
首先,我们先来打开美团美食商家页面,来分析一下。
https://www.meituan.com/meishi/1381636/
如上面所提供的URL即为美团美食商家页面。或者我们通过美团官网打开一个美团美食商家页面,打开步骤如下:
1、打开浏览器,输入 即可打开美团北京首页 2、鼠标滑动到美食标签上,点击更多,即可打开美团美食商家列表页,注意是列表页 3、在列表页中随便点击一家商家即可打开美团美食商家页面。
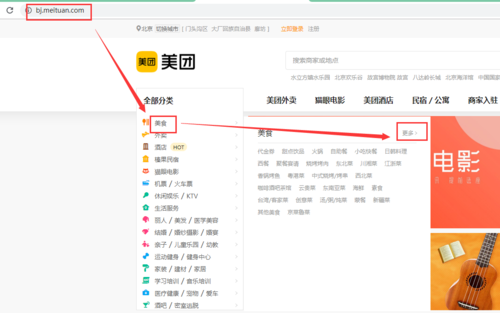
如我现在打开的 北京全聚德(朝阳北路店),打开这个页面之后,我们要抓取哪些数据呢?
主要分为三部分:
1、美团美食商家基本信息 2、美团美食商家推荐菜 3、美团美食商家评论信息
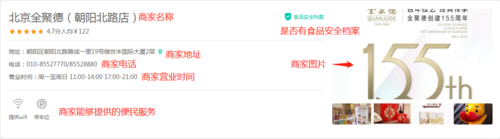
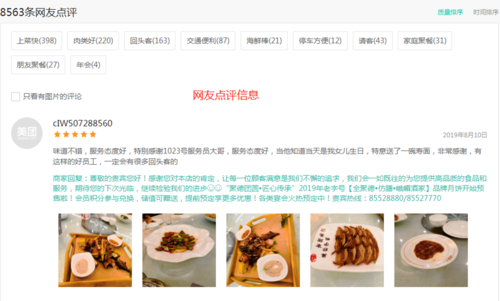
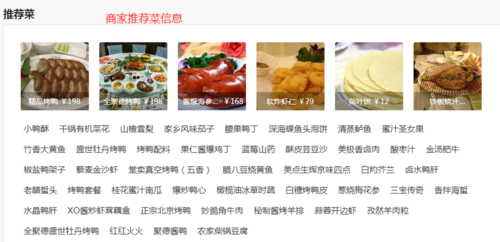
可能有的小伙伴有这样的疑问或需求,我们可不可以抓取美团美食商家的团购信息呢?
是可以的,只不过麻烦一些,需要我们登录,并且不仅仅是登录这一个技术难点,我们还需要搭建cookies池,用于随机使用登录信息获取商家团购及优惠信息,否则一直使用一个cookies信息获取时会被美团发现,从而封掉我们的登录信息,造成我们无法抓取。
商家团购及优惠信息的抓取,以及搭建cookies池,我们将会在下次技术分享中给大家讲解。本次,我们先解决美团美食商家信息数据的抓取。
首先我们来分析一下美团美食商家页面请求信息,打开浏览器的开发者模式(打开浏览器后按键盘上的f12即可打开浏览器的开发者模式),勾选network标签下的preserve.log(防止新的请求会覆盖老的请求),刷新美团美食商家页面即可抓取到本页数据包。
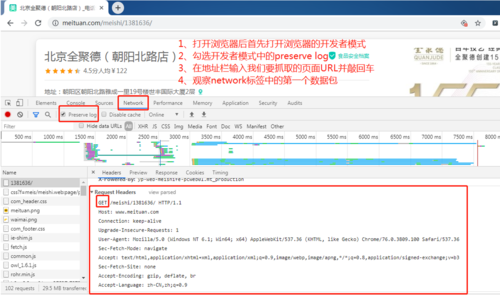
根据数据包的抓取结果,我们可以分析出:
1、该请求为GET请求 2、该请求不携带任何cookies信息 3、请求的URL为https://www.meituan.com/meishi/1381636/
接下来,我们就可以编辑代码来获取美团美食商家信息了。
import requests
import re
import json
class Meituanbusiness(object):
"""
处理美团商家详情页
https://www.meituan.com/meishi/6484620/
"""
def __init__(self):
#MAC下的UA可用。。。
self.header = {
# "User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
def handle_detail(self,business_id):
business_id = business_id
self.business_detail_url = "https://www.meituan.com/meishi/%s/"%business_id
response = requests.get(url=self.business_detail_url,headers=self.header)
#提取数据区域
data = re.search(r'12315消费争议(.*?)"dealList":', response.text, flags=re.DOTALL)
if data:
# 细节信息
detail_info = re.search(r'"detailInfo":\{"poiId":(\d+),"name":"(.*?)","avgScore":(.*?),"address":"(.*?)","phone":"(.*?)","openTime":"(.*?)","extraInfos":\[(.*?)\],"hasFoodSafeInfo":(.*?),"longitude":(.*?),"latitude":(.*?),"avgPrice":(\d+),"brandId":(\d+),"brandName":"(.*?)",".*?photos":{"frontImgUrl":"(.*?)","albumImgUrls":(.*?)},"recommended":(.*?),"crumbNav":(.*?),"prefer',data.group(1))
if detail_info:
info = {}
# 商家ID
info['poiId'] = detail_info.group(1)
# 商家名称
info['name'] = detail_info.group(2)
#商家评分
info['avgScore'] = detail_info.group(3)
#商家地址
info['address'] = detail_info.group(4)
#电话
info['phone'] = detail_info.group(5)
#营业时间
info['openTime'] = detail_info.group(6)
#是否有食品安全档案
info['hasFoodSafeInfo'] = detail_info.group(8)
#经纬度
info['longitude'] = detail_info.group(9)
info['latitude'] = detail_info.group(10)
#均价
info['avgPrice'] = detail_info.group(11)
# 品牌ID
info['brandId'] = detail_info.group(12)
# 品牌名称
info['brandName'] = detail_info.group(13)
#商家图片
info['frontImgUrl'] = detail_info.group(14)
#宣传图片
info['albumImgUrls'] = detail_info.group(15)
# 其他信息解析,wifi,停车位
extraInfos = detail_info.group(7)
if extraInfos:
items = json.loads("[" + extraInfos + "]")
extraInfos = ''
for item in items:
extraInfos = item.get('text') + ',' + extraInfos
info['extraInfos'] = extraInfos[0:-2]
# 推荐菜
info['recommended'] = json.loads(detail_info.group(16))
if __name__ == '__main__':
meituan_business_detail = Meituanbusiness()
meituan_business_detail.handle_detail("6484620")我们可以运行一下,我们的程序代码,来看看当前数据的获取情况,仅展示一部分:

这样呢,我们就可以获取到美团美食商家的信息了,接下来,我们来抓取美团美食商家的评论信息。
首先第一步,还是需要我们来分析请求信息,也就是从众多请求中,找出哪个请求是评论信息的请求,我们可以在异步请求中找到这个请求信息,怎么查找异步请求呢。
1、在网络标签中,切换到XHR 2、在众多异步请求中找到评论信息的请求包
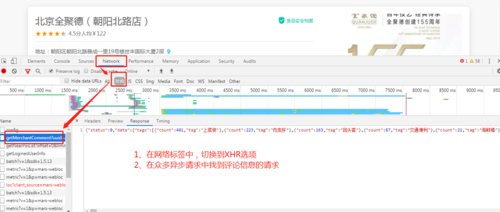
我们可以来分析一下这个异步请求,看看他需要哪些信息
https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=4c075f52-c8ba-4116-b02d-5015c4ade7e5&platform=1&partner=126&originUrl=https://www.meituan.com/meishi/1467844/&riskLevel=1&optimusCode=10&id=1467844&userId=&offset=30&pageSize=10&sortType=1
分析如下:
1、 请求接口 2、 uuid 设备信息,我们可以从上一步获取商家信息中获取到 3、platform=1&partner=126 平台信息等,保持默认 4、 当前访问页面 5、 offset=30 偏移量,也是页码信息 其他保持默认
经过如上分析之后,我们就可以抓取到评论信息了,代码如下:
import requests
import re
import time
class MeituanBusinessComment(object):
def __init__(self):
self.index_url = "https://www.meituan.com/meishi/1467844/"
self.header = {
# "User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
def handle_uuid(self):
uuid_search = re.compile(r"uuid=(.*?);")
uuid_response = requests.get(url=self.index_url,headers=self.header)
self.uuid = uuid_search.search(uuid_response.headers['Set-Cookie']).group(1)
def handle_comment(self):
self.handle_uuid()
"""
https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=4c075f52-c8ba-4116-b02d-5015c4ade7e5&platform=1&partner=126&originUrl=https://www.meituan.com/meishi/1467844/&riskLevel=1&optimusCode=10&id=1467844&userId=&offset=30&pageSize=10&sortType=1
"""
for page in (0,110,10):
comment_url = "https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=%s&platform=1&partner=126&originUrl=https://www.meituan.com/meishi/1467844/&riskLevel=1&optimusCode=10&id=1467844&userId=&offset=%s&pageSize=10&sortType=1"%(self.uuid,page)
response = requests.get(url=comment_url,headers=self.header)
print(response.text)
time.sleep(1)
meituan_comment = MeituanBusinessComment()
meituan_comment.handle_comment()我们来看一下评论的抓取结果

到此为止,我们已经抓取到了这个商家的所有信息了,包括商家信息,推荐菜信息,评论信息。
那有的同学说,现在可以解析一家的商家信息了,美团上有那么多商家信息,如何才能抓取得到呢,这里呢,给大家提供思路,我们打开美团美食之后,是不是可以进入美团美食的列表页啊,那么在列表页中就可以获取到所有的商家ID,也就是我们当前的代码只需要改一下商家ID,就可以获取其他商家的信息了。
import requests
import json
import re
class MeituanBusinessPage(object):
"""
解析美团美食页码页
"""
def __init__(self):
self.index_url = "https://bj.meituan.com/meishi/pn1/"
self.header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
def handle_page(self):
"""
处理页码页
:return:
"""
data_search = re.compile(r'"poiInfos":(.*?)},"comHeader"')
for page in range(1,11):
# 构造页码页
page_url = "http://bj.meituan.com/meishi/sales/pn%s/"%page
page_response = requests.get(url=page_url,headers=self.header)
data = data_search.search(page_response.text).group(1)
for item in json.loads(data):
print(item['poiId'])
if __name__ == '__main__':
meituan_business_page = MeituanBusinessPage()
meituan_business_page.handle_page()有同学说可不可以使用scrapy框架抓取呢,当然是可以的。
这里呢给大家提供了使用scrapy框架抓取美团美食商家信息代码:
https://github.com/freedom-wy/js-reverse/tree/master/meituan
可能有小伙伴对scrapy框架不是很了解,那么这里呢提供给大家一套免费的学习scrapy框架的课程
《Python最火爬虫框架Scrapy入门与实践》
https://www.imooc.com/learn/1017
那还有的小伙伴呢,对python爬虫一点都不了解,也没有关系,我在慕课网上出了一套《入门主流框架Scrapy与爬虫项目实战》,课程地址:https://www.imooc.com/learn/1017 可以更加系统的,从基础开始学习爬虫技术,这套课程包括linux系统管理,Python网络编程,初探网络爬虫,高级爬虫与实战。由浅入深,由点到面的讲解了爬虫技术。
那么大家都知道,在抓取web网页信息的时候,我们可以采用selenium调用浏览器来渲染动态页面,从而实现数据的抓取,那么同样的,我们也可以实现通过appium调用安卓系统来抓取app数据:
《Python爬虫工程师必学——App数据抓取实战》,课程地址:https://coding.imooc.com/class/283.html 通过appium实现控制安卓系统中的app,从而实现模拟点击,滑动等操作,通过mitmdump等抓包工具实现数据的解析。
这套课程已经上线一段时间了,近期大壮老师会对该课程进行升级,通过抓取到的数据,如抖音个人信息数据等实现数据的可视化。
















热门评论
-

慕设计20045202019-08-31 2
-

慕设计20045202019-08-31 2
-

慕函数41161122019-09-01 0
查看全部评论页面里不是可以看的见呢,为啥要抓取呢
页面里不是可以看的见呢,为啥要抓取呢
1111111111111111