1. 前言
我们今天要通过了解链表的原理来掌握链表这个重要的数据结构,随后用我们了解到的链表的知识来重新认识一下我们每天都要接触的最常见的链表 java.util.LinkedList 类。
2. 数组的缺陷
数组作为我们最常见的通用数据结构,几乎可以实现我们常见的所有数据结构。然而,数组的特点决定了它的适用场景必然是有限的,比如占用空间大小固定,空间过小可能不能满足数据量的要求,空间过大又会造成内存资源的浪费,再比如数组的插入效率很低等等。
那有没有一种插入效率很高,而且不需要频繁扩容的基本数据结构呢?答案是肯定的,它就是 —— 链表。

3. 什么是链表
链表是一组链式结构的数据节点,每个节点都包含保存数据的部分,以及用来指向上一个或下一个节点位置的链接信息。链表是一种线性表,它可以灵活的根据数据大小来使用内存空间,但是由于它在内存中不是连续存储的,所以根据角标查询的效率很低,同时由于每一个节点上除了数据信息还额外存储了与其他节点的链接信息,所以对空间的占用也更大一些。
4. 单向链表
我们首先通过最简单的链表 —— 单向链表来熟悉一下链表的结构和存储原理。
单链表的每一个节点我们称之为 Node,都包含一个存储数据的部分我们称为之 data,还有一部分用来存储下一个节点的地址我们称之为 links。链表的第一个节点我们称之为 head 头节点。
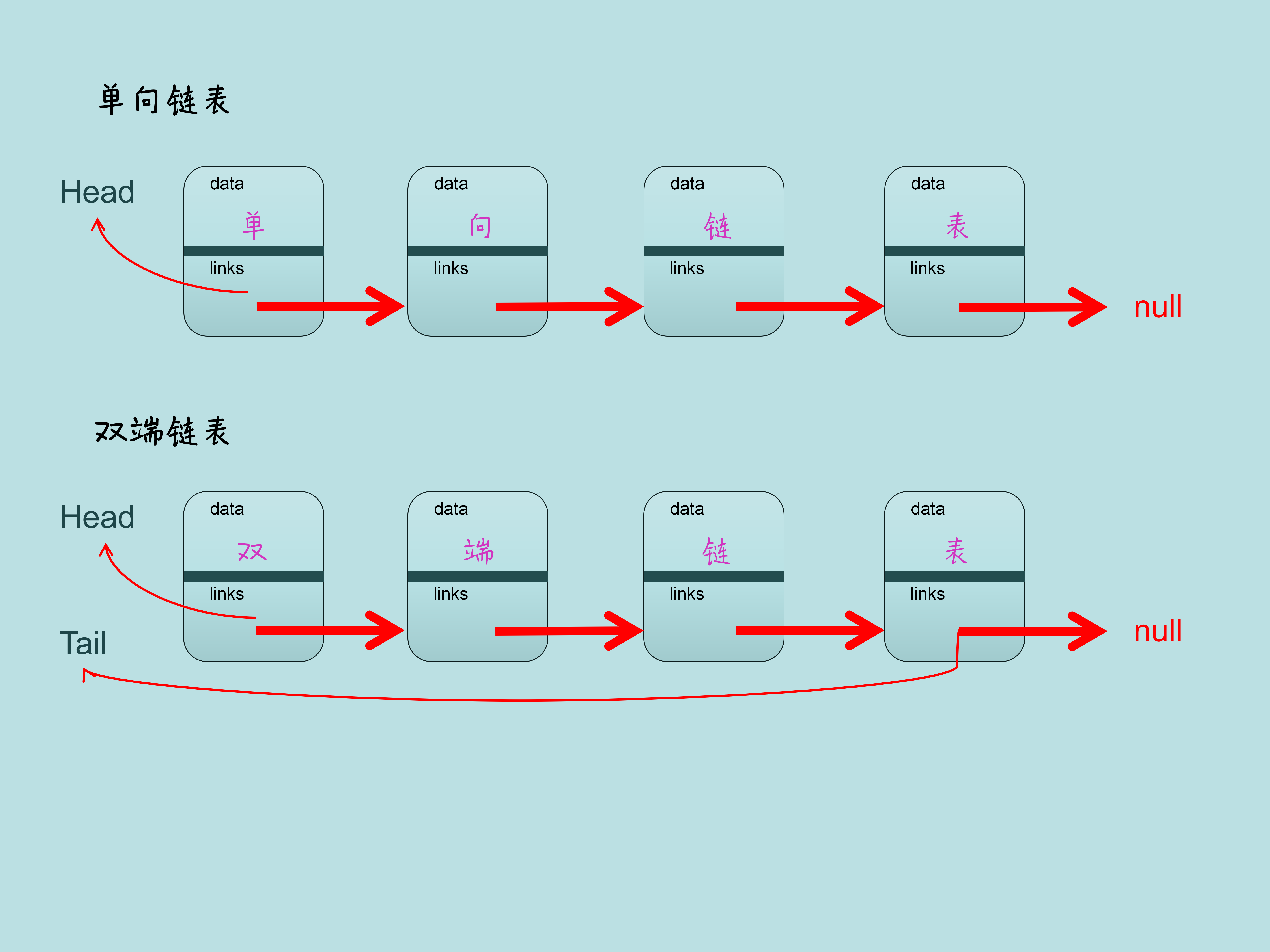
5. 双端链表
单向链表由于只记录了自己的下一个节点,所以它的访问方向是单向的。如果我想在最后一个节点后添加元素,就需要从第一个节点开始挨个遍历,很不方便,于是我们给链表的最后一个节点标示为 tail 尾节点,便于我们在最后一个节点插入元素的时候可以直接引用尾节点,这就叫做双端链表。
6. 双向链表
前面讲的单向链表和双端链表其实主要是让大家了解链表的存储原理,实际我们使用最多的是双向链表,双向链表在单向链表的基础上同时记录了上一个节点和下一个节点两个指针信息,遍历更加方便。
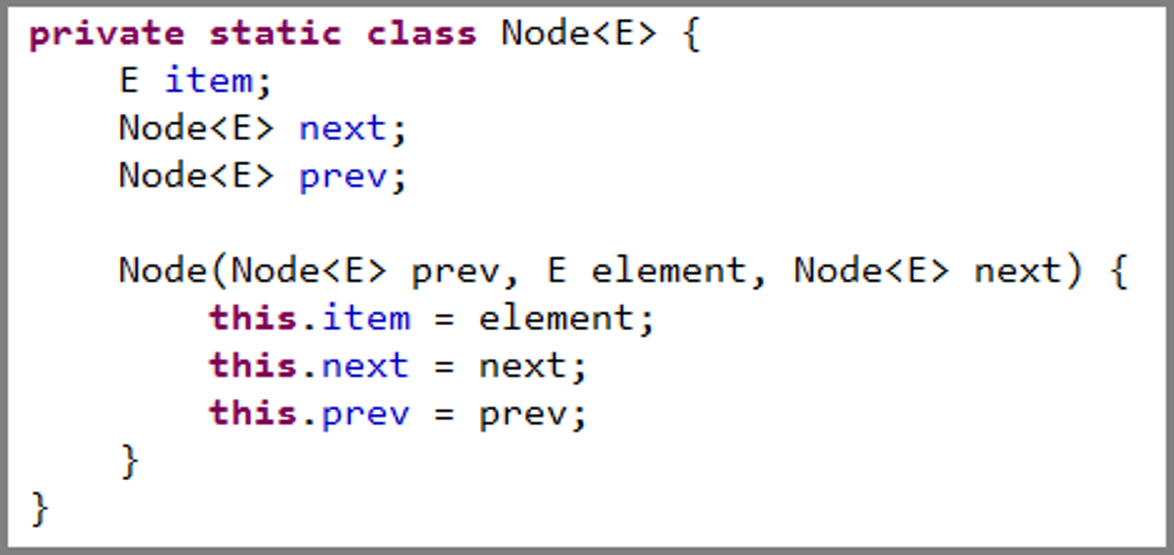
Java 中对于双向链表有现成的实现,就是我们非常熟悉的 java.util.LinkedList。在源码中我们可以看到 LinkedList 把节点定义成三个部分:元素、上一节点和下一节点。
其实链表的最大的魅力就是可以优雅高效地插入数据,它只需要在要插入的位置修改前后节点的指针就可以完成,完全不需要移动其他的数据。LinkedList 源码中是这样实现的:
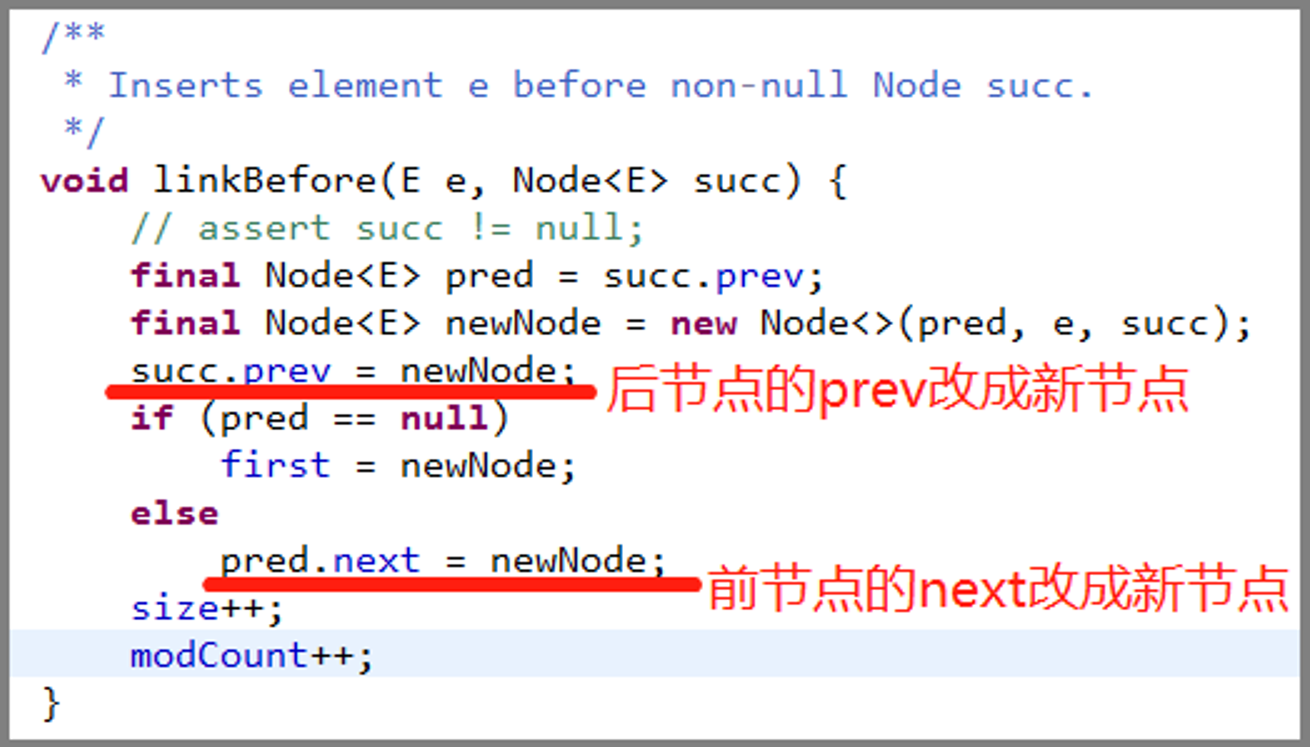
结合上图,我们用动图来模拟实现一下 LinkedList 的 add 方法:
动图中的节点位置我故意摆放得很零散,就是为了突出这些节点在内存中的位置并不是连续的,这也体现出了链表可以对内存里这些零散角落高效利用的特点。
对于删除操作,链表完全可以根据插入的逆操作来高效优雅地完成。
7. 链表的优缺点
链表的优点是大小可变,插入和删除的效率很高,缺点是只能通过顺序指针访问,查询的效率较低。无图无真相,我们结合图片看一下他们分别是如何获取指定元素的。先来看下基于数组的 ArrayList:
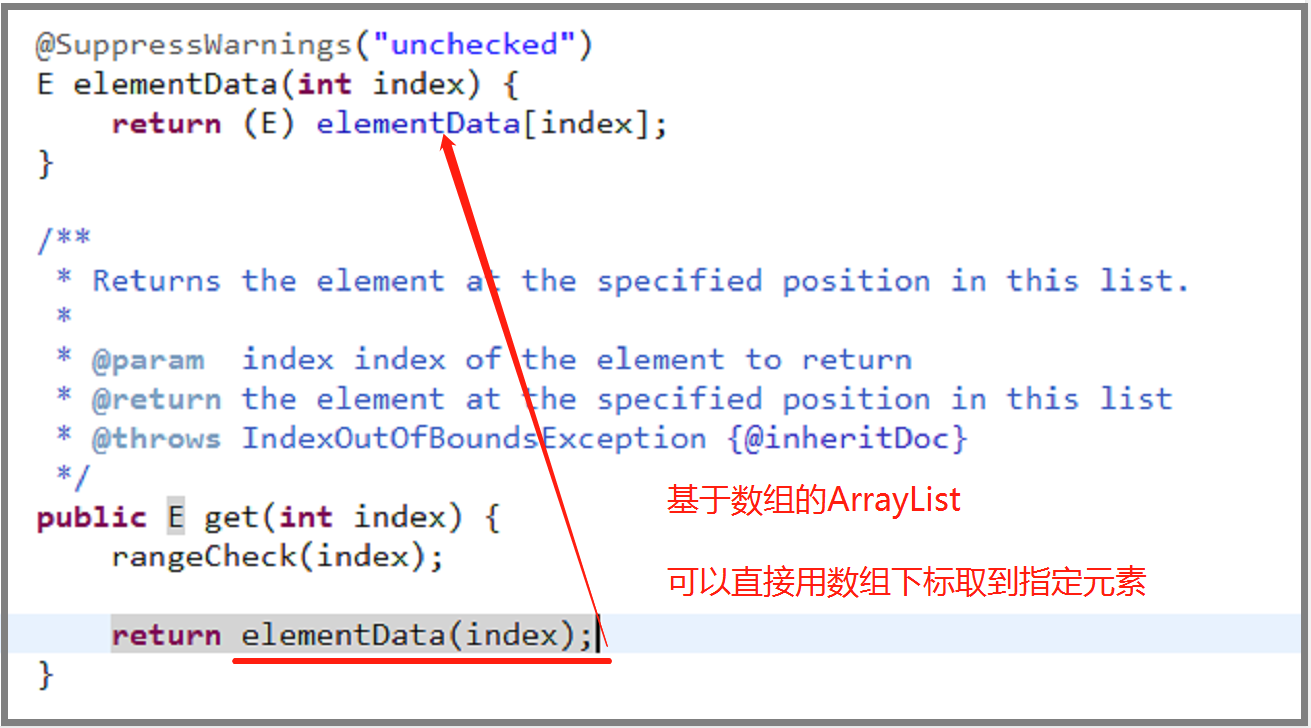
再来看下基于链表的 LinkedList:
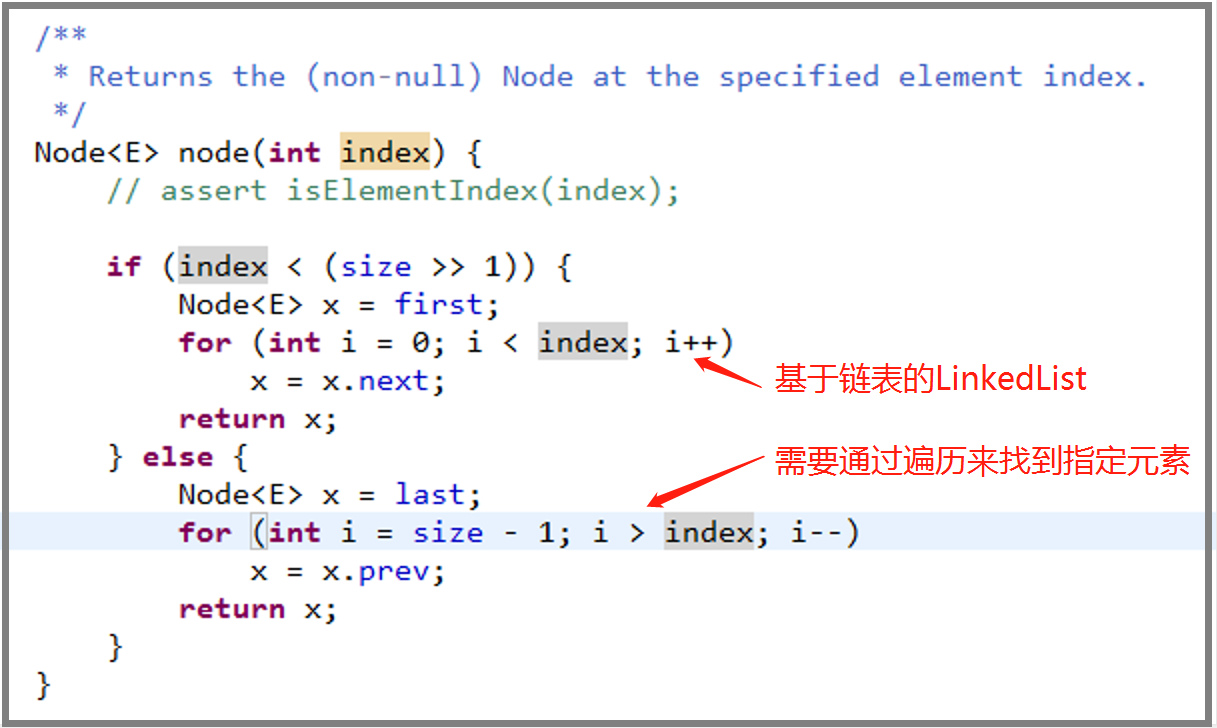
对比基于数组的 ArrayList 和基于链表的 LinkedList 的 get (index i) 方法的实现就会发现,链表需要遍历才能返回想要的元素,所以效率才比较低下。知道了链表的这些特性,我们今后在使用这一数据结构的时候就知道如何让它在合适的时候发挥它的最大优势咯。
8. 小结
这一小节我们知道了链表是一种线性结构的基本数据类型,可以分为单向链表、双端链表、双向链表等,内部实现的原理都是在每一个节点上除了记录数据外,还记录了上一个或下一个节点的位置信息。它的特点是插入和删除的效率很高,查询的效率较低。
代码预览
退出