
Python新手写出漂亮的爬虫代码2——从json获取信息
好久没有写关于爬虫的东西了,如果正在读这篇博客的你看过我的另一篇《Python新手写出漂亮的爬虫代码1——从html获取信息》想必已经对一些写在html中的信息进行过爬取了,今天给大家介绍一下另一种爬虫——动态爬虫。
1.静态爬虫与动态爬虫
何为动态爬虫,html中的信息是静态的,或者说是通过html语言生成了网页中的对应信息,是写好的,你把网页的html源代码粘贴过来,你要的信息就在里面,这种情况下就是静态爬虫,而有的时候我们会发现我们需要的信息不在html源码中,比如电商网站的评论,某些网站的一些条形图啊,折线图啊,(这些图实际上是数字,只是通过某种接口传到网页上,然后渲染成了图的形式,其本质上是数字),这些可能频繁更新的信息(比如评论每小时甚至每分钟都在更新),这时候,如果将它写在html中,是一个很难受的过程,因为有一个新评论你就要改写html,所以对于这种情况,我们想要的数据都会存在一个json文件中。
这里需要做一个说明,我们看网页源代码,通过在网页上鼠标邮件,点选“查看网页源代码”出来的才是html源码,而通过F12调出的开发者工具中的element或元素中的那些,不是html代码,而是html代码的一个超集,它比真实的html代码内容要多,所以查看信息是否在html中还是需要点选“查看网页源代码”才准确。
2.json
json是一种数据格式,类似于python中的字典,以key:value的形式存储信息,是一种目前越来越常用的方便的数据存储方式。
3.动态爬虫思路
动态爬虫较静态爬虫而言难点在于定位数据或信息的存储位置,而一旦获取了这个位置(json文件对应的url),那么就非常简单了,使用python的json库可以对json数据轻松的解析,说白了只是根据你要的key提取其value而已,所以动态爬虫是比较简单的(当然,这里还有另一个问题,是异步加载问题,这个以后有机会再讲,异步加载是啥?比如说某个网页,没有“下一页”按钮,而是用鼠标滚轮或者屏幕右侧的滑块,向下滑就会刷新,你连往下刷多久会到底都不知道,这就是异步加载,异步加载可以通过抓包工具去解决,也可以使用selenium模拟鼠标点击去解决,以后会讲到)。
4.定位json存储位置
定位json的位置通常是通过“换页”来查看Network的变更,在网页上按F12打开开发者工具,界面放到Network中,然后换页,查看“js”或是“XHR”中文件的更新,然后一一查看更新的json文件,来定位我们需要的信息在哪里。
5.实例讲解
说了这么多你可能还是有点儿糊涂,没关系,来个例子就懂了,就拿天猫的一个女装来说吧,其url为https://detail.tmall.com/item.htm?spm=a1z10.3-b-s.w4011-14681080882.119.17398fc89ncLzj&id=529355863153&rn=ec60f51904f6286d9b2d8bb02c8ca5a8&abbucket=5
(这个模特身材还不错哈哈)
请看图1,我们点击红色方块中的“累计评价”,就可以看到以往的评价,按照我们前一篇爬虫的讲解来说,这个信息可能在html代码中,好,那么我们看一看,按下F12,如图2所示。
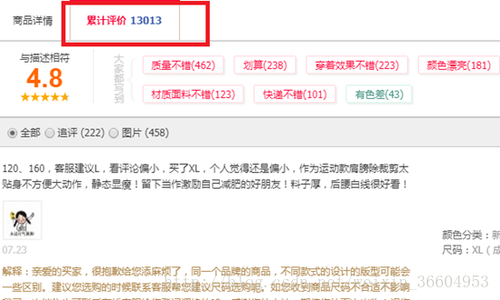
图2中的1和2位置可以看到,评论仿佛是在一个标签中的,但是还记得我前面的说明么,你在这里看到的html代码是真实html代码的一个超集,比实际的html代码要多,那么我们右键鼠标,选择“查看网页源代码”,并把源码复制粘贴到文本编辑器中,查找图2中1对应的评论,结果如图3所示。
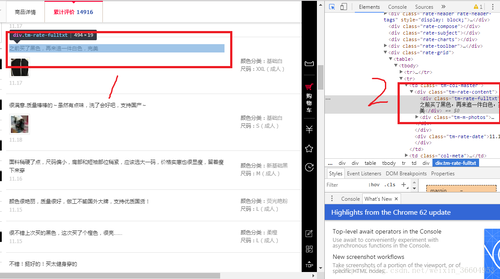
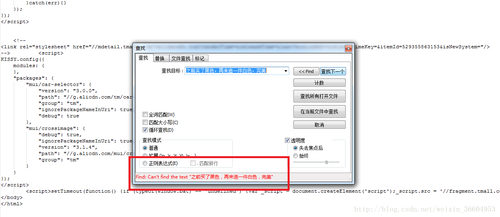
图3中竟然没有搜索到这个评论,也就是说图2的开发者工具欺骗了我们,too young too sample,sometime naive,哈哈,没关系,以后每次爬虫之前都这么看一看,就知道你要的信息是不是在html中了。好了,既然不在html中,那么我们需要去寻找我们想要的信息在哪里了。
按照图4,在开发者工具中选择“Network”,来查看网页其他组件信息。
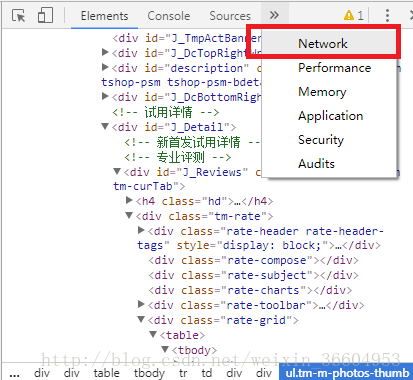
如图5的红色方块,点击“JS”,不出以外应该是空的,当然如果你那里不是空的也无所谓,无伤大雅,我们要的数据就在JS下,只是现在还未显示出来(还有一些情况,尤其是折线图这些图像形式的数据,一般会存储在XHR下,也就是图5中的粉色圈中,也是.json形式的),接下来我们就要去寻找存储评论数据的json文件了。
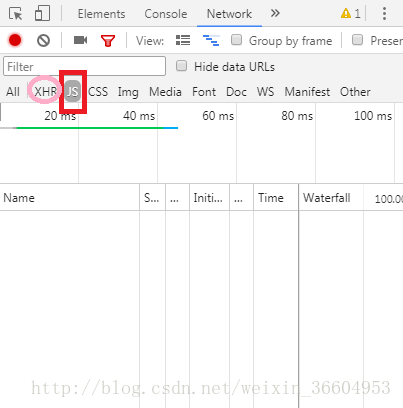
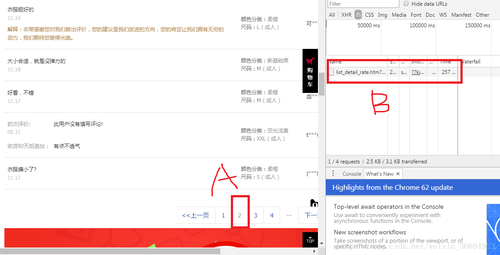
此时“JS”下的界面如图5所示,有可能是空的,当然也可能会有一些其他的东西,接下来看图6,点击图6中A处页码“2”,将评论页切换到第二页,这时候你会发现B处,也就是JS界面中出现了一个文件(如果你先前图5中有内容,那此时应该是多出一个文件),这个文件叫“list-detail**********”。我们的数据就存放在这里。
有些时候,你换页后可能会出现或新增多个json文件,不过一般都不会很多,最多也就5个,你只需要挨个点进去看看哪个存放了你需要的信息即可。
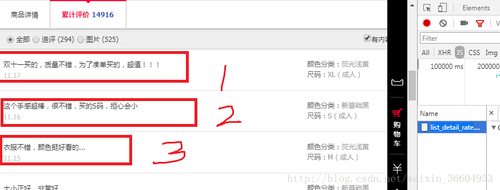
接下来,我们双击这个文件,或者单击选中这个文件,复制其url然后粘贴到浏览器的地址栏中也可,其内容如图7所示,这里红框标出了其前三条评论。因为我们是在评论的第二页打开的这个json,所以它对应的是第二页的评论内容,而网页中第二页评论的前三条如图8所示。
可以看到,数据对上了,我们已经成功的定位到了评论的位置,图7的json诚如各位所见,是一个字典的形式,评论内容对应的key为”rateContent”。

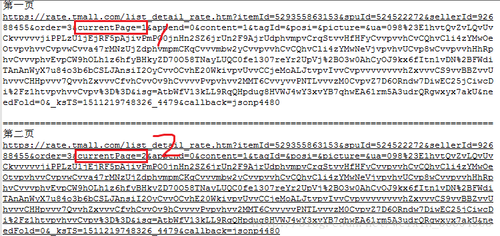
接下来看一下评论的页码是怎么控制的。如图9所示,其实两个url只差了之歌数字,就是图9红框标出的”currentPage=”后面的数字,如果是第一页,数字就是1,如果是第二页,数字就是2。好了,换页规律找到了,剩下就是解析json了,就是最简单的一步。
关于json的解析我不准备过多解释了,有python基础的朋友一定对json这个库不陌生,我在代码中以注释的方式给出吧。本例代码使用Python3。
6.代码实战
import urllib
import urllib.request
import re
from bs4 import BeautifulSoup
import timeimport random
import json
import math# 创建一个文件存储评论及其他数据myfile = open("tm_fz_gn_1_1_1.txt","a")# 共获取四个变量,评论者昵称,是否超级会员,评论时间,评论内容print("评论者昵称","是否超级会员","评论时间","comment",sep='|',file=myfile)
stop = random.uniform(0.5,2)# 获取页数try:
url0 = "https://rate.tmall.com/list_detail_rate.htm?itemId=544442011638&spuId=718591114&sellerId=196993935&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=025UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5Ockp3S39AeU13QnhDeC4%3D%7CU2xMHDJ7G2AHYg8hAS8XIw0tA18%2BWDRTLVd5L3k%3D%7CVGhXd1llXWBcaFduWmBVb1RvWGVHe0Z9SXRLc05zRnlDfkZ6VAI%3D%7CVWldfS0TMww1CioWIgIsCCNMMWwyVDlrME8iakFhXn5BZEocSg%3D%3D%7CVmhIGCUFOBgkGiMXNwwzBzsbJxkiGTkDOA0tES8ULw81Cj9pPw%3D%3D%7CV2xMHDIcPAA%2FASEcPAM4Az9pPw%3D%3D%7CWGBAED4QMGBaZ1p6RXBKc1NoXWBCfUh0S3NTbVBqSnROblBkMhIvDyEPLxciGSx6LA%3D%3D%7CWWBdYEB9XWJCfkd7W2VdZ0d%2BXmBdfUF0Ig%3D%3D&isg=AnBwr9DL3fao4YAwe7Eb61VPQT4CEVRrBvSVMGrBPUueJRHPEskkk8YHCxu-&needFold=0&_ksTS=1501924984733_1070&callback=jsonp1071"
req0 = urllib.request.Request(url0)
req0.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
html0 = urllib.request.urlopen(req0,timeout=500).read()
html0 = bytes.decode(html0,encoding="gbk") # print(type(html0))
'''
下面这一步是因为这个json不是标准的json,json是一个完完全全的字典,而这个json是在类似json1234()这个结构的括号中,打开看看这个json你就懂了,所以需要用正则表达式去获取真实的json(即字典)
'''
js0 = re.search('{"rateDetail(.*)',html0).group()[:-1] # 将json主要内容存入content
content0 = json.loads(js0)
content = content0['rateDetail'] # print(content.keys())
# print(json.dumps(content0, sort_keys=True, indent=2))
#尾页
lastpage = int(content['paginator']['lastPage'])
except: print("获取尾页失败,默认爬取99页")
lastpage = 99# 构造循环遍历每一页for i in range(1,lastpage):
try:
url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=544442011638&spuId=718591114&sellerId=196993935&order=3¤tPage='+str(i)+'&append=0&content=1&tagId=&posi=&picture=&ua=025UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5Ockp3S39AeU13QnhDeC4%3D%7CU2xMHDJ7G2AHYg8hAS8XIw0tA18%2BWDRTLVd5L3k%3D%7CVGhXd1llXWBcaFduWmBVb1RvWGVHe0Z9SXRLc05zRnlDfkZ6VAI%3D%7CVWldfS0TMww1CioWIgIsCCNMMWwyVDlrME8iakFhXn5BZEocSg%3D%3D%7CVmhIGCUFOBgkGiMXNwwzBzsbJxkiGTkDOA0tES8ULw81Cj9pPw%3D%3D%7CV2xMHDIcPAA%2FASEcPAM4Az9pPw%3D%3D%7CWGBAED4QMGBaZ1p6RXBKc1NoXWBCfUh0S3NTbVBqSnROblBkMhIvDyEPLxciGSx6LA%3D%3D%7CWWBdYEB9XWJCfkd7W2VdZ0d%2BXmBdfUF0Ig%3D%3D&isg=AnBwr9DL3fao4YAwe7Eb61VPQT4CEVRrBvSVMGrBPUueJRHPEskkk8YHCxu-&needFold=0&_ksTS=1501924984733_1070&callback=jsonp1071'
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
html = urllib.request.urlopen(req,timeout=500).read()
html = bytes.decode(html,encoding="gbk")
js = re.search('{"rateDetail(.*)', html).group()[:-1]
infos0 = json.loads(js)
infos = infos0['rateDetail']['rateList']
tiaoshu = 0
for info in infos:
try:
tiaoshu += 1
time.sleep(stop)
ss = "正在爬取第%d页的第%d条评论,共%d页" % (i,tiaoshu,lastpage) print(ss) # 用户姓名
try:
user_name = info['displayUserNick'].strip().replace('\n','')
except:
user_name = ""
# 是否黄金会员
try:
user_status = info['goldUser'].strip().replace('\n','')
except:
user_status = ""
# 评论时间
try:
comment_date = info['rateDate'].strip().replace("\n","")
except:
comment_date = ""
# 评论内容
try:
comment = info['rateContent'].strip().replace("\n","").replace('\t','')
except:
comment = ""
print(user_name,user_status,comment_date,comment,sep='|',file=myfile)
except:
sss = '爬取第%d页的第%d条评论失败,跳过爬取' % (i,tiaoshu) print(sss)
pass
except: print("该产品url获取失败,请检查")
myfile.close()









热门评论
-

ufan02018-04-18 0
查看全部评论ID牛啊! 已收藏。