ZooKeeper 实现分布式 ID
1. 前言
在我们使用数据库进行数据存储时,会给数据加上唯一标识,也就是我们常说的 ID,通过唯一的 ID, 我们可以精确的定位到每一条数据,设置 ID 常用的方式有 MySQL 的主键自增,UUID,雪花算法等。
除了数据库的数据需要进行唯一标识的设置之外,在分布式环境中,集群中的每一个服务或者分布式服务的地址列表,我们都可以为它们设置唯一标识 ID,通过这个 ID 我们可以更方便的获取它们的服务提供者的信息和地址列表等数据。
本节我们就来学习如何使用 Zookeeper 来生成分布式的全局唯一 ID。
2. 分布式 ID
在使用 Zookeeper 生成分布式的全局唯一 ID 之前,我们先来了解什么是分布式 ID,为什么要使用分布式 ID ,以及分布式 ID 的实现方式有哪些。
分布式 ID,也就是在分布式的环境下,全局的唯一的 ID 。那么我们为什么要使用分布式 ID 呢?
在单体结构的应用中,我们可以使用 MySQL 数据库的主键自增来为我们的数据设置唯一标识 ID,但是在分布式环境中,单个数据库的吞吐量成为整个应用的性能瓶颈,我们就可以搭建数据库集群来提升数据库的性能,此时如果还使用 MySQL 的主键自增来设置数据 ID 的话,就会出现重复的 ID,这样就会出现主键冲突的情况。
如果使用分布式的全局唯一 ID 就不用担心会出现这个问题了。那么分布式 ID 的实现方式有哪些呢?接下来我们就对分布式 ID 的实现方式进行介绍。
2.1 分布式 ID 的实现方式
本小节我们来简单介绍一下常用的分布式 ID 的实现方式,例如:UUID,Redis,雪花算法等。
-
UUID
Universally Unique Identifier 通用唯一标识符,由 32 个字符组成,采用 16 进制进行编码,定义了在时间和空间都完全唯一的系统信息。
在 Java 中可以使用 java.util.UUID 的 randomUUID() 方法来获得:
java.util.UUID.randomUUID().toString();UUID 可以在本地生成,生成速度快,不依赖网络和其它服务,但是 UUID 没有可以识别的特点,也没有顺序性。
-
Redis 实现分布式 ID
我们都知道 Redis 的性能非常高,而且还可以搭建集群。我们可以使用 Redis 的 Incr 命令来把 <key,value> 中 key 的数值加 1 并返回,如果这个 key 不存在,则 key 值会被初始化为 0,再执行 Incr 命令来进行加 1 操作。
// 使用 incr(key) 来让 key 加 1 long id = jedis.incr("id");使用 Redis 的方式生成分布式 ID 需要依赖 Redis 服务,还要保证 Redis 的高可用,否则 Redis 服务宕机会影响整个应用。
-
雪花算法
SnowFlake 雪花算法是 Twitter 公司推出的⼀个⽤于⽣成分布式 ID 的策略,基于这个算法可以生成 64 位 Long 型的 ID,它是由 1 位符号位,41 位的时间戳毫秒数,10 位的机器 ID,12 位的序列号这 4 种元素来组成的。理论上,雪花算法每秒可以生成 400 多万个 ID,完全可以支撑住分布式环境下高并发的场景。
一些公司在雪花算法的基础上实现了自己的分布式 ID 的算法,比如:滴滴的 Tinyid,百度的 UidGenerator,美团的 Leaf 等。
简单介绍了一些分布式 ID 的实现方式,接下来我们就使用 Zookeeper 来实现分布式 ID 。
3. Zookeeper 实现分布式 ID
在 Zookeeper 中,我们可以使用 Zookeeper 的 顺序节点来完成分布式 ID 的生成。这里我们来回顾一下顺序节点的特性。
顺序节点,在 Zookeeper 客户端创建顺序节点时,Zookeeper 会根据创建的时间顺序,在节点名称后添加 10 位的顺序编号。
这里我们使用在 Zookeeper Curator 一节创建的 Spring Boot 测试项目来进行测试:
@SpringBootTest
class CuratorDemoApplicationTests {
@Autowired
private CuratorService curatorService;
@Test
void contextLoads() throws Exception {
// 获取客户端
CuratorFramework client = curatorService.getCuratorClient();
// 开启会话
client.start();
// 第一次创建 /wiki-
String s = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/wiki-");
// 输出第一次创建的 /wiki-
System.out.println(s);
// 第二次创建 /wiki-
String s1 = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/wiki-");
// 输出第二次创建的 /wiki-
System.out.println(s1);
// 第三次创建 /wiki-
String s2 = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/wiki-");
// 输出第三次创建的 /wiki-
System.out.println(s2);
// 关闭客户端
client.close();
}
}
执行测试方法。控制台输出:
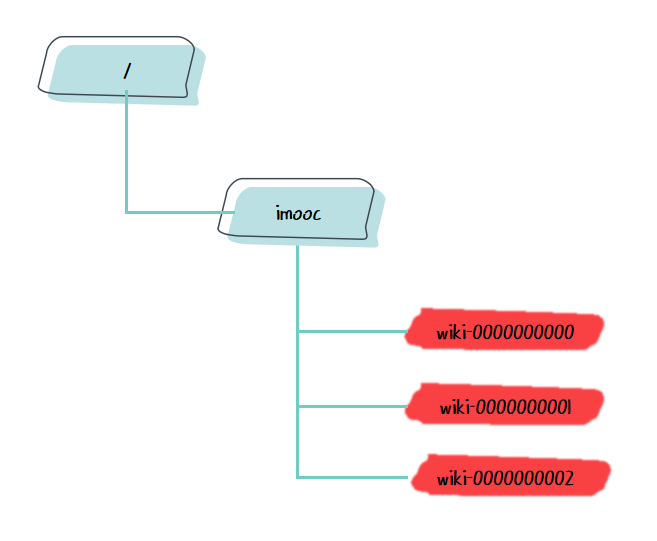
/wiki-0000000000
/wiki-0000000001
/wiki-0000000002
我们可以观察到,每个 /wiki- 节点后都增加了 10 位的顺序编号,而且都是按照添加顺序来进行编号的。
再加上我们在创建 Curator 客户端时设置的命名空间 imooc,就可以形成完整的节点路径 /imooc/wiki-0000000000,这个完整的路径就可以当作我们的分布式 ID 了,而且这样我们也能根据命名空间来区别不同的业务模块,还可以添加不同的命名空间来扩展不同的业务模块。
4. 总结
在本节内容中,我们学习了什么是分布式 ID ,在分布式环境下为什么要使用分布式 ID,我们还介绍了几种常用的分布式 ID 实现方式,以及它们的优缺点,最后我们回顾了 Zookeeper 顺序节点, 并使用 Zookeeper 的顺序节点的特性实现了分布式 ID 的生成。以下是本节内容的总结:
- 为什么要使用分布式 ID 。
- 分布式 ID 实现方式。
- 使用 Zookeeper 的顺序节点实现分布式 ID。