
之前我们的课程都在关注线性的数据结构,我们从本章开始学习树结构,二分搜索树。
树结构:
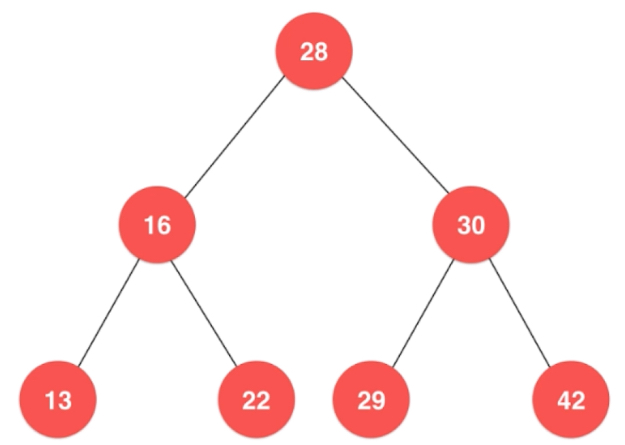
线性数据结构是将数据排成一排,树结构倒过来更像一棵树。
为什么要有树结构?
树结构本身是一种天然的组织结构。
电脑中的文件夹就是一种树结构,计算机中让人们使用的存储结构来源于生活。图书馆分区,分类,分子类。
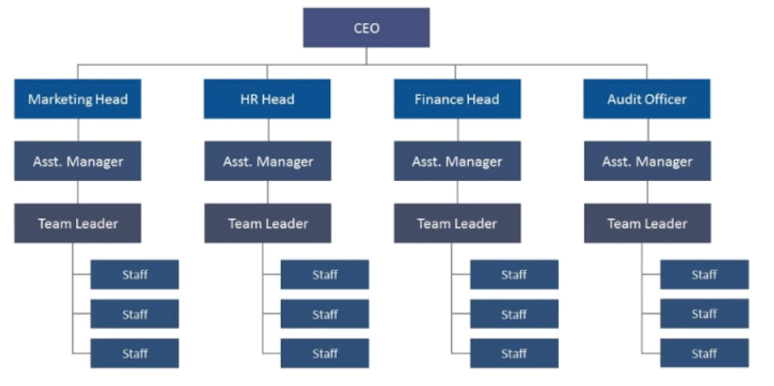
公司的组织架构也是一种树结构。生活中能看到这么多树结构,为什么呢?高效的检索(目录找文件,ceo找技术开发部门的人)。
将数据使用树结构存储后, 出奇的高效
二分搜索树(Binary Search Tree) 局限性,因此我们会介绍两种平衡二叉树: AVL,红黑树;为满足数据的某一类特殊操作,堆与并查集。特殊数据存储成树结构,对于特殊数据的领域形成高性能,课程会介绍线段树[线段数据],Trie(字典树,前缀树)[处理字符串]。
不一定是显式的使用树结构进行存储,但是高效的搜索操作,很多时候也离不开树结构。比如,用户使用撤销操作和括号不匹配ide的报错,用户是不知道背后用了栈的,但为了达成这种效果,我们是要使用栈的。虽然解决的是数据存储的问题,但在使用层面上不仅仅因为存储而使用,更多时候是因为只有使用了这种数据结构我们才能基于它实现高效的算法。
二分搜索树
二叉树,和链表一样,动态数据结构。
class Node{
E e;
Node left;
Node right;
}除过元素值,还有两个指向左右子树的引用。二叉树:每个节点最多分出两个叉(后面会学到多叉树)
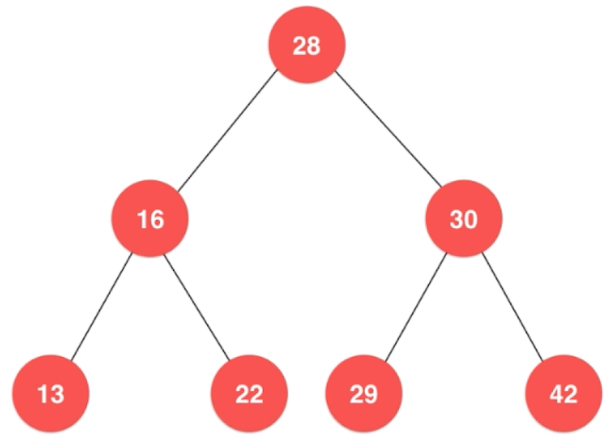
二叉树具有具有唯一根节点
class Node {
E e;
Node left; // 左孩子
Node right; // 右孩子}二叉树每个节点最多有两个孩子,下面这些一个孩子都没有的通常称为叶子节点(左右孩子都为空的节点)。
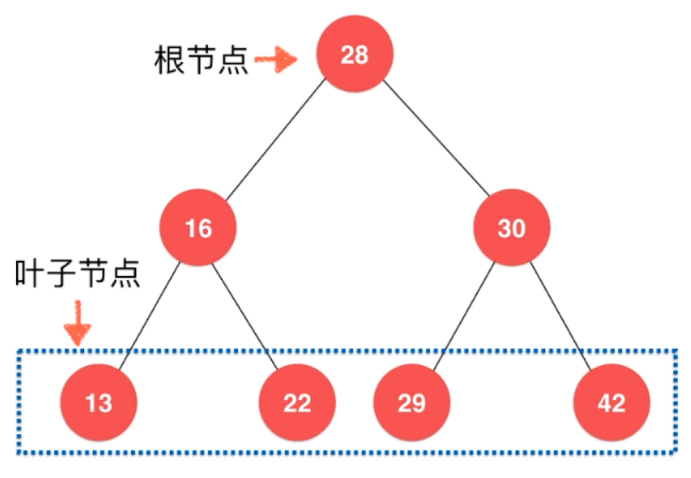
二叉树每个节点最多有一个父亲,根节点没有父亲节点。
二叉树具有天然递归结构
很多时候在树中,使用递归结构要简单的多。天然递归结构表现在: 每个节点的左,右子树都是棵二叉树。
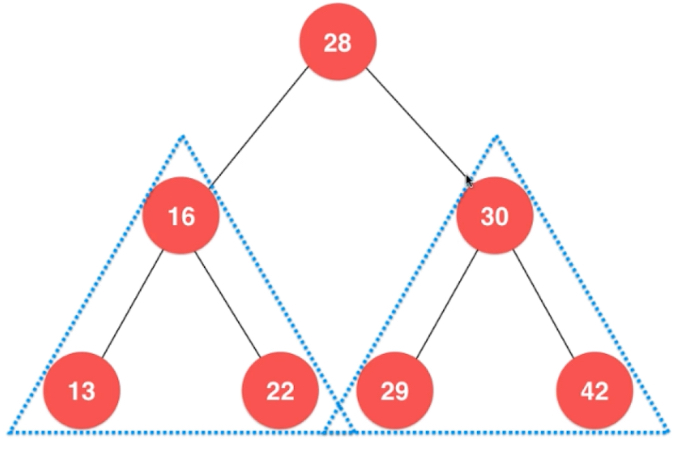
满二叉树: 除了叶子节点之外,每个节点都有两个孩子。 但二叉树不一定是满的。
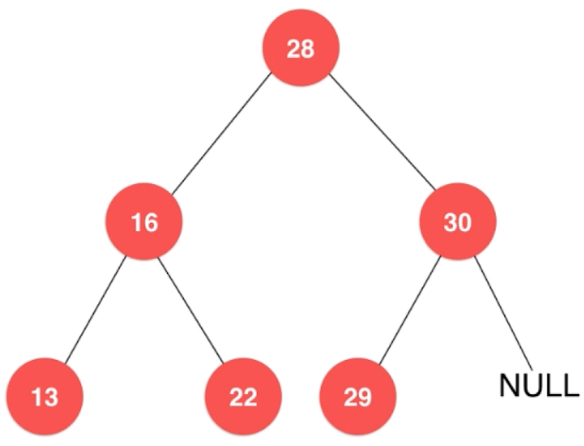
这也是一棵二叉树,它就是一棵不满的。
这也是一颗二叉树,28和16都没有右子树,看上去是一个链表。

一个节点也是二叉树;空也是二叉树
二分搜索树 Binary Search Tree
首先,二分搜索树是二叉树。二叉树中的所有术语,在二分搜索树中也都适用。
二分搜索树的每个节点的值大于其左子树的所有节点的值,小于其右子树的所有节点的值。每一棵子树也是二分搜索树
检索时,查找53,53一定在右子树,左子树根本不用看。要达成这样的检索,就必须让我们存储的元素具有可比较性。
如果是我们自定义的对象想要使用二分搜索树,那么我们需要自定义好两个学生之间是如何进行比较的。之前我们的链表和数组是没有这个要求的,这可以看成是二分搜索树的一个局限性,要想加快搜索就要对于数据有一定的要求。
package cn.mtianyan;/**
* 二分搜索树,binary search tree(限制类型具有可比较性)
*/public class BST<E extends Comparable<E>> { /**
* 节点类对用户屏蔽
*/
private class Node { public E e; // 节点元素值
public Node left, right; // 左子树,右子树引用
/**
* 默认的节点构造函数
*
* @param e
*/
public Node(E e) { this.e = e;
left = null;
right = null;
}
} private Node root; // 根节点
private int size; // 树中元素的个数
/**
* 默认的二分搜索树构造函数
*/
public BST() {
root = null;
size = 0;
} /**
* 获取搜索树中节点元素个数
*
* @return
*/
public int getSize() { return size;
} /**
* 二分搜索树是否为空
*
* @return
*/
public boolean isEmpty() { return size == 0;
}
}上面是在一个二分搜索树中最基本的方法。
向二分搜索树中添加元素。

可以看到,此时要添加28的话,从根节点不断向下跟新的子树根节点判断大小。
我们的二分搜索树不包含重复元素;如果想包含重复元素的话,只需要定义: 左子树小于等于节点;或者右子树大于等于节点。
注意:我们之前讲的数组和链表,可以有重复元素. 二分搜索树添加元素的非递归写法,和链表很像
/**
* 向二分搜索树中添加新的元素e(面向用户使用的)
*
* @param e
*/
public void add(E e) { if (root == null) {
root = new Node(e);
size++;
} else
add(root, e);
} /**
* 语义: 向以node为根的二分搜索树中插入元素e,递归算法
*
* @param node
* @param e
*/
private void add(Node node, E e) { if (e.equals(node.e)) return; // 此处相当于去重
//小于e的值,并且该节点的左子树为空。
else if (e.compareTo(node.e) < 0 && node.left == null) {
node.left = new Node(e);
size++; return;
} // 如果大于e的值,并且该节点的右子树为空。
else if (e.compareTo(node.e) > 0 && node.right == null) {
node.right = new Node(e);
size++; return;
} // 上面条件不满足,说明还得继续往下找左右子树为null可以挂载上的节点
if (e.compareTo(node.e) < 0) // 如果小于,那么继续往它的左子树添加该节点
add(node.left, e); else //e.compareTo(node.e) > 0
// 大于,往右子树添加。
add(node.right, e);
}二分搜索树添加元素的非递归写法,和链表很像; 这个课程在二分搜索树方面的实现,关注递归实现
。二分搜索树一些方法的非递归实现,留做练习。在二分搜索树方面,递归比非递归实现简单: )
二分搜索树插入元素改进: 深入理解递归终止条件。
上节代码向以node为根的二分搜索树中插入元素e,插入给左孩子或右孩子。对于根节点做了特殊处理,对于node.e 和e,我们进行了两轮的比较,小于并有空位,直接插入;没有空位小于,继续往下寻找。
此时我们的递归函数的终止条件非常的臃肿,因为我们要考虑node的左右孩子是否为为空,但是我们之前就说过,空本身也是一颗二叉树。
如果我们在遍历过程中走到了一个node为空的地方,一定是要创建新节点了。此时我们的如下代码并没有递归到底。
else if (e.compareTo(node.e) < 0 && node.left == null) {
node.left = new Node(e);
size++; return;
} // 如果大于e的值,并且该节点的右子树为空。
else if (e.compareTo(node.e) > 0 && node.right == null) {
node.right = new Node(e);
size++; return;
}既然我们看到了这个e小于node.e ,不管是不是空,都再递归一层。如果递归到的这一层为空,这个位置本身就应该是这个节点。
if (e.equals(node.e)) return; // 此处相当于去重
//小于e的值,并且该节点的左子树为空。
else if (e.compareTo(node.e) < 0 && node.left == null) {
node.left = new Node(e);
size++; return;
} // 如果大于e的值,并且该节点的右子树为空。
else if (e.compareTo(node.e) > 0 && node.right == null) {
node.right = new Node(e);
size++; return;
}如上的终止条件就可以写为
if (node == null){ new Node(e);
size ++;
}但是此时我们就没法把这个节点和我们的树挂接起来了。如何挂?return给函数调用的上层。
/**
* 向二分搜索树中添加新的元素e(面向用户使用的)
*
* @param e
*/
public void add(E e) {
root = add(root, e);
} /**
* 返回插入新节点后二分搜索树的根
*
* @param node
* @param e
* @return
*/
private Node add(Node node, E e) { if (node == null) {
size++; return new Node(e);
} // 上面条件不满足,说明还得继续往下找左右子树为null可以挂载上的节点
if (e.compareTo(node.e) < 0) // 如果小于,那么继续往它的左子树添加该节点,这里插入结果可能根发生了变化。
node.left = add(node.left, e); // 新节点赋值给node.left,改变了二叉树
else if (e.compareTo(node.e) > 0) // 大于,往右子树添加。
node.right = add(node.right, e); return node;
}传入的node为空,就直接new 一个node,然后return回去调用出。node.left 或者node.right 此时node.left就等于新产生的这个节点。
面向公众的add方法中也不需要再判断root是否为空了,如果为空直接会new一个新的node,并返回至调用处root = add(root, e);被根节点保存下来。
宏观自己画图,微观进行小数据集代入。可以尝试链表插入元素的递归算法,二分搜索树要判断插左还是右,链表直接插入.next就可以了。
二分搜索树中搜索元素。
查询元素只需要看每一个node里面存储的元素就可以了。
/**
* 看二分搜索树中是否包含元素e(面向用户的)
*
* @param e
* @return
*/
public boolean contains(E e){ return contains(root,e);
} /**
* 看以node为根的二分搜索树中是否包含元素e(递归算法语义)
*
* @param node
* @param e
* @return
*/
private boolean contains(Node node,E e){ if (node == null) return false; if (e.compareTo(node.e) == 0) return true; else if (e.compareTo(node.e) < 0) return contains(node.left,e); else // e.compareTo(node.e) < 0
return contains(node.right,e);
}contains的具体语义。二分搜索树中没有索引概念,我们就不用实现根据索引查询二分搜索树的方法了。
二分搜索树的前序遍历
什么是遍历操作?
遍历操作就是把所有节点都访问一遍;访问的原因和业务相关;在线性结构下,遍历是极其容易的;在树结构下,也没那么难。
对于遍历操作,两棵子树都要顾及。
function traverse(node): if(node == null ) return; // 访问该节点 traverse(node.left) traverse (node.right)
前序遍历顺序:是指先访问根,再访问左右。
/**
* 二分搜索树的前序遍历(用户使用)
*/
public void preOrder(){
preOrder(root);
} /**
* 前序遍历以node为根的二分搜索树, 递归算法
*
* @param node
*/
private void preOrder(Node node){ if(node == null) return;
System.out.print(node.e+" ");
preOrder(node.left);
preOrder(node.right);
}二分搜索树的toString
/**
* 打印二分搜索树的信息
*
* @return
*/
@Override
public String toString() {
StringBuilder res = new StringBuilder();
generateBSTString(root, 0, res); return res.toString();
} /**
* 生成以node为根节点,深度为depth的描述二叉树的字符串
*
* @param node
* @param depth
* @param res
*/
private void generateBSTString(Node node, int depth, StringBuilder res) { if (node == null) {
res.append(generateDepthString(depth) + "null\n"); return;
}
res.append(generateDepthString(depth) + node.e + "\n");
generateBSTString(node.left, depth + 1, res);
generateBSTString(node.right, depth + 1, res);
}
/**
* 生成树深度的标识。
*
* @param depth
* @return
*/
private String generateDepthString(int depth) {
StringBuilder res = new StringBuilder(); for (int i = 0; i < depth; i++)
res.append("--"); return res.toString();
}上面的代码实现了将二分搜索树的信息进行遍历,添加深度信息,打印输出。其中generateBSTString为遍历节点操作。
package cn.mtianyan;public class Main { public static void main(String[] args) {
BST<Integer> bst = new BST<>(); int[] nums = {5, 3, 6, 8, 4, 2}; for(int num: nums)
bst.add(num); /////////////////
// 5 //
// / \ //
// 3 6 //
// / \ \ //
// 2 4 8 //
/////////////////
bst.preOrder();
System.out.println();
System.out.println(bst);
}
}运行结果:

一样深度的是同一层的节点,可以看出根左右的顺序。
中序遍历,后序遍历。
前序遍历是最自然的遍历方式,也是最常用的遍历方式。
function traverse(node): if(node == null ) return; traverse (node.left) // 访问该节点 traverse(node.right)
中序遍历为左根右。
/**
* 二分搜索树的中序遍历(用户使用)
*/
public void inOrder() {
inOrder(root);
} /**
* 中序遍历以node为根的二分搜索树, 递归算法
*
* @param node
*/
private void inOrder(Node node) { if (node == null) return;
inOrder(node.left);
System.out.print(node.e + " ");
inOrder(node.right);
}bst.inOrder(); // 2 3 4 5 6 8 System.out.println();

可以看到中序遍历的结果就是二分搜索树排序的结果。

作者:天涯明月笙
链接:https://www.jianshu.com/p/eb21d672555f




