
The two most important days in your life are the day you are born and the day you find out why.
-- Mark Twain
“你是谁?从哪里来?到哪里去?”,这三个富有哲学气息的问题,是每一个人在不断解答的问题。我们Code,Build,Run,一个活生生的App跃然方寸屏上,这一切是如何发生的?从用户点击App到执行main函数这短短的瞬间发生了多少事呢?探寻App的启动新生,可以帮助我们更了解App开发本身。
下图是App启动流程的关键节点展示:
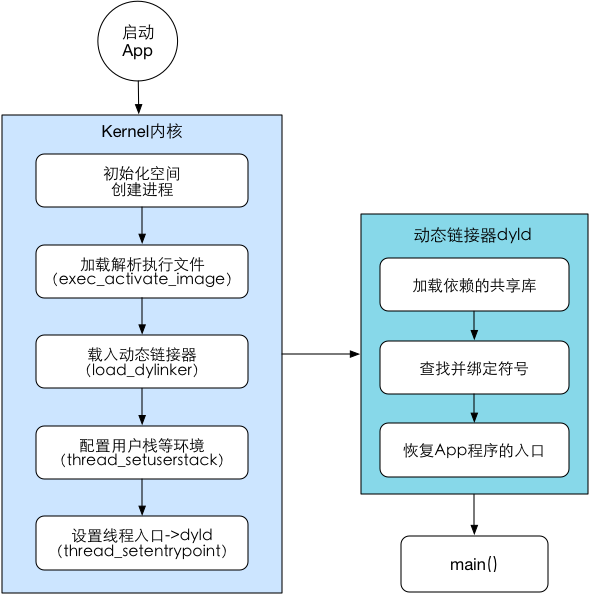
下面我们就来一一解读。
1. App文件的组成
在详细研究启动流程之前,首先我们需要了解下iOS/OSX的App执行文件
一个应用,通常都是经过“编译-》链接-》打包”几个步骤之后,生成一个可在某平台上运行应用。应用文件在不同的平台上以不同的格式存在,如Windows上的exe,Android上的pkg,以及我们接下来要说的ipa。
iOS系统是由OS X发展而来,而OS X是由NeXTSTEP与Mac OS Classic的融合。因此iOS/OS X系统很多的特性都是源于NeXTSTEP系统,如Objective-C、Cocoa、Mach、XCode等,其中还有应用/库的组成——Bundle。Bundle的官方解释是 a standardized hierarchical structure that holds executable code and the resources used by that code. ,也就是包含执行代码和相关资源的标准层次结构;可以简单地理解为包(Package)。
OS X应用和iOS应用两者的bundle结构有些许差别,OS X的应用程序的层次结构比较规范,而iOS的App则相对来说比较散乱,而且与OS不同的是,iOS只有Apple原生的应用才会在 /Applications 目录下,从App Store上购买的应用会安装在 /var/mobile/Applications 目录下;OSX的应用不再本文讨论范围之内,所以我们先来看看iOS的App Bundle的层次结构:
-bit GUID/ xxxx.app/ Documents/ iTunesArtwork iTunesMetaData.plist Library/ tmp/
其中xxx.app就是我们的app应用程序,主要包含了执行文件(xxx.app/xxx, xxx为应用名称)、NIB和图片等资源文件。接下来就主要看看本节的主角: Mach-O
1.1 Universal Binary
大部分情况下,xxx.app/xxx文件并不是Mach-O格式文件,由于现在需要支持不同CPU架构的iOS设备,所以我们编译打包出来的执行文件是一个Universal Binary格式文件(通用二进制文件,也称胖二进制文件),其实Universal Binary只不过将支持不同架构的Mach-O打包在一起,再在文件起始位置加上Fat Header来说明所包含的Mach-O文件支持的架构和偏移地址信息;
Fat Header的数据结构在<mach-o/fat.h>头文件上有定义:
#define FAT_MAGIC 0xcafebabe#define FAT_CIGAM 0xbebafeca /* NXSwapLong(FAT_MAGIC) */struct fat_header {
uint32_t magic; /* FAT_MAGIC */
uint32_t nfat_arch; /* number of structs that follow */};struct fat_arch {
cpu_type_t cputype; /* cpu specifier (int) */
cpu_subtype_t cpusubtype; /* machine specifier (int) */
uint32_t offset; /* file offset to this object file */
uint32_t size; /* size of this object file */
uint32_t align; /* alignment as a power of 2 */};结构 struct fat_header :
1).
magic字段就是我们常说的魔数(与UNIX的ELF文件一样),加载器通过这个魔数值来判断这是什么样的文件,胖二进制文件的魔数值是0xcafebabe;2).
nfat_arch字段是指当前的胖二进制文件包含了多少个不同架构的Mach-O文件;
fat_header 后会跟着 fat_arch ,有多少个不同架构的Mach-O文件,就有多少个 fat_arch ,用于说明对应Mach-O文件大小、支持的CPU架构、偏移地址等;
可以用 file 命令来查看下执行文件的信息,如新浪微博:

ps:上述说“大部分情况”是因为还有一部分,由于业务比较复杂,代码量巨大,如果支持多种CPU架构而打包多个Mach-O文件的话,会导致ipa包变得非常大,所以就并没有支持新的CPU架构的。如QQ和微信:

ps:QQ V5.5.1版本单个Mach-O文件大小为51M
1.2 Mach-O
虽然iOS/OS X采用了类UNIX的Darwin操作系统核心,完全符合UNIX标准系统,但在执行文件上,却没有支持UNIX的ELF,而是维护了一个独有的二进制可执行文件格式:Mach-Object(简写Mach-O)。Mach-O是NeXTSTEP的遗产,其文件格式如下:
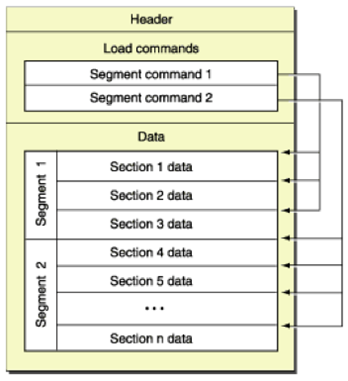
由上图,我们可以看到Mach-O文件主要包含一下三个数据区:
(1). 头部Header :在<mach-o/loader.h>头文件定义了Mach-O Header的数据结构:
/*
* The 32-bit mach header appears at the very beginning of the object file for
* 32-bit architectures.
*/struct mach_header {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */};/* Constant for the magic field of the mach_header (32-bit architectures) */#define MH_MAGIC 0xfeedface /* the mach magic number */#define MH_CIGAM 0xcefaedfe /* NXSwapInt(MH_MAGIC) */以上引用代码是32位的文件头数据结构,<mach-o/loader.h>头文件还定义了64位的文件头数据结构 mach_header_64,两者基本没有差别, mach_header_64 多了一个额外的预留字段 uint32_t reserved; ,该字段目前没有使用。需要注意的是,64位的Mach-O文件的魔数值为 #define MH_MAGIC_64 0xfeedfacf 。
(2). 加载命令 Load Commends :
在mach_header之后的是加载命令,这些加载命令在Mach-O文件加载解析时,被内核加载器或者动态链接器调用,指导如何设置加载对应的二进制数据段;Load Commend的数据结构如下:
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */};OS X/iOS发展到今天,已经有40多条加载命令,其中部分是由内核加载器直接使用,而其他则是由动态链接器处理。其中几个主要的Load Commend为 LC_SEGMENT , LC_LOAD_DYLINKER , LC_UNIXTHREAD , LC_MAIN 等,这里不详细介绍,在<mach-o/loader.h>头文件有简单的注释,后续内核还会涉及。
(3). 原始段数据 Raw segment data
原始段数据,是Mach-O文件中最大的一部分,包含了Load Command中所需的数据以及在虚存地址偏移量和大小;一般Mach-O文件有多个段(Segement),段每个段有不同的功能,一般包括:
1). __PAGEZERO: 空指针陷阱段,映射到虚拟内存空间的第一页,用于捕捉对NULL指针的引用;
2). __TEXT: 包含了执行代码以及其他只读数据。该段数据的保护级别为:VM_PROT_READ(读)、VM_PROT_EXECUTE(执行),防止在内存中被修改;
3). __DATA: 包含了程序数据,该段可写;
4). __OBJC: Objective-C运行时支持库;
5). __LINKEDIT: 链接器使用的符号以及其他表
一般的段又会按不同的功能划分为几个区(section),标识段-区的表示方法为( SEGMENT. section),即段所有字母大小,加两个下横线作为前缀,而区则为小写,同样加两个下横线作为前缀;更多关于常见section的解析,请查看https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/MachORuntime/
2. 内核Kernel
了解了App执行文件之后,我们从源码来看看,App经过了什么样的内核调用流程之后,来到了主程序入口main()。
2.1 XNU开源代码
虽然内核XNU是开源的,但只限于OS X, iOS的XNU内核一直是封闭的,但从历史角度来说,iOS是OS X的分支,两者比较大的区别就是支持的目标架构不一样(iOS目标架构为ARM,而不是OS X的Intel i386和x86_64),内存管理以及系统安全限制;而执行文件都是Mach-O。所以,本文预设两者在App启动执行这方面并没有太大差别。
本文参考的XNU版本为 v2782.1.97 ;
2.2 内核调用流程
可执行文件的内核流程如下图:
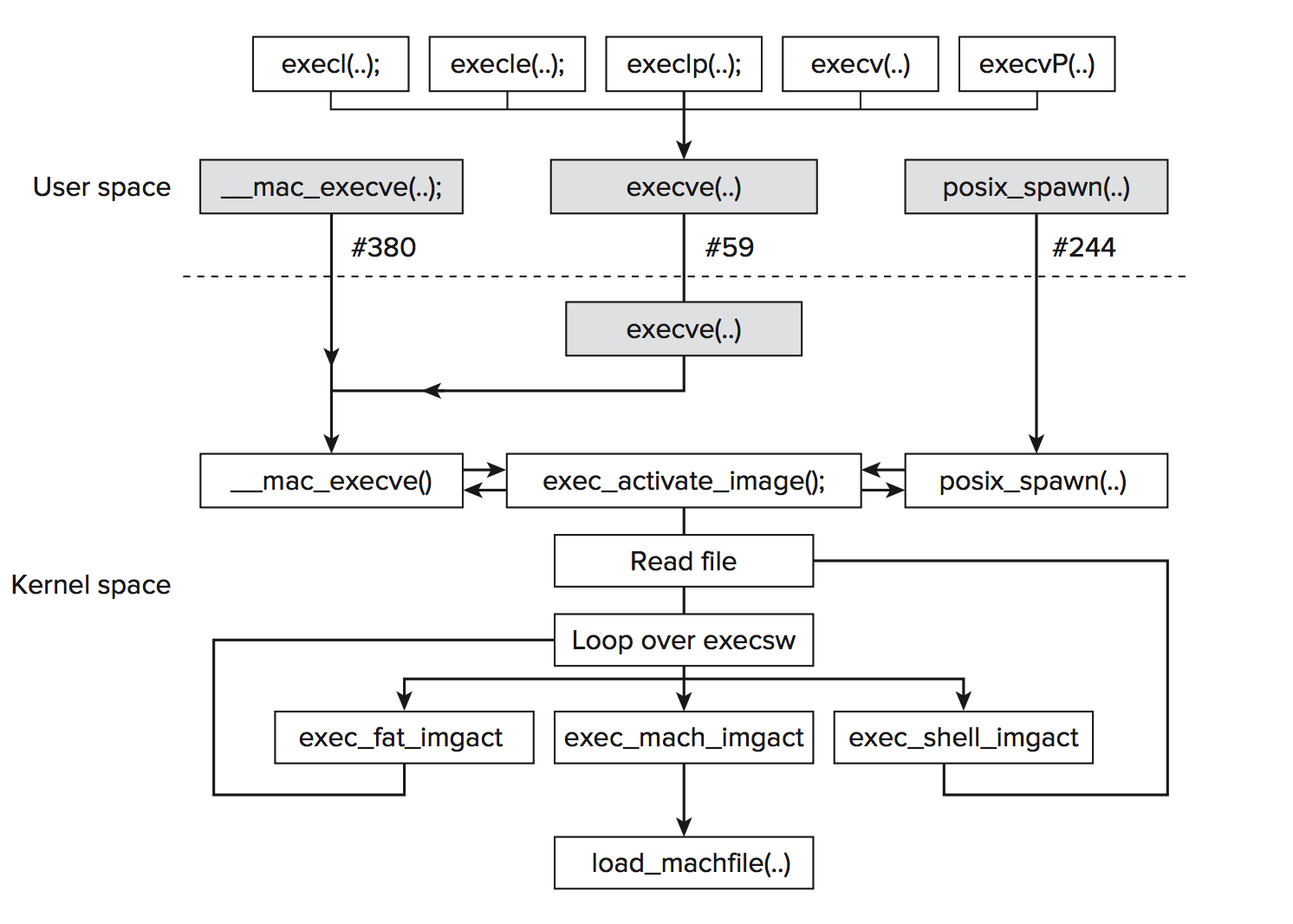
引用自《Mac OS X and iOS Internals : To the Apple's Core》P555
上述流程对应到源代码的调用树为:
ps: 由于源代码较多,篇幅所限,只引用关键性的代码,并有简单的注释,本人注释以oncenote为前缀.
// oncenote: /bsd/kern/ker_exec.c line: 2615execve(proc_t p, struct execve_args *uap, int32_t *retval) {
__mac_execve(proc_t p, struct __mac_execve_args *uap, int32_t *retval)
{// oncenote: /bsd/kern/ker_exec.c line: 2654
// oncenote: /bsd/kern/ker_exec.c line: 2735
// 加载执行文件镜像并设置环境
exec_activate_image(struct image_params *imgp)
{
// oncenote: /bsd/kern/kern_exec.c line: 1328
// 遍历execsw执行格式,执行对应的ex_imgact函数
for(i = 0; error == -1 && execsw[i].ex_imgact != NULL; i++) {
// 1.对于Mach-o Binary,执行exec_mach_imgact
// 2.对于Fat Binary,执行exec_fat_imgact
// 3.对于Interpreter Script,执行exec_shell_imgact
// 由于只支持Mach-O这种执行格式,所以exec_fat_imgact和exec_shell_imgact最终都会调到exec_mach_imgact
// 返回错误码0,则表示mach file被正确加载处理;只有exec_mach_imgact会返回0
error = (*execsw[i].ex_imgact)(imgp);
// oncenote: 对于Mach-o,执行(*execsw[i].ex_imgact)(imgp) = exec_mach_imgact(imgp)
exec_mach_imgact(struct image_params *imgp)
{
// oncenote: /bsd/kern/kern_exec.c line: 893
load_machfile(struct image_params *imgp, ...)
{// oncenote: /bsd/kern/mach_loader.c line: 287
// oncenote: oncenote: /bsd/kern/mach_loader.c line: 336
// 设置内存映射
if (create_map) {
vm_map_create();
}
// oncenote: /bsd/kern/mach_loader.c line: 373
// 设置地址空间布局随机数
if (!(imgp->ip_flags & IMGPF_DISABLE_ASLR)) {
aslr_offset = random();
}
// oncenote: /bsd/kern/mach_loader.c line: 392
parse_machfile(struct vnode *vp, ..., load_result_t *result)
{
// oncenote: 递归深度解析mach file, 在2.3中详细讲解
}
}
// oncenote: /bsd/kern/kern_exec.c line: 973
if (load_result.unixproc) {
/* Set the stack */ //oncenote
thread_setuserstack(thread, ap);
}
// oncenote: /bsd/kern/kern_exec.c line: 1014
// 设置入口点(寄存器状态来自LC_UNIXTHREAD)
/* Set the entry point */
thread_setentrypoint(thread, load_result.entry_point);
/* Stop profiling */
stopprofclock(p);
/*
* Reset signal state.
*/
execsigs(p, thread);
...
}
}
}
}
}由于篇幅所限,本文就不对源码进行展开讲解。通过上述的调用树,App启动在内核中的大概流程已非常清晰,如想更深入研究,请下载 源代码 ,并辅以文末参考资料,进行阅读;
2.3 加载并解析Mach-O文件
前一节描述了可执行文件的执行流程,本节探讨下,内核是如何加载解析Mach-O文件的。
函数 load_machfile() 加载Mach-O文件,然后调用函数 parse_machfile() 解析Mach-O文件。函数 load_machfile() 本身并没有太复杂的逻辑,因此 parse_machfile() 函数是加载解析Mach-O文件的核心逻辑。在阅读具体代码观察解析流程之前,先明确下 parse_machfile() 三个特别的逻辑:
首先,
parse_machfile()是递归解析的,最初的递归深度为0,最高深度到6,防止无限递归。使用递归解析,主要是将不同Mach-O文件类型按照依赖关系,分前后进行解析。如解析可执行二进制文件类型(MH_EXECUTABLE)的Mach-O文件需要调用load_dylinker来处理加载命令LC_LOAD_DYLINKER,而动态链接器也是Mach-O文件,所以就需要递归到不同的深度进行解析;其次,
parse_machfile()的每一次递归,在解析加载命令时,会将内核需要解析的加载命令按照加载循序划分为三组进行解析,在代码的体现上就是通过三次循环,每趟循环只关注当前趟需要解析的命令: (1):解析线程状态,UUID和代码签名。相关命令为LC_UNIXTHREAD、LC_MAIN、LC_UUID、LC_CODE_SIGNATURE (2):解析代码段Segment。相关命令为LC_SEGMENT、LC_SEGMENT_64; (3):解析动态链接库、加密信息。相关命令为:LC_ENCRYPTION_INFO、LC_ENCRYPTION_INFO_64、LC_LOAD_DYLINKER最后,关于Mach-O的入口点。解析完可执行二进制文件类型的Mach-O文件(假设为A)之后,我们会得到A的入口点;但线程并不立刻进入到这个入口点。这是由于我们还会加载动态链接器(dyld),在
load_dylinker()中,dyld会保存A的入口点,递归调用parse_machfile()之后,将线程的入口点设为dyld的入口点;动态链接器dyld完成加载库的工作之后,再将入口点设回A的入口点,程序启动完成;
理解了上述逻辑之后,我们通过源代码最直观地探索解析流程:
// oncenote: oncenote: /bsd/kern/mach_loader.c line: 483staticload_return_tparse_machfile(
struct vnode *vp,
vm_map_t map,
thread_t thread,
struct mach_header *header,
off_t file_offset,
off_t macho_size,
int depth,
int64_t aslr_offset,
int64_t dyld_aslr_offset,
load_result_t *result){
/*
* Break infinite recursion
*/
//oncenote: 最大深度6的控制
if (depth > 6) {
return(LOAD_FAILURE);
}
depth++;
//oncenote: 不同的深度解析不同的Mach-o文件类型,
//如可执行二进制文件类型MH_EXECUTE,只在第一次深度,因此不存在MH_EXECUTE依赖MH_EXECUTE的情况
switch (header->filetype) {
case MH_OBJECT:
case MH_EXECUTE:
case MH_PRELOAD:
if (depth != 1) {
return (LOAD_FAILURE);
}
break;
case MH_FVMLIB:
case MH_DYLIB:
if (depth == 1) {
return (LOAD_FAILURE);
}
break;
case MH_DYLINKER:
if (depth != 2) {
return (LOAD_FAILURE);
}
break;
default:
return (LOAD_FAILURE);
}
// ...
//oncenote: 将所有的加载命令都映射到内核内存中,准备解析
/*
* Map the load commands into kernel memory.
*/
addr = 0;
kl_size = size;
kl_addr = kalloc(size);
addr = (caddr_t)kl_addr;
if (addr == NULL)
return(LOAD_NOSPACE);
error = vn_rdwr(UIO_READ, vp, addr, size, file_offset,
UIO_SYSSPACE, 0, kauth_cred_get(), &resid, p);
// ...
//nocenote: 开始解析加载命令(Load Command),分三趟进行解析
/*
* Scan through the commands, processing each one as necessary.
* We parse in three passes through the headers:
* 1: thread state, uuid, code signature
* 2: segments
* 3: dyld, encryption, check entry point
*/
for (pass = 1; pass <= 3; pass++) {
/*
* Check that the entry point is contained in an executable segments
*/
if ((pass == 3) && (result->validentry == 0)) {
thread_state_initialize(thread);
ret = LOAD_FAILURE;
break;
}
/*
* Loop through each of the load_commands indicated by the
* Mach-O header; if an absurd value is provided, we just
* run off the end of the reserved section by incrementing
* the offset too far, so we are implicitly fail-safe.
*/
offset = mach_header_sz;
ncmds = header->ncmds;
while (ncmds--) {
/*
* Get a pointer to the command.
*/
lcp = (struct load_command *)(addr + offset);
oldoffset = offset;
offset += lcp->cmdsize;
switch(lcp->cmd) {
case LC_SEGMENT:
if (pass != 2) //oncenote: 第二趟进行解析
break;
ret = load_segment(lcp, header->filetype, control, file_offset, macho_size, vp, map, slide, result);
break;
case LC_SEGMENT_64:
//oncenote: 与命令LC_SEGMENT相同
break;
case LC_UNIXTHREAD:
if (pass != 1)
break;
//oncenote: load_unixthread() 依次调用load_threadstack()、load_threadentry()和load_threadstate()
//oncenote: 启动一个unix线程,加载线程的初始化状态,并载入入口点
ret = load_unixthread((struct thread_command *) lcp, thread, slide, result);
break;
case LC_MAIN:
if (pass != 1)
break;
if (depth != 1)
break;
//oncenote: 代替LC_UNIXTHREAD,与LC_UNIXTHREAD类似
ret = load_main((struct entry_point_command *) lcp, thread, slide, result);
break;
case LC_LOAD_DYLINKER:
if (pass != 3)
break;
//在第一次深度的递归调用,解析到LC_LOAD_DYLINKER,设置dlp,用于后续加载动态链接库
if ((depth == 1) && (dlp == 0)) {
dlp = (struct dylinker_command *)lcp;
dlarchbits = (header->cputype & CPU_ARCH_MASK);
} else {
ret = LOAD_FAILURE;
}
break;
case LC_UUID: //oncenote: 省略
break;
case LC_CODE_SIGNATURE: //oncenote: 省略
break;#if CONFIG_CODE_DECRYPTION
case LC_ENCRYPTION_INFO: //oncenote: 省略
case LC_ENCRYPTION_INFO_64:
break;#endif
default:
//内核不处理其他命令,其他命令交由动态链接器dyld来处理
/* Other commands are ignored by the kernel */
ret = LOAD_SUCCESS;
break;
}
if (ret != LOAD_SUCCESS)
break;
}
if (ret != LOAD_SUCCESS)
break;
}
//oncenote: 前面解析命令操作成功,加载动态链接器
if (ret == LOAD_SUCCESS) {
if ((ret == LOAD_SUCCESS) && (dlp != 0)) {
/*
* load the dylinker, and slide it by the independent DYLD ASLR
* offset regardless of the PIE-ness of the main binary.
*/
ret = load_dylinker(dlp, dlarchbits, map, thread, depth, dyld_aslr_offset, result);
}
}
// ...
return(ret);}再来看 load_dylinker() 的代码:
static load_return_tload_dylinker(
struct dylinker_command *lcp,
integer_t archbits,
vm_map_t map,
thread_t thread,
int depth,
int64_t slide,
load_result_t *result){
//oncenote: 获取dyld vnode
ret = get_macho_vnode(name, archbits, header,
&file_offset, &macho_size, macho_data, &vp);
if (ret)
goto novp_out;
*myresult = load_result_null;
/*
* First try to map dyld in directly. This should work most of
* the time since there shouldn't normally be something already
* mapped to its address.
*/
//oncenote: 递归调用parse_machfile()解析dyld
ret = parse_machfile(vp, map, thread, header, file_offset,
macho_size, depth, slide, 0, myresult);
// ...
if (ret == LOAD_SUCCESS) {
//oncenote: 解析成功,设置线程入口为dyld的入口,dyld开始加载共享库
result->dynlinker = TRUE;
result->entry_point = myresult->entry_point;
result->validentry = myresult->validentry;
result->all_image_info_addr = myresult->all_image_info_addr;
result->all_image_info_size = myresult->all_image_info_size;
if (myresult->platform_binary) {
result->csflags |= CS_DYLD_PLATFORM;
}
}
// ...
return (ret);}3. 总结
之前对App流程有个大体的概念,但于细节并不甚清楚,耗时1个多月,边学边复习边写文章,终于在出行旅游前完成。原计划是准备在第三段讲解下动态链接器dyld加载共享库的流程的,但限于本文篇幅实在太长,所以新起一篇文章来写会好一点。
关于App启动流程还有许多细节,如代码签名验证、虚存映射、iOS的触屏应用加载器SpringBoard如何进行切换应用等,本文并未涉及到,有兴趣的同学可以继续深入研究。
参考资料:
版权所有,转载请保留 Jaminzzhang 署名





