV 下载地址:https://github.com/weiwanling/TensorFlow_Experiment/tree/1241a064d780cdcf278e4f8edec0f7bbd9bc0aea
- 0赞 · 0采集
-

- Lady_Eva14 2020-07-13
通过多个角度看模型评估的好坏
- 0赞 · 0采集
-

- lpxx 2020-05-23
绘制图表,进行数据可视化
pandas:基础数据分析套件
scikit-learn:强大的数据分析建模库
keras:人工神经网络
- 0赞 · 0采集
-

- 慕雪2383124 2020-02-28
下载数据集遇到的问题:Kaggle网站注册用户刷不出验证界面。这里需要安装谷歌访问助手,百度一下有很多解答。
- 0赞 · 0采集
-

- jingleYao 2020-02-17
import pandas as pd
path = 'data/pima-indians-diabetes.csv'
pima=pd.read_csv(path)
pima.head()
#X,y赋值
feature_name=['pregnant','insulin','bmi';age']
X = pima[feature_names]
y =pima.label
#确认维度
print(X.shape)
print(y.shape)
#数据分离
from sklearn.model_selection import train_test_split
X_trian,X_test,y_train,y_test = train_test_split(X,y,random_state=0)
#模型训练
from sklearn.linear_model import logisticregression
logReg = logisticRegression()
logReg.fit(X_train,y_train)
y_pred = logReg.predict(X_test)
from sklearn import metric
print("metrics.accuracy_score(y_test,y_pred)
##确认正负样本的数据量以及空准确率
y_test.value_counts()
y_test.mean()
1-y_test.mean()
max(y_test.mean(),1-y_test.mean())
#展示部分书记结果与预测结果
print(y_test.value[0:25]
pritn(y_pred[0:25]
#计算并展示混淆矩阵
confusion = metrics.confusion_metrix(y_test,y_pred)
#四个因子赋值
TN = confusion[0][0]
FP = confusion[0][1]
FN = confusion[1][0]
TP = confusion[1][1]
#指标计算
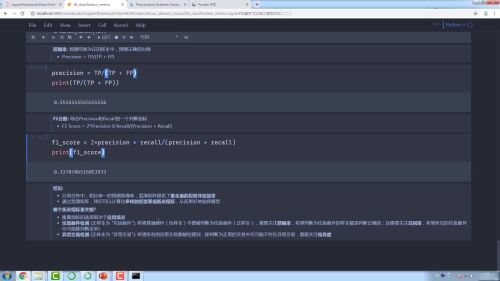
accuracy = (TP+TN)/(TP+TN+FP+FN)
mis_rate =(FP+FN)/(TP+TN+FP+FN)
recall =TP/(TP+FN)
specificity =TN(TN+FP)
precision = TP/(TP+FP)
f1_score = 2*precison*recall/(precision+recall)
-
截图2赞 · 1采集
-

- 爱慕课啊 2019-09-30
皮马印第安人糖尿病数据:https://www.kaggle.com/uciml/pima-indians-diabetes-database
本地下载:https://nico.cc/softs/pima-indians-diabetes-database.zip
- 2赞 · 6采集
-

- cmn6415772 2019-09-08
- 讲解很耐心,很清晰,一步步开始到结束。期待老师的下个课程
- 1赞 · 1采集








