

一、使用AtomicLong的缺陷
AtomicLong通过CAS提供了非阻塞的原子性操作。
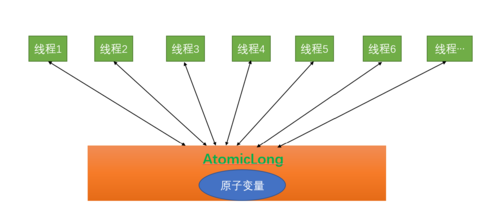
使用AtomicLong时,在高并发环境下,大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,就会白白浪费CPU资源。
AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的(多个线程同时竞争一个原子变量)。
二、LongAdder
JDK8新增了一个原子性递增或递减类LongAdder用来克服在高并发环境下使用AtomicLong的缺点,避免使用AtomicLong浪费大量CPU资源。
LongAdder的实现思路是:把一个变量分解为多个变量,让同样多的线程去竞争多个资源来实现的。(多个线程同时竞争多个原子变量)。
为了解决高并发环境下,多线程对一个变量CAS争夺失败后进行自旋而造成的降低并发性能的问题,LongAdder在内部维护多个Cell元素(一个动态的Cell数组)来分担对单个变量进行争夺的开销。
LongAdder的原理图,如下:
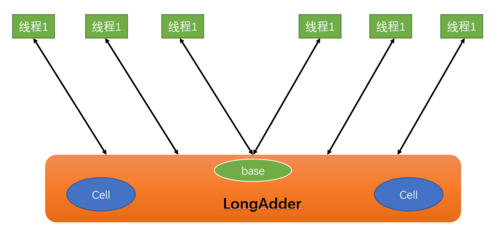
使用LongAdder时,则是在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long类型变量,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这就变相地减少了争夺共享资源的并发量。
当多个线程在争夺同一个Cell原子变量时,如果失败了,它并不是在当前Cell变量上一直自旋CAS重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。
在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base后返回。
LongAdder维护了一个延迟初始化的原子性更新数组Cell和一个基值变量base,默认情况下Cell数组为null,由于Cells占用的内存是相对比较大的,所以一开始并不创建它,而是当需要的时候才会创建它,这就是惰性加载。
当一开始判断Cell数组是null并且并发线程较少时,所有的累加操作都是对base变量进行的。
保持Cell数组的大小为2的N次方,在初始化时Cell数组中的Cell元素个数为2,数组里面的变量实体是Cell类型。Cell类型是AtomicLong的一个改进,用来减少缓存的争用,也就是解决了伪共享问题。
三、LongAdder源码分析
public class LongAdder extends Striped64 implements Serializable {
...
}LongAdder类继承自Striped64类,在Striped64内部维护着三个变量,如下:
transient volatile Cell[] cells;
transient volatile long base;
transient volatile int cellsBusy;
LongAdder的真实值其实是base的值与Cell数组里面所有Cell元素中的value值的累加和,base是个基础值,默认为0。
cellsBusy用来实现自旋锁,状态值只有0和1,当创建Cell元素、扩容Cell数组或者初始化Cell数组时,使用CAS操作该变量来保证同时只有一个线程可以进行其中之一的操作。
Cell的源码如下:
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}Cell类内部维护一个被声明为volatile的变量,这里声明为volatile是因为线程操作value变量时没有使用锁,为了保证变量的内存可见性将变量声明为valatile。
另外cas函数通过CAS操作,保证了当前线程更新时被分配的Cell元素中的value值的原子性。
Cell类使用@sun.misc.Contended修饰是为了避免伪共享。这就保证了线程操作被分配的Cell元素的原子性。
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}long sum()返回当前的值,内部操作是累加所有Cell内部的value值后再累加base。sum函数在计算总值时,并没有对Cell数组进行加锁,所以在累加过程中可能有其他线程对Cell中的值进行了修改,
也有可能对数组进行了扩容,所以sum返回的值并不是非常精确的,其返回值并不是一个调用sum方法时的原子快照值。
public void reset() {
Cell[] as = cells; Cell a;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
a.value = 0L;
}
}
}reset()为重置操作,将base置为0,如果Cell数组有元素,则元素值被重置为0.
public long sumThenReset() {
Cell[] as = cells; Cell a;
long sum = base;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) {
sum += a.value;
a.value = 0L;
}
}
}
return sum;
}sumThenReset()是sum的改造版本,在使用sum累加对应的Cell值后,把当前Cell的值重置为0,base重置为0.
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) { //(1)
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 || //(2)
(a = as[getProbe() & m]) == null || //(3)
!(uncontended = a.cas(v = a.value, v + x))) //(4)
longAccumulate(x, null, uncontended); //(5)
}
}add()函数首先判断Cells是否为null,如果为null则当前在基础变量base上进行累加;
如果不为null或者线程执行代码(1)的CAS操作失败了,则会去执行代码(2)。
代码(2)(3)决定当前线程应该访问Cells数组里面的哪一个Cell元素,如果当前线程映射的元素存在则执行代码(4),使用CAS操作去更新分配的Cell元素的value值,如果当前线程映射的元素不存在或者存在但是CAS操作失败则执行代码(5).
代码(2)(3)(4)用于获取当前线程应该访问的Cells数组的Cell元素,然后进行CAS更新操作,只是在获取期间如果有些条件不满足则会跳转到代码(5)执行。
当前线程应该访问Cells数组的哪一个Cell元素是通过getProbe() & m进行计算的,其中m是当前Cells数组元素个数-1,而getProbe()则用来获取当前线程中变量threadLocalRandomProbe的值,这个值一开始为0,在代码(5)会对其进行初始化。
并且当前线程通过分配的Cell元素的cas函数来保证对Cell元素value值更新的原子性。
LongAdder原子性操作类,该类通过内部cells数组分担了高并发下多线程环境下同时对一个原子变量进行更新时的竞争量,让多个线程可以同时对cells数组里面的元素进行并行的更新操作。
数组元素Cell使用@sun.misc.Contended注解进行修饰,避免了cells数组内多个原子变量被放入同一个缓存行,也就是避免了伪共享,从而提升性能。
LongAdder类是LongAccumulator的一个特例。LongAccumulator比LongAdder的功能更强大。
LongAdder与LongAccumulator的区别:
LongAccumulator可以为累加器提供非0的初始值;它可以指定累加规则,比如不进行累加而进行相乘,只需要在构造LongAccumulator时传入自定义的双目运算器即可;
LongAdder只能为累加器提供默认的0值;它不可以指定累加规则,其累加规则是内置;
四、代码示例
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.LongAdder;
/**
* @ClassName: LongAdderTest1
* @Description:
* @Author: liuhefei
* @Date: 2020/1/14
* @blog: https://www.imooc.com/u/1323320/articles
**/
public class LongAdderTest1 {
private static final int MAX_THREADS = 3; //最大线程数
private static final int TASK_COUNT = 3; //任务数
private static final int TARGET_COUNT = 10000000;
private LongAdder longAdder = new LongAdder(); //创建LongAdder对象
private long count = 0;
private static CountDownLatch cdladdr = new CountDownLatch(TASK_COUNT);
//计数器
protected synchronized long inc() {
return ++count;
}
protected synchronized long getCount() {
return count;
}
public class LongAdderThread implements Runnable {
protected String name;
protected long starttime;
public LongAdderThread(long starttime) {
this.starttime = starttime;
}
@Override
public void run() {
long v = longAdder.sum();
while (v < TARGET_COUNT) {
longAdder.increment();
v = longAdder.sum();
}
long endtime = System.currentTimeMillis();
System.out.println("LongAdderThread spend:" + (endtime - starttime) + "ms" + " v" + v);
cdladdr.countDown();
}
}
public void testLongAdder() throws InterruptedException {
//创建线程池
ExecutorService exe = Executors.newFixedThreadPool(MAX_THREADS);
long starttime = System.currentTimeMillis();
LongAdderThread atomic = new LongAdderThread(starttime);
for (int i = 0; i < TASK_COUNT; i++) {
inc();
System.out.println(i);
exe.submit(atomic);
}
cdladdr.await();
exe.shutdown();
}
public static void main(String[] args) throws InterruptedException {
LongAdderTest1 test1 = new LongAdderTest1();
test1.testLongAdder();
System.out.println(test1.getCount());
}
}参考资源:
(1)https://blog.csdn.net/qq_14828239/article/details/81977181
(2)http://ifeve.com/java8-striped64-and-longadder/
发文不易,请多多支持,喜欢的话,点个赞!




