
另外一种特殊的树结构: 并查集 一种很不一样的树形结构
前面我们接触的树结构都是由父亲指向孩子,但是我们的并查集却是由孩子指向父亲。这种奇怪的树结构可以非常高效的回答一类问题: 连接问题 Connectivity Problem

如上图一张图中,有很多点,每两个点之间有没有连接的问题。给出任意两点是否有路径相连。
并查集可以非常快的查看到网络中节点间的连接状态。网络是个抽象的概念:用户之间形成的网络
每两个人通过各自的好友连接起来,设计网络。商品,图书,音乐专辑节点之间定义边。交通系统之间的网络,计算机网络路由器为节点。
并查集 还是数学中的集合类实现,主要操作在求集合的并集。
连接问题 和 路径问题
存在路径一定连接, 不存在路径一定不连接。
回答两个节点之间的连接问题是要比回答路径问题要回答的问题少。
只需要回复是或不是,问a与b的路径,返回一个具体的路径。 只想知道连接状态,求解路径会消耗性能。
完全可以使用复杂度更高的算法进行求解,但是之所以复杂度更高,其实是因为求解出了很多我们问的问题并不关心的内容。
和堆作比较,我们可以使用线性表,链表保持有序就可以了。顺序表不止可以取出最大的元素(最大堆),也可以取出第二大,第三大,第k大。但是我们用堆时,只关心最高的那个,因此顺序表维护了很多我们并不需要的信息,性能消耗O(n); 堆只关注最大的,因此堆性能更高。
回答额外问题,性能变低。
并查集Union Find 对于一组数据,主要支持两个动作:
union(p, q) isConnected( p, q)
逐步优化我们的并查集,首先设计一个并查集接口。
package cn.mtianyan;public interface UF { int getSize(); // 对当下这些元素
boolean isConnected(int p, int q); // id为p id为q是否相连
void unionElements(int p, int q);
}union是将两个元素合并起来。
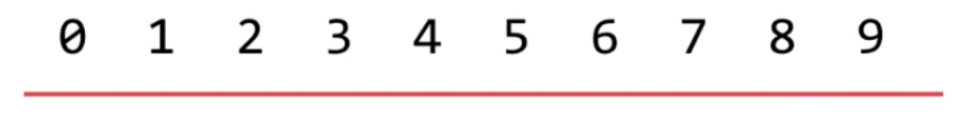
并查集的内部只存0-9这十个编号,不会关注它具体代表。每一个元素存储它所属的集合的id
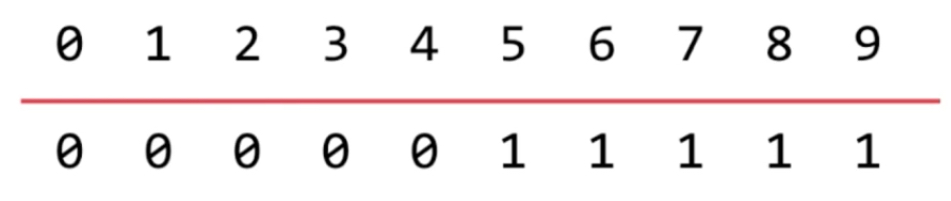
如上图是分成了两个集合,数组称之为id。对应的集合id相同则相连。
isConnected( p, q) = find(p) == find(q) Quick Find时间复杂度O(1),直接取出数组index对应的值。

经过union之后,数组变为如上图所示。遍历,将所有id为0的改为1。
package cn.mtianyan;/**
* 我们的第一版Union-Find
*/public class UnionFind1 implements UF { private int[] id; // 我们的第一版Union-Find本质就是一个数组
public UnionFind1(int size) {
id = new int[size]; // 初始化, 每一个id[i]指向自己, 没有合并的元素
for (int i = 0; i < size; i++)
id[i] = i;
} @Override
public int getSize() { return id.length;
} /**
* 查找元素p所对应的集合编号 O(1)复杂度
*
* @param p
* @return
*/
private int find(int p) { if (p < 0 || p >= id.length) throw new IllegalArgumentException("p is out of bound."); return id[p];
} /**
* 查看元素p和元素q是否所属一个集合 O(1)复杂度
*
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected(int p, int q) { return find(p) == find(q);
} /**
* 合并元素p和元素q所属的集合 O(n) 复杂度
*
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) { int pID = find(p); int qID = find(q); if (pID == qID) return; // 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并
for (int i = 0; i < id.length; i++) if (id[i] == pID)
id[i] = qID;
}
}
某一个操作O(n),性能比较差,需要进行改进。创建一棵树,从孩子指向父亲。
Quick Union
标准的并查集实现思路: 将每一个元素,看做是一个节点
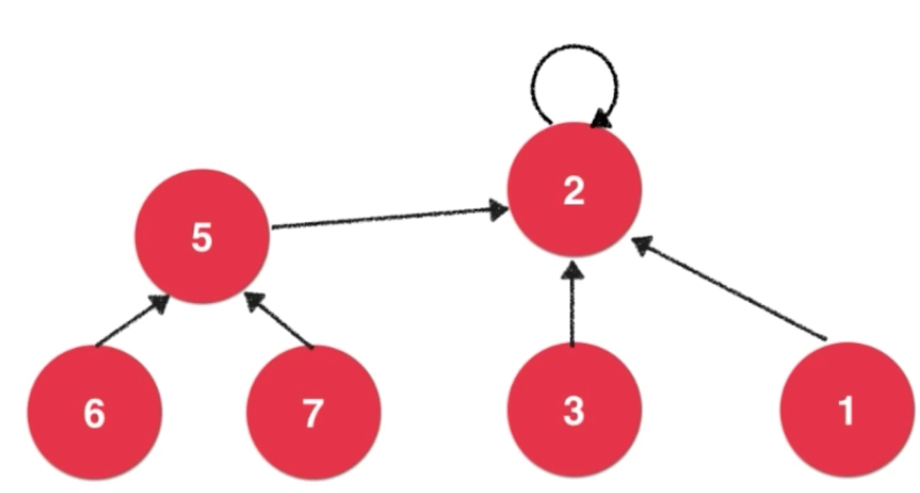
如果是让7和2合并,不需要把每个节点都与之连接,而是将5和2连接起来就可以了。7和3连接,与上面得到的结果是一样的。
每一个节点本身只有一个指针,parent(i)表示第i个元素所在的节点指向了哪个元素。


森林中有十棵树,Union(4,3) 就是让4指针指向3。
数组中

查询4所在的链的根节点(8自己指自己),然后让9指向4所在树根节点。

Union的复杂度是O(h)级别的,h是当前union的这两个元素所在树的深度。代价: 查询操作时得查询根节点。
package cn.mtianyan;/**
* 我们的第二版Union-Find
*/public class UnionFind2 implements UF { /**
* 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
* parent[i]表示第一个元素所指向的父节点
*/
private int[] parent; /**
* 构造函数
* @param size
*/
public UnionFind2(int size){
parent = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < size ; i ++ )
parent[i] = i;
} @Override
public int getSize(){ return parent.length;
} /**
* 查找过程, 查找元素p所对应的集合编号 O(h)复杂度, h为树的高度
* @param p
* @return
*/
private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while(p != parent[p])
p = parent[p]; // 不断上移,直到指向自己
return p;
} /**
* 查看元素p和元素q是否所属一个集合 O(h)复杂度, h为树的高度
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected( int p , int q ){ return find(p) == find(q);
} /**
* 合并元素p和元素q所属的集合 O(h)复杂度, h为树的高度
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return;
parent[pRoot] = qRoot;
}
}基于size的优化
第一版就是数组,第二版形成了树结构,孩子指向父亲。通过节点查到根节点。测试前面两个的性能
package cn.mtianyan;import java.util.Random;public class Main { private static double testUF(UF uf, int m) { int size = uf.getSize();
Random random = new Random(); long startTime = System.nanoTime(); for (int i = 0; i < m; i++) { int a = random.nextInt(size); int b = random.nextInt(size);
uf.unionElements(a, b);
} for (int i = 0; i < m; i++) { int a = random.nextInt(size); int b = random.nextInt(size);
uf.isConnected(a, b);
} long endTime = System.nanoTime(); return (endTime - startTime) / 1000000000.0;
} public static void main(String[] args) { // int size = 10000;
// int m = 10000;
// UnionFind1慢 : 0.03809207 s UnionFind2 : 0.026871858 s
// int size = 100000;
// int m = 10000;
// UnionFind1 慢于 UnionFind2 size就是O(n)的n;
// UnionFind1 : 0.206028658 s UnionFind2 : 0.001796639 s
int size = 100000; int m = 100000; // UnionFind2 慢于 UnionFind1
// UnionFind1 : 4.361822269 s UnionFind2 : 9.56344783 s 1 JVM 访问数组连续空间速度快,两个操作都是O(h),树深度高。
UnionFind1 uf1 = new UnionFind1(size);
System.out.println("UnionFind1 : " + testUF(uf1, m) + " s");
UnionFind2 uf2 = new UnionFind2(size);
System.out.println("UnionFind2 : " + testUF(uf2, m) + " s");
}
}
充分考虑合并的两个树的特点: 9想加入原本的集合,可以是8直接连上9,但也可以是9指向根节点8。
package cn.mtianyan;/**
* 我们的第三版Union-Find
*/public class UnionFind3 implements UF { /**
* 我们的第三版Union-Find, 使用一个数组构建一棵指向父节点的树
* parent[i]表示第一个元素所指向的父节点
*/
private int[] parent; private int[] sz; // sz[i]表示以i为根的集合中元素个数
/**
* 构造函数
* @param size
*/
public UnionFind3(int size){
parent = new int[size];
sz = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < size ; i ++ ){
parent[i] = i;
sz[i] = 1;
}
} @Override
public int getSize(){ return parent.length;
} /**
* 查找过程, 查找元素p所对应的集合编号 O(h)复杂度, h为树的高度
* @param p
* @return
*/
private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while(p != parent[p])
p = parent[p]; // 不断上移,直到指向自己
return p;
} /**
* 查看元素p和元素q是否所属一个集合 O(h)复杂度, h为树的高度
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected( int p , int q ){ return find(p) == find(q);
} /**
* 合并元素p和元素q所属的集合 O(h)复杂度, h为树的高度
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if(pRoot == qRoot) return; // 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if(sz[pRoot] < sz[qRoot]){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else{ // sz[qRoot] <= sz[pRoot]
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}构造函数中sz进行初始化,UnionEelements中进行维护。
int size = 100000; int m = 100000;
UnionFind3 uf3 = new UnionFind3(size);
System.out.println("UnionFind3 : " + testUF(uf3, m) + " s");
基于Rank的优化
上一节中的优化目的是为了不要合并时树的高度疯狂增加,尽量少的增加。
rank就是树的高度,深度。

节点多不一定深度大,8合并过来,深度从2,3变为了4。

因此更合理的是如上图,深度低的合并到深度高的。
基于raink的优化 rank[i]表示根节点为i的树的高度
package cn.mtianyan;/**
* 我们的第四版Union-Find
*/public class UnionFind4 implements UF { private int[] parent; private int[] rank; // rank[i]表示以i为根的集合所表示的树的层数
/**
* 构造函数
* @param size
*/
public UnionFind4(int size){
parent = new int[size];
rank = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < size ; i ++ ){
parent[i] = i;
rank[i] = 1;
}
} @Override
public int getSize(){ return parent.length;
} /**
* 查找过程, 查找元素p所对应的集合编号 O(h)复杂度, h为树的高度
* @param p
* @return
*/
private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while(p != parent[p])
p = parent[p]; // 不断上移,直到指向自己
return p;
} /**
* 查看元素p和元素q是否所属一个集合 O(h)复杂度, h为树的高度
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected( int p , int q ){ return find(p) == find(q);
} /**
* 合并元素p和元素q所属的集 O(h)复杂度, h为树的高度
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return; // 根据两个元素所在树的rank不同判断合并方向
// 将rank低的集合合并到rank高的集合上
if(rank[pRoot] < rank[qRoot])
parent[pRoot] = qRoot; // 合并以后,上限没变
else if(rank[qRoot] < rank[pRoot])
parent[qRoot] = pRoot; else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此时 才需要维护rank的值
}
}
}UnionFind4 uf4 = new UnionFind4(size);
System.out.println("UnionFind4 : " + testUF(uf4, m) + " s");
int size = 10000000; int m = 10000000;
运行结果:

作者:天涯明月笙
链接:https://www.jianshu.com/p/cf7e2aeb0cc3





