MySQL 数据表设计规范
上一小节介绍了如何设计数据表,并合理选择字段数据类型新建数据表,本小节来介绍数据表的设计规范,主要遵循数据表设计三范式和适当的反范式化。
1.第一设计范式
第一设计范式要求表中字段都是不可再分的,如果实体中的某个属性有多个值时,必须拆分为不同的属性 。通俗理解即一个字段只存储一项信息,如下图所示,其中联系方式可以拆分为手机、邮箱、固定电话,所以下图不符合数据表第一设计范式要求:
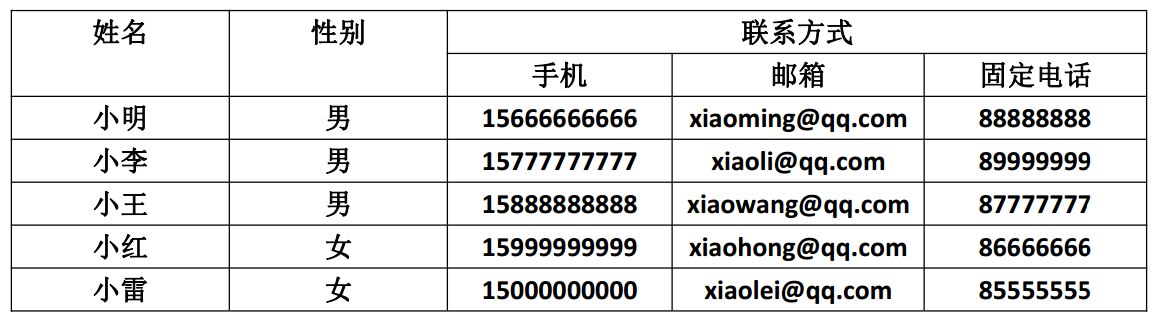
纠正之后符合第一设计范式要求的如下图所示:
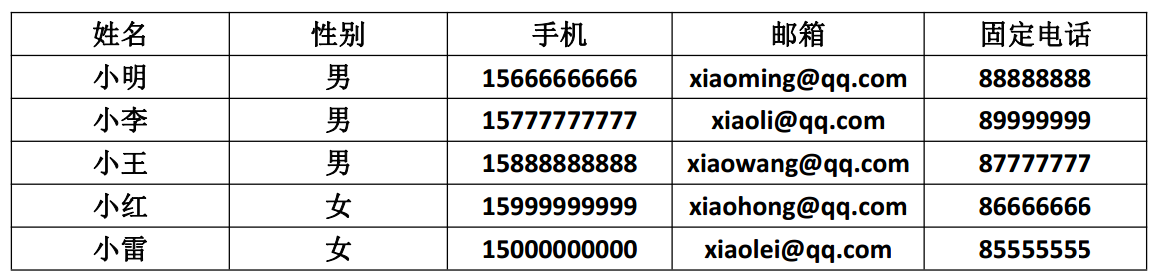
2.第二设计范式
第二设计范式要求表中必须存在业务主键,并且全部非主键依赖于业务主键。第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分,为实现区分通常需要我们设计一个主键来实现(这里的主键不包含业务逻辑)。
即满足第一范式前提,当存在多个主键的时候,才会发生不符合第二范式的情况。比如有两个主键,不能存在这样的属性,它只依赖于其中一个主键,这就是不符合第二范式。通俗理解是任意一个字段都只依赖表中的同一个字段。(涉及到表的拆分)。如下图数据表字段中 id 即为业务主键:
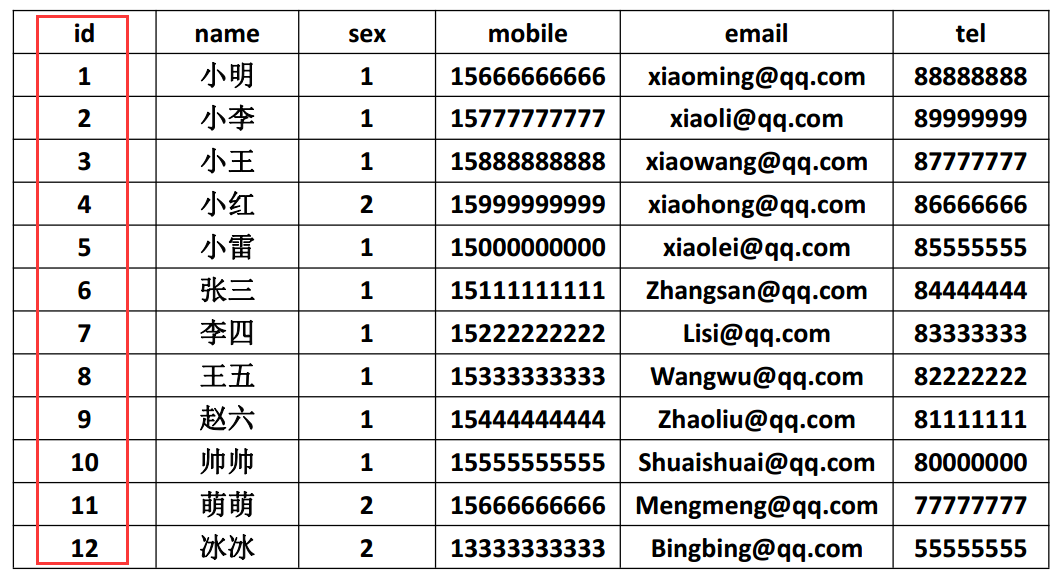
3.第三设计范式
满足第三范式(3NF)必须先满足第二范式(2NF),简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段。就是说表的信息如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键 join 就用外键 join)。很多时候我们为了满足第三范式往往会把一张表分成多张表。
即满足第二范式前提,如果某一属性依赖于其他非主键属性,而其他非主键属性又依赖于主键,那么这个属性就是间接依赖于主键,这被称作传递依赖于主属性。 通俗解释就是一张表最多只存两层同类型信息。
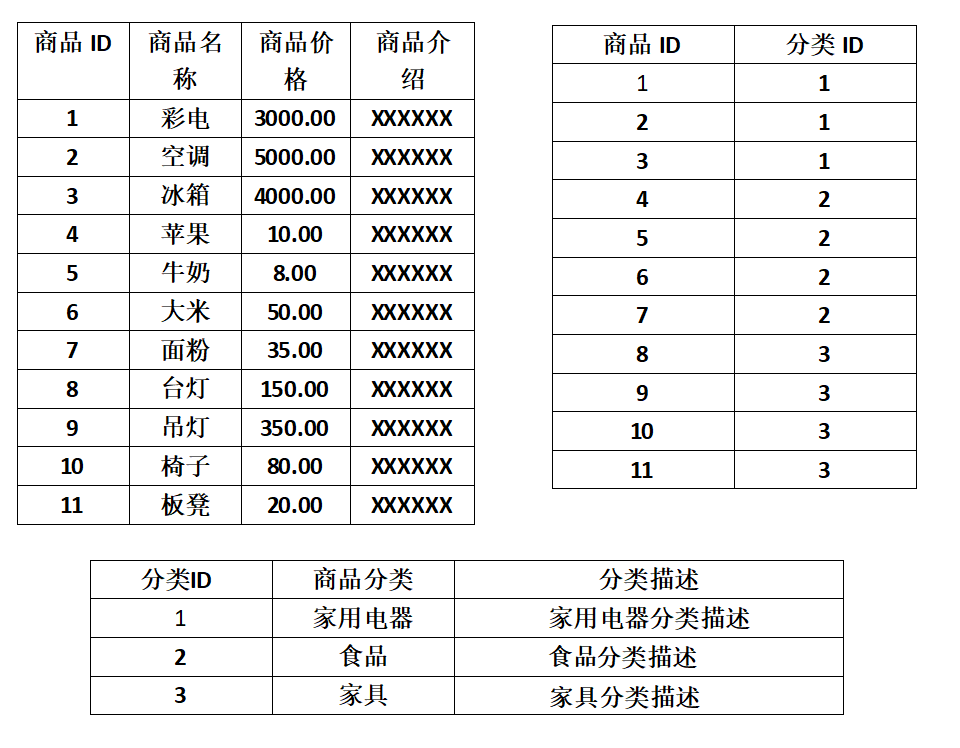
如下图所示的商品表不符合第三设计范式:
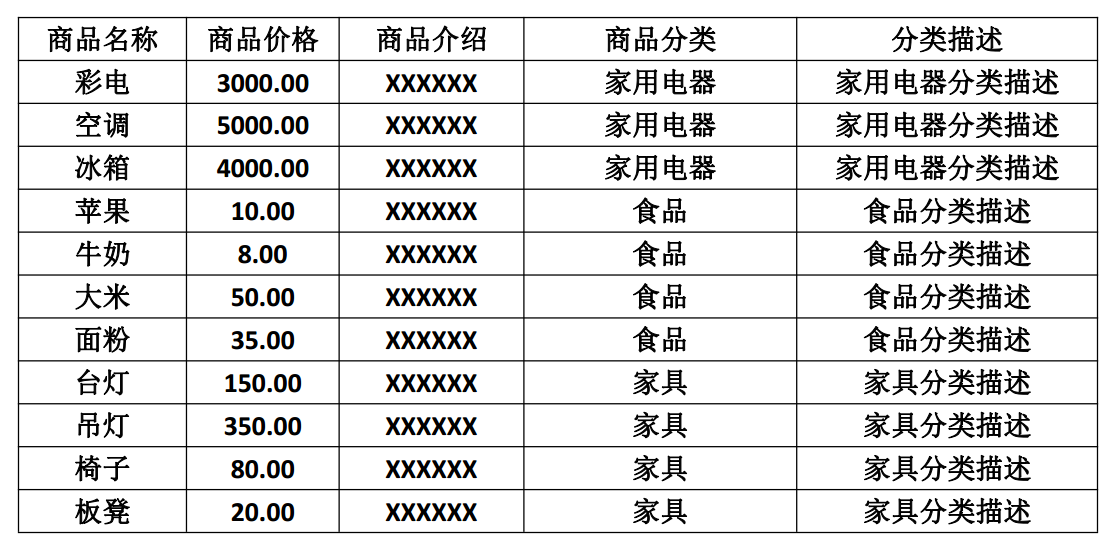
如图所示,商品分类和分类描述字段冗余,每次添加相同分类商品都会使数据重复,浪费存储空间,可以将表拆分成如下三个表:
遵循数据表设计三范式可以避免字段值的重复存储,提升存储效率,节省存储空间,将各个数据之间分的更细,增加表的冗余性,为后期维护和拓展打下坚实的基础。高性能的 MySQL 数据库第一步就是从数据表合理设计开始的。
4.反范式化设计
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,提高读性能,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于 DML 的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
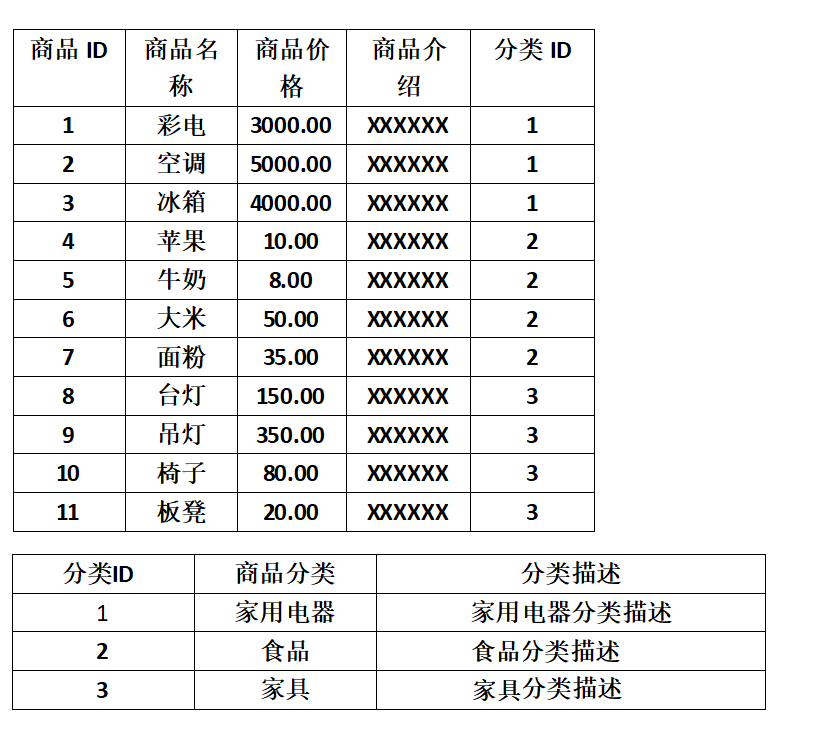
如下图所示,上面的例子可以稍微反范式化设计一下,可以减少实际数据查询的连表查询操作,提升效率:
5.小结
本节介绍了数据库设计三范式,实际工作中,只要遵循数据库设计第三范式要求即可,数据表的良好设计可以为今后更复杂的业务逻辑减少不必要的麻烦,适当反范式化设计可以提升查询效率和工作效率。