

timeline

1998, Yann LeCun 的 LeNet5
图像特征分布在整个图像上
在具有很少参数的多个位置上提取类似特征时,具有可学习的参数的卷积是个比较有效的方法
在没有应用GPU的时候,能够保存参数和计算就成了一个关键优势
LeNet5并没有把每个像素都作为大型多层神经网络的一个输入,因为图像是高度空间相关的,如果用了这种方法,就不能很好地利用相关性
LeNet5 的主要特征:
CNN 主要用这3层的序列: convolution, pooling, non-linearity
用卷积提取空间特征
由空间平均得到子样本
用 tanh 或 sigmoid 得到非线性
用 multi-layer neural network(MLP)作为最终分类器
层层之间用稀疏的连接矩阵,以避免大的计算成本

LeNet5
2010, Dan Claudiu Ciresan and Jurgen Schmidhuber 的 Dan Ciresan Net
是比较早的GPU神经网络之一,在NVIDIA GTX 280图形处理器上实现了9层神经网络的前向后向计算。
2012,Alex Krizhevsky 的 AlexNet
是LeNet的一个更深和更广的版本,可以用来学习更复杂的对象
AlexNet 的主要特征:
用rectified linear units(ReLU)得到非线性
使用辍 dropout 技巧在训练期间有选择性地忽略单个神经元,来减缓模型的过拟合
重叠最大池,避免平均池的平均效果
使用GPU NVIDIA GTX 580可以减少训练时间,这比用CPU处理快了10倍,所以可以被用于更大的数据集和图像上

AlexNet
2013年12月,Yann LeCun的纽约大学实验室的 OverFeat
是AlexNet的衍生,提出了 learning bounding boxes
2015,牛津的 VGG
率先在每个卷积层中使用更小的 3×3 filters,并将它们组合成卷积序列
虽然小,但是多个3×3卷积序列可以模拟更大的接收场的效果
这个想法也在最近的Inception和ResNet网络中有所应用
2014,Min Lin, Qiang Chen, Shuicheng Yan 的 NiN
它的思想很简单但是很有效,使用1x1卷积给一个卷积层的特征提供了更多的组合性
每个卷积之后使用空间MLP层,以便在另一层之前更好地组合特征,而没有使用原始像素作为下一层的输入
可以有效地使用非常少的参数,在这些特征的所有像素之间共享

Network-in-network
2014,Google Christian Szegedy 的 GoogLeNet and Inception
在昂贵的并行块之前,使用1×1卷积块(NiN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担
它用一个没有 inception modules 的 stem 作为初始层
用类似于NiN的平均池加上softmax分类器

Inception
2015年2月,Christian 团队的 Inception V2,2015年12月,Inception V3
在每个池之前,增加 feature maps,构建网络时,仔细平衡深度和宽度,使流入网络的信息最大化
当深度增加时,特征的数量或层的宽度也有所增加
在下一层之前,增加每一层的宽度来增多特征的组合性
尽量只使用3x3卷积

Inception V3
2015,Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun 的 ResNet
这个网络绕过了2层,可以被看作一个小的分类器,或者一个NiN
这也是第一次训练了大于100甚至1000层的网络
在每一层,通过使用更小output的1x1卷积来减少特征的数量,然后经过一个3x3 层,接着又是一个1x1卷积,这个方法可以保持少计算量,同时提供丰富的特征组合
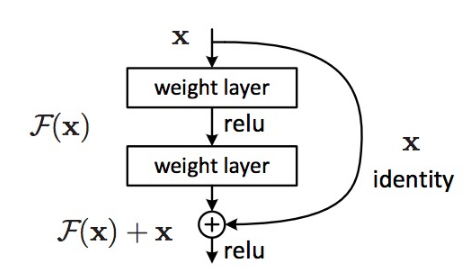
ResNet
2016,François Chollet 的 Xception
这个网络和 ResNet and Inception V4 一样有效,而且用了更简单优雅的结构
它有36个卷积阶段,和ResNet-34相似,不过模型和代码和ResNet一样简单,并且比Inception V4更易理解
这个网络在 Torch7/Keras / TF 都已经可以应用了

Xception





