HTTP 协议与网站基本开发流程
上节课我们学习了 Web 开发中必备的一些 HTML/CSS/JS 这一节中我们会继续介绍下 Web 开发中的一些基础知识,包括常用术语、HTTP 协议、
1. Web 服务中的常用术语
在正式开始 Django 项目开发之前,我们需要掌握一些 Web 开发中常见的术语。Web 服务和网站在某种程度上是等价的,因此后面描述时并不区分这两个概念。
-
客户端:用户主机上运行并连接到互联网的应用程序,一般而言是指浏览器。用户通过浏览器实现和网站的数据交互;
-
服务:服务主要接受和处理来自互联网的请求。服务一般部署在某台主机上,监听某个端口,等待用户请求;
-
域名:用于标识一个或者多个 IP 地址;
-
IP:互联网协议地址。互联网上的每台计算机都有一个 IP 地址,用于识别和通信。IP 地址由 4 组数组组成,以小数点分割,这些被称为逻辑地址;
-
DNS:域名系统服务,主要用于网络域名与 IP 地址的相互转换;
-
ISP:互联网服务提供商;
-
TCP/IP:传输控制协议 / 网际协议,是当前互联网使用的主要通信协议。
除了上述基础术语之外,我们还有两个非常重要的知识点需要掌握,分别是 HTTP 协议和 URL 的组成。
1.1 HTTP 协议
HTTP 协议,即超文本传输协议,是一个客户端终端(用户)和服务器端(网站)请求和应答的标准。这也是 Web 开发基础。因为大部分网站或者 Web 服务的前后端交互几乎都是走 HTTP 请求。HTTP 协议定义 Web 客户端如何从 Web 服务器请求 Web 页面,以及服务器如何把 Web 页面传送给客户端。
HTTP 协议采用了请求 / 响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
HTTP 协议有如下特点:
-
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于 HTTP 协议简单,使得 HTTP 服务器的程序规模小,因而通信速度很快;
-
灵活:HTTP 允许传输任意类型的数据对象;
-
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间;
-
无状态:HTTP 协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
1.1.1 HTTP 常见请求
在 HTTP/1.1 协议中共定义了八种方法(也叫 “动作”)来以不同方式操作指定的资源,目前我们比较常见和常用的有以下四个:
-
GET 请求:向指定的资源发出 “显示 “请求。使用 GET 方法应该只用在读取数据,而不应当被用于产生 “副作用” 的操作中。一般在浏览器中直接敲击 URL 并按回车键是执行的 GET 请求;
-
POST 请求:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和 / 或已有资源的修改;
-
PUT 请求:从客户端向服务器传送的数据取代指定的文档的内容;
-
DELETE 请求:请求服务器删除指定的页面。
这四种请求和数据的增删改查(CRUD) 可以看成是相对应的,一般在设计 URL 接口时,也会默认使用这样特性,让 GET 请求对应查询数据、POST 请求对应数据的新增等等,这样的接口设计出来才会具备良好的 Restful 风格。
1.1.2 HTTP 状态码
HTTP 请求通常会返回一个状态码,常见的 HTTP 状态码有:
-
2xx:正确类。表示用户请求被正确接收、理解和处理;
- 200 - 请求成功;
-
3xx:重定向类。表示没有请求成功,必须采取进一步的动作;
-
301 - 资源(网页等)被永久转移到其它 URL;
-
302 - 资源临时移动,资源只是临时被移动,客户端应继续使用原有 URI ;
-
-
4xx:客户端错误。表示客户端提交的请求包含语法错误或不能正确执行;
-
400 - 往往是 Bad Request 错误。是指请求的方法不对;
-
401 - 用户没有访问权限,需要进行身份认证;
-
403 - 禁止访问;
-
404 - 资源不存在,Not Found 错误;
-
-
5xx:服务端错误。一般是说明服务器出现了问题;
- 503 - 服务端错误,一般是服务器内部处理异常。
实操: 用 curl 命令模拟发送 HTTP 请求。
[root@server ~]# curl -I -XGET http://www.baidu.com/index.html
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 2381
Content-Type: text/html
Date: Sun, 08 Mar 2020 14:36:01 GMT
Etag: "588604c8-94d"
Last-Modified: Mon, 23 Jan 2017 13:27:36 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
1.2 URL 介绍
URL 的中文名称为统一资源定位符。简单来说,它就是一个地址,是我们请求互联网上某一个资源地址或者某一个服务接口的完整路径。我们找一个网站的实际 URL 例子,来说明下完整 URL 的组成部分:
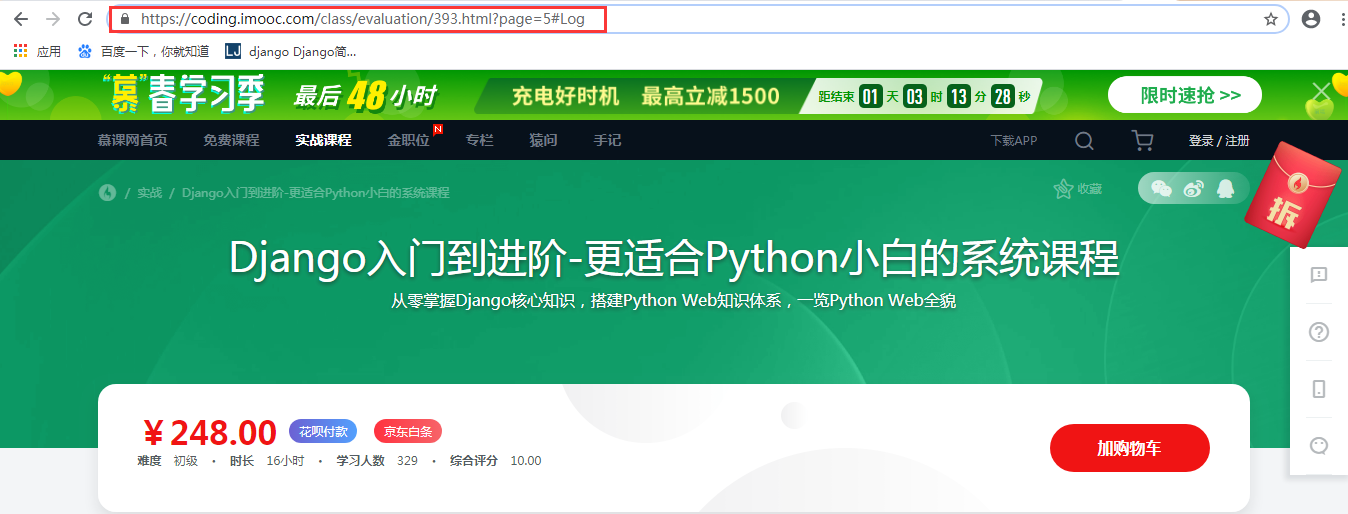
这个慕课网上的完整的 URL 地址为: https://coding.imooc.com/class/evaluation/393.html?page=5#Log。URL 的格式如下:
schema://host[:port]/path…/[?query-string]#fragment
-
schema:表示协议,常见的有 http/https 协议,还有 ftp 协议,ws/wss 协议(websocket)等等;
-
host:域名或者直接是 IP 地址。本例子使用的是慕课网的一个子域名:
coding.imooc.com; -
port:不写会使用默认端口,非默认地址一定要写明端口号。本例中使用默认端口
443; -
path:资源地址,会有多个
/表示路径层级。本例中的路径为/class/evaluation/393.html; -
query-string:如果 URL 带参数,放到
?之后,#号之前,使用key=value形式,多个参数之间使用&进行连接。本例中的参数是?page=5; -
锚点:或称片段(fragment),HTTP 请求不包括锚部分,从
#开始到最后,都是锚部分。本例中的锚部分是 Log。锚部分不是一个 URL 必须的部分。
2. 网站运行原理
在了解上面这些基本术语后,我们介绍下当在浏览器中敲下 www.baidu.com 这个 URL,到百度返回给我们搜索首页,这个过程中究竟发生了哪些事情?
-
解析输入 URL 中包含的信息,比如 HTTP 协议和域名 (
baidu.com); -
客户端先检查本地是否有对应的 IP 地址,若找到则返回响应的 IP 地址。若没找到则请求在 ISP 的 DNS 服务器上。如果还没找到,则请求会被发向根域名服务器,直到找到对应的 IP 地址;
-
浏览器在 DNS 服务器中找到对应域名的 IP 地址,然后结合 URL 中的端口(没有指明端口则使用默认端口,HTTP 协议的默认端口是 80,HTTPS 的默认端口是 443) 组成新的请求 URL,并与百度的 Web 服务建立 TCP 连接;
-
浏览器根据用户操作向百度的 Web 服务器发送 HTTP 请求;
-
Web 服务器接收到该请求后会根据请求的路径查找对应的 Web 资源并返回;
-
最后客户端浏览器将这些返回的 Web 信息 (包括图片、HTML 静态页面,JS 等)组织成用户可以查看的网页形式,最后就得到了我们熟悉的那个 百度一下,你就知道 的搜索主页了。
3. 网站开发的基本流程
技术发展至今,随着各类 Web 框架的出现,一周甚至几天上线一个网站已经不再是梦。但是想要做好一个大型网站,同样是不容易的。现在来谈一下正规公司的网站,也即 Web 服务开发的一个大致流程,基本如下:
-
项目需求分析:产品经理在拿到项目之后,需要和架构师一起进行需求分析、架构的设计,这一步非常重要,没有理清需求,后面只会越做越乱;没有好的架构设计,后续上线后会面临各种严重问题,比如没有使用主备数据库模式,可能存在数据丢失风险等到。此外,一个正规的网站都需要有自己的域名,一定数量的服务主机等到,这些都是事先规划好的。当然,也要求网站架构能支持后端服务的水平扩展;
-
规划网站页面并设计网站草图:这一步最好有一个美工团队专门负责。美工出图,程序员负责实现;
-
网站开发阶段:如果架构是前后端分离,那么前端和后端服务可以同时开工,两不耽误。往往有了清晰的需求后,代码实现起来是比较快速的;
-
测试和上线:正常情况下,开发完成之后会有一个测试团队对网站各方面功能进行严格测试,然后将 bug 单交给开发团队返工。开发团队修改完后,继续由测试团队进行测试,如此循环直到问题被扫平,便可以正式部署和上线;
-
最后便是网站的维护和推广:网站上线后也会遇到很多问题,比如竞争对手的恶意 DDOS 攻击,网站被人挂马、钓鱼以及用户访问量过大后导致服务瘫痪等等,此时需要运维人员定期检查网站运行状态,保证线上环境的稳定运行,同时也需要对网站进行 SEO 和推广吸引客流。
4. 小结
今天我们介绍了 Web 编程的相关术语,重点介绍了 HTTP 协议和 URL。接下来,我们介绍了网站的一个运行原理和开发的基本流程,有了这些知识储备后,我们就可以正式开始学习 Django 了。