java.io.IOException: No input paths specified in job

neocyl
2019-04-25 15:29
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
java.io.IOException: No input paths specified in job
step1运行失败~~~
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:239)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1758)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
请问一下各位大神,这个情况有遇到的吗?百度了各种情况,都 没有解决,
5回答
-

- 慕粉218578
- 2019-07-31 13:51:02
你的主机名是localhost找host文件的时候,转为在你的运行电脑上,也就是本机,并不是虚拟机,所以就没有那个文件,建议修改虚拟机主机名,或者修改hosts文件。
-

- Blossom7
- 2019-05-05 08:36:25
没有,它变成了另外一个错误,你要在编译器中连接虚拟机,还要添加相关的矩阵文件
-
- Blossom7
- 2019-04-25 16:28:42
好像不是这个原因
-
- Blossom7
- 2019-04-25 16:21:43
我也有这个问题,我在想是不是虚拟机连接问题
-

- neocyl
- 2019-04-25 15:31:18
package step1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MR1 {
//输入文件相对路径
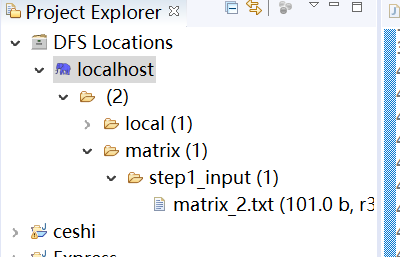
private static String inPath = "/matrix/step1_input/matrix_2.txt";
//输出文件的相对路径
private static String outPath = "/matrix/step1_output";
//hdfs的地址
private static String hdfs = "hdfs://localhost:9000";
public int run() {
try {
//创建job配置类
Configuration conf = new Configuration();
//设置hdfs的地址
conf.set("cf.defaultFS", hdfs);
//创建一个job实例
Job job = Job.getInstance(conf,"step1");
//设置job 的主类
job.setJarByClass(MR1.class);
//设置job 的mapper类及reducer类
job.setMapperClass(Mapper1.class);
job.setReducerClass(Reducer1.class);
//设置mapper输出的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置reducer输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileSystem fs =FileSystem.get(conf);
//设置输入和输出路径
Path inputPath = new Path(inPath);
if(fs.exists(inputPath)) {
FileInputFormat.addInputPath(job, inputPath);
}
Path outputPath = new Path(outPath);
fs.delete(outputPath,true);
FileOutputFormat.setOutputPath(job, outputPath);
return job.waitForCompletion(true)?1:-1;
} catch (IOException | ClassNotFoundException | InterruptedException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) {
int result = -1;
result =new MR1().run();
if(result == 1) {
System.out.println("step1运行成功~~~");
}else if(result == -1) {
System.out.println("step1运行失败~~~");
}
}
}
贴上源码


Hadoop进阶
24252 学习 · 72 问题
相似问题