
高级前端进阶(id:FrontendGaoji)
作者:木易杨,资深前端工程师,前网易工程师,13K star Daily-Interview-Question 作者

前不久看了工业聚的文章《GraphQL-BFF:微服务背景下的前后端数据交互方案》[2],非常非常精彩,又重新拾起了对 GraphQL 的兴趣。本身在工作的项目中,已经在使用 GraphQL 了,可能是因为使用方式的原因,觉得用的有点多余,只是有一个 GraphQL 的壳子而已,没有足够发挥出 GraphQL 的优秀特性,使用的方式有所改进但大致和文章中 [5.1] RESTful-Like 模式 描述的方式类似,type 与 type 之间的定义缺乏联系,与 RESTful API 设计对应只是简单的一对一关系,无法发挥出 GraphQL 关联查询的能力。所以那时候对 GraphQL 这一块的知识就没太关注了。
但是 GraphQL 的社区一直都在发展,关于 GraphQL 的 Repo、文章和讨论也越来越多。在去年杭州开了第一届 GraphQLParty,宋小菜前端团队花了很长很长的篇幅[3]介绍了他们在 GraphQL 方面的实践,也非常非常精彩。所以对这一块的知识也还是会有一些关注,期望能找到一个比较理想的使用 GraphQL 的方式。
正好前不久看到了工业聚写的关于 GraphQL 的文章,发现原来是之前的使用方式有问题,才导致认为 GraphQL 带来的成效并不大。看完这篇文章之后,明白了项目在使用方式上的问题,同时也加深了对它的认识。所以决定对 GraphQL 做进一步的了解。所以就有了今天这个项目。这个项目也是从那个时候开始写的,8 月刚开始。
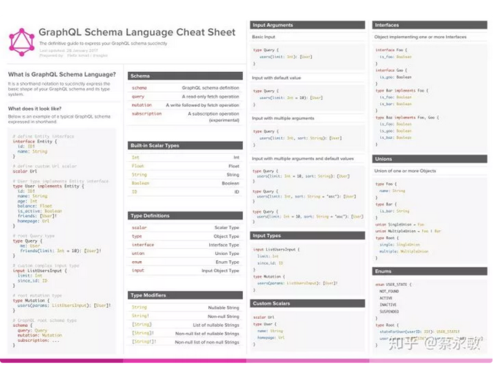
关于 GraphQL 的介绍以及它与 RESTful API 设计的对比已经有很多了,这里就不赘述了。在开始阅读之前,如果对 GraphQL 还不了解的同学,可以先去查阅一些 GraphQL 的基础,比如 GraphQL 的语法介绍[4](中文版[5]),或者查看下面的图片,它把大概要掌握的基础知识都在一张图里面列了出来(来自 graphql-shorthand-notation-cheat-sheet[6])。
如标题所示,这里主要是介绍基于 RESTful API 设计的 GraphQL 服务构建。因为目前项目的接口都是基于 RESTful 规范设计的,这个时候如果想使用 GraphQL,不可能说根据 RESTful 提供的接口用 GraphQL 再实现一遍,这个代价太大了,时间和人力成本各方面都不允许。这个时候如果能直接基于 RESTful API 设计的接口来实现一套 GraphQL 接口是非常好的。RESTful API 接口可以保留且不影响它的后端开发,同时又可以对外提供 GraphQL 的服务,方便前端的使用。
要实现这个功能,其实也不难,使用 GraphQL 的自定义 Directive[7] (指令)就可以完成。自定义指令特性非常实用和便捷,通过编写自定义指令来转换 Schema 的 types、fields 和 arguments,扩展 Schema 字符串所能描述的逻辑。关于自定义指令的介绍,具体可以去看 GraphQL Tools 上关于它的介绍,其中就介绍了怎么样去获取 REST API 的数据( Fetching data from a REST API[8])。
这个项目也就是围绕这个自定义指令展开的,同时也借着这个机会了解 GraphQL 的其他特性。目前这个项目会涉及到的 GraphQL 的特性包括下面的部分,之后随着了解的深入,会继续添加。
•定义 type 来描述各个模块服务•定义 custom scalar type 和 enum type 来扩展 field type•实现自定义指令•query 查询•mutation 操作•query 关联查询•对 query 做 batching 处理•mock 数据•生成 api 文档
在项目实现过程中为了方便考虑,项目中并没有真实实现一个提供 RESTful API 接口的服务,而是用的 json-server[9] 这个 npm 包,模拟了一个 RESTful API 服务。不过毕竟它不是真正的 RESTful API 服务,使用上还是会受到一些限制,比如:
•关联查询的部分,只能查询 /users/:userId/orders 得到一个 orders 数组,不能查 /users/:useId/order,这样只会得到一个空对象。期望是如果 orders 数组只有一个元素,则返回这个元素对象,也就是 user 与 order 是一对一的关系。这时候需要想办法,所以在 @rest 指令里面加入了 responseAccessor 参数,用于对请求到的数据做处理。•不方便做数据之间的联动,比如我新增了一个定义订单记录,记录了对应的 userId 来表示用户信息,这时候需要联动在对应用户信息记录 orderId 信息表示用户的订单号,来记录它们之间的关联关系。但是目前没有找到方便支持的方法,目前的解决方法是事先设想好关联的数据,手动在创建用户信息那里提前记录设想好的 orderId 数据。
所以会导致 mutation 操作和 field resolver 的时候需要做特殊处理。这个具体会在下面的介绍中讲到,先给大家说明一下。
服务构建过程
构建 GraphQL 服务的过程大致分下面几步:
1.基于 Apollo Server 来创建这个服务2.按照工业聚文章中提到的模块服务设计方式来定义 schema
•定义各种 type•定义 scalar type•定义 enum type•为 schema 添加上 @rest 指令
3.实现 RestDirective 自定义指令。4.模拟一个 REST 服务。5.做 mutation 操作,往服务里存储数据。6.做 query 操作,查询之前存储的数据。7.体验级联查询的效果。8.Batching 和 Caching ?9.Mock 数据。10.API 文档。
1. 基于 Apollo Server 创建 GraphQL 服务
Apollo Server[10] 是一个完全由社区驱动开发的开源工具,使用它能快速便捷地创建出一个 GraphQL 服务。它既能独立提供服务,也能以中间件的形式嵌入到 Nodejs 服务中对外提供服务。它对很多现有的 Nodejs 框架都做了支持,比如我们常用的 Express 和 Koa。这个项目采用的是 Koa 的 apollo-server-koa 中间件来创建服务,并使用 TypeScript 来编写。
下面是主要的实现代码:
import { ApolloServer } from 'apollo-server-koa';
import { GraphQLSchema } from 'graphql';
import { fileLoader, mergeTypes } from 'merge-graphql-schemas';
import { makeExecutableSchema, addMockFunctionsToSchema } from 'graphql-tools';
import { RestDirective } from './directives';
import { dateScalarType } from './scalarTypes';
export function createApolloServer(config: {
// 由于涉及到多个文件下的 Type 定义,这里需要传 schemaDir
// 之后再用 graphql-tools 下的 fileLoader / mergeTypes / makeExecutableSchema 方法
// 得到最终的 schema 定义
schemaDir: string;
// 由于可能会涉及到多个后端服务,这里需要传 endpointMap
// 这在后面的 rest 指令中会用到
endpointMap: { [key: string]: string };
// 服务的 mock 数据配置
mocks: boolean | { [ key: string ]: any };
}) {
const { schemaDir, endpointMap, mocks } = config;
// 准备 schema
const typesArray = fileLoader(schemaDir, { recursive: true });
const typeDefs = mergeTypes(typesArray, { all: true });
const schema: GraphQLSchema = makeExecutableSchema({
typeDefs,
schemaDirectives: {
// 添加 RestDirective 自定义指令
rest: RestDirective,
},
});
// 处理 mock 数据
if (mocks) {
addMockFunctionsToSchema({
schema,
mocks: typeof mocks === 'boolean' ? {} : mocks,
preserveResolvers: true,
});
}
return new ApolloServer({
schema,
context: () => ({
endpointMap
}),
resolvers: {
// 添加 custom scalar type
Date: dateScalarType,
},
});
};
2. 定义 Schema
创建好服务,我们需要定义 Schema 来描述各个服务模块。这里主要采用工业聚在上面文章中提到的方式来设计和定义。
Schema 定义包含以下几部分:
•定义 type 来描述各个模块服务,以及 query 和 mutation 要处理的操作•定义 custom scalar type 和 enum type 来扩展 field type•为 field 添加上 @rest 指令
下面是定义用户服务模块的 userService.gql 文件代码。详情的 Schema 定义,可以去查看 ./examples/koaServer/schema 文件夹下的代码。
directive @rest(
endpoint: String
path: String
method: String
parentAccessorMap: String
responseAccessor: String
) on FIELD_DEFINITION
type User {
id: Int
name: String
}
extend type Order {
user(orderId: Int): User @rest(
endpoint: "endpoint2001"
path: "/orders/:orderId/users"
parentAccessorMap: "{ id: orderId }"
responseAccessor: "[0]"
)
}
extend type Product {
users(productId: Int): [User] @rest(
endpoint: "endpoint2001"
path: "/products/:productId/users"
parentAccessorMap: "{ id: productId }"
)
}
input UserInput {
name: String!
# 提前记录设想好的 orderId 信息
orderId: Int
# 提前记录设想好的 productId 信息
productId: Int
}
extend type Query {
user(userId: Int!): User @rest(
endpoint: "endpoint2001"
path: "/users/:userId"
)
users: [User] @rest(
endpoint: "endpoint2001"
path: "/users"
)
}
extend type Mutation {
createUser(body: UserInput): User @rest(
endpoint: "endpoint2001"
path: "/users"
method: "post"
)
updateUser( userId: Int! body: UserInput ): User @rest(
endpoint: "endpoint2001"
path: "/users/:userId"
method: "patch"
)
}
3. 实现 RestDirective 自定义指令
关于 RestDirective 自定义指令的实现,可以查看 graphql-tools 的文档示例:Fetching data from a REST API[11]。这里说明一下项目中 @rest 指令的主要实现思路。
1.它是定义在 field 上的,用来 resolve field 的值。2.目前提供五个设置参数,分别是:
•endpoint:接口服务地址的字符串标识,之后根据 context 中 endpointMap 对象的值来获得实际的接口服务地址。•path:接口请求路径,比如 /api/users/:userId,这里使用 :userId 的方式来表示需要传递给 path 的 userId 变量。这里与常规的 url route path 定义变量的方式相同,然后用 route-parser[12] 类似功能的 npm 包来解析。•method:接口请求方法,小写字符,默认为 'get'。•responseAccessor:对于接口返回的值做处理,它的值实际是 lodash get 方法的第二个参数。•parentAccessorMap: 在关联查询中,上一级 resolve 的值需要传递一些数据给当前查询,但是参数名有可能不同,比如查用户下的订单数据,需要根据 userId 来查询,但是上一级获取到的用户标识的参数名是 id,这样参数名就对应不上。这个时候可以通过设置 parentAccessorMap 的值来设置参数名之间的映射关系。parentAccessorMap 值的类型是 String,但是你可以基本按照正常描述对象的方式来编写,不过目前不支持换行,所以说现在的写法稍微有些不舒服。
•之后会支持写真正的对象,看到过有这种实现的自定义指令,比如 graphql-faker[13] 项目中的 @fake 指令,支持写对象和数组。到时候就不会有这个问题了,不过到时候 @rest 指令的参数格式应该会相应发生改变。•【08/21】更新:详细看了下,发现不行,它其实是一个 input type,并且参数名都是确定的,而 parentAccessorMap 里面的参数名都是不确定的,所以逻辑复用不了。而且还会涉及比较复杂的转换过程,晚上刚更新了一版,估计之后还会有其他情况,逻辑还需要增强。•【08/27】更新:还是用 input type 比较好,可读性也强。不过需要在 @rest directive definition 那里定义 ParentAccessorMapInput 会支持的属性,不然在 parentAccessorMap 中设置的属性会无效(详见示例代码)。
3.实际 field.resolve 函数中要处理的 args 参数对象,项目中会把这个对象里面的参数分成三块:
•一块是 params,附加到 url path 上。•一块是 body,附加到请求体里面。•还有一块是 path args,用于 url route path 的解析。•之后也可以有 headers 参数来自定义一些要发送请求头等等。
4.最后使用 axios 来发送接口请求。5.目前还没有处理接口权限问题。
具体代码可查看 ./src/directives/rest.ts 文件。
4. 模拟 RESTful API 服务
上面提到了,项目中并没有真实实现一个 RESTful API 服务,而是用 json-server 这个 npm 包,模拟了一个。省略了连接数据库,或者连接远程服务的步骤,用本地 json 文件来保存数据对外提供 RESTful API 服务。由于不是主要逻辑模块,实现逻辑这里不详述。下面是实现代码:
import jsonServer from 'json-server';
import path from 'path';
const server = jsonServer.create();
const dbPath = path.join(__dirname, './db.json');
const router = jsonServer.router(dbPath);
const middleware = jsonServer.defaults();
const port = 2001;
server.use(middleware);
server.use(router);
server.use(jsonServer.bodyParser);
server.listen(port, () => {
console.log(`JSON Server is running on: http://127.0.0.1:${port}`);
});
5. 做 mutation 操作,往服务里存储数据
OK,上面算是做好创建服务的基础工作之后,这个时候需要往里面存储数据了。比如说创建用户信息。这里推荐 Altair GraphQL Client[14] 来调试,一个类似于 Postman 的接口调试客户端,挺好用的。
mutation CreateUser($body: UserInput!) {
createUser(body: $body) {
name
}
}
{
"body": {
"name": "gogogo",
"orderId": 1,
"productId": 1
}
}
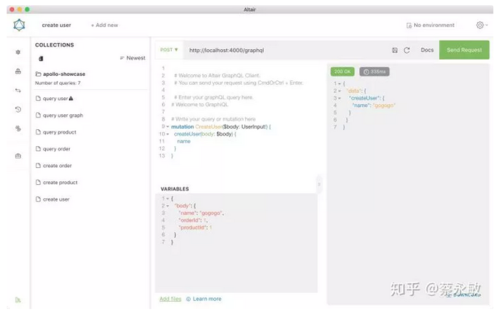
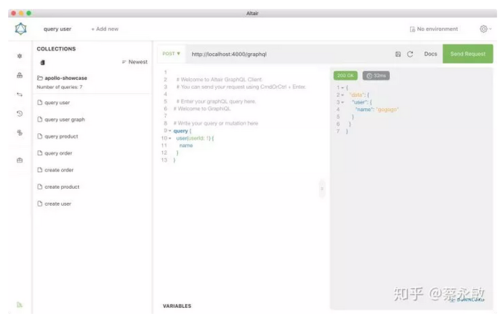
6. 做 query 操作,查询之前存储的数据
存储了数据之后,就可以对里面的数据进行查询了,比如获取用户信息。
query {
user(userId: 1) {
name
}
}
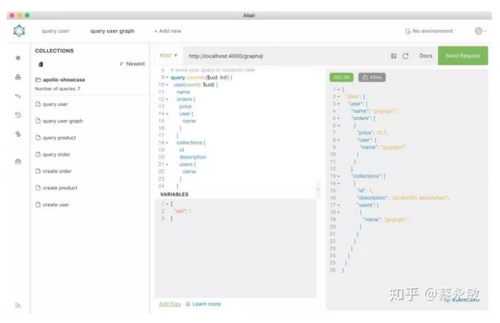
7. 体验 GraphQL 关联查询
按照上面的步骤分别存储看 users、orders、products 的数据(实际上项目里已经预先存储好了需要调试的数据,可以去 ./examples/jsonServer/db.json 文件下查看),这时候我们一起体验一下 GraphQL 优秀特性之一关联查询。比如查询用户名下的订单数和产品数,每个订单和产品又可以往下查对应的用户信息。一级一级按照各个服务模块之间的关联关系来查询数据。
query userInfo($uid: Int!) {
user(userId: $uid) {
name
orders {
price
user {
name
}
}
collections {
id
description
users {
name
}
}
}
}
{
"uid": 1
}
8. Batching 和 Caching?
这个部分主要涉及到 GraphQL 比较经典的 N+1 问题,它会给服务器带来性能问题。
关于这个问题,facebook 官方关于 graphql 的 github group 下维护了一个叫 dataloder[15] 的包来处理这个问题。主要的操作是 batching 和 caching。详细了解可以去看它的 README 文档。
项目中预计用不了 caching 操作,因为用的是 RESTful API 接口,没有深入到数据库操作那一层,不知道接口数据什么时候会发生变化(如果有办法知道数据什么时候会发生变化也可以用;或者把不可修改数据和其他数据分开,单独对这一部分数据做 caching 操作,一般来说不可修改数据都是比较重要的数据),也就不知道什么时候要更新缓存,保证不了缓存是否新鲜,这样使用过程中肯定会出现问题。batching 操作的话,可以有效去重 event loop 下同一个 tick 内发送的请求,减轻一定的服务端压力。但是面对不同的请求,请求该发还得发,基本避免不了,除非 RESTful 服务有对应的 API 支持。
目前这部分的代码还么有实现,计划本周五(08/23)之前完成。
【08/23】更新:今天实现了一版,用数据测了下,发现有两点想错了:
1.batching 操作并不会去重 event loop 下同一个 tick 内发送的请求,它只是合并成一个请求一起发送了,但其实到最后都是根据一个数组来发送请求的,所以 batching 操作对于 RESTful 服务相当于是无效的。2.caching 操作并不是直接 caching 请求到的数据,而是 caching 发送请求的 Promise,请求还是会发出去,这就意味着可以对 RESTful API 直接做 caching 操作,然后只会发送一次,这很棒!
9. Mock 数据
关于 mock 数据[16],GraphQL 有很自然的优势,因为它本身 field 在定义的时候就确定了数据类型,然后我们再根据它的数据类型来提供 mock 数据。
内置的 scalar type,在打开 mock 数据开关之后,会默认给对应的类型提供 mock 数据(当然也可以修改),对于自定义的 scalar type 和 enum type,我们也可以很轻松地提供 mock 数据,配合上 casual[17] 或者 faker.js[18] 这些模拟数据的工具。
给特定的 field 提供模拟数据,比如说 user 或者 users。就相当于定义了 这个 field 的 resolver,可以拿到传进来的参数,根据传进来的参数动态的返回模拟数据。
上面是需要侵入项目代码的模拟数据的方式,也可以选择在外面另外起一个服务来模拟数据,也可以尝试 graphql-faker[19] 通过扩展现有服务的方式来提供 mock 数据,不改动原有项目代码,它会在项目根目录下创建一个 .grahql 文件。目前在这个库上我还没有太多尝试,所以只是一个尝试建议。
10. 生成 API 文档
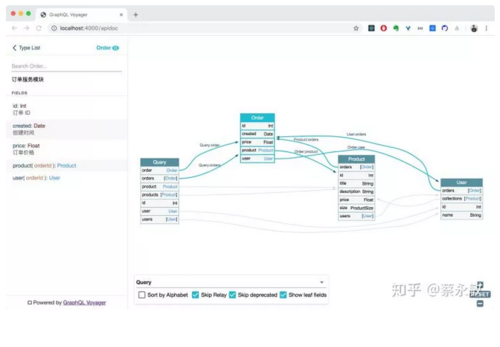
同理,GraphQL 也可以很方便地生成 API 文档,而且还可以根据 type 与 type 之间关系,画一张关系图出来。
下面是使用 graphql-voyager[20] 生成的 API 文档,结果如下图:
结语
整个项目实现下来最大的两点感受是:Schema 定义的部分可能需要反复调整,需要对业务模块足够了解,才能比较好的定义出 type 与 type 之间的关联关系;自定义指令方面还需要对参数和参数类型做很好地支持,才能让开发者轻松地使用它来完成他们所需要的功能。
对于如何使用 GraphQL 来说,这个项目只是一个开始,接下来还有很多内容需要去了解和实践,包括对现有实现模块的改进。最后,希望本文对你在 GraphQL 的使用方面有所帮助。





