-
 两万七千历
两万七千历
- 只写join 算什么连接,左连接吗?
JOIN 是 inner join 的缩写。
Left join 是left outer join的缩写
- 2020-04-04 3回答·2377浏览
-
 Henry_Liu
Henry_Liu
- 试着写一下我的语句和理解,比老师的更加有可读性,好理解
1.括号中的子查询连接两张表,很好理解。
2.子查询得到的集合再去连接user_kills表,条件c.id = d.user_id,很好理解。
条件c.kills <= d.kills的作用,使得杀怪最多的天数只出现一次,第二多的天数出现两次,如此类推。
重复出现的次数,其实就等于杀怪数的排名。放两个图,不懂的人结合图细细品一下。


3.GROUP BY c.user_name, c.timestr分组。GROUP BY有去除重复的作用,此时的表:

4.HAVING COUNT(*) <= 2,把重复出现次数小于等于2的保留,也就是杀怪最多的两天。
有人可能会卡在这一步,觉得不好理解。可以结合第二步来看,虽然分组后看不到重复,但是通过函数可以计算出来。
再放个图(没加HAVING COUNT(*) <= 2的时候,而且增加count列,方便理解),还不懂就没救了。
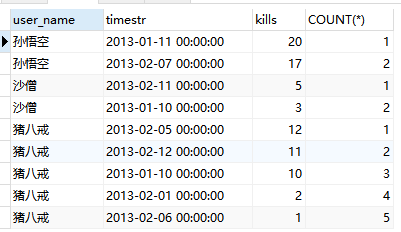
5.ORDER BY c.user_name, c.kills DESC,排序就不用解释了吧。
- 2020-01-10 4回答·1124浏览
-
 慕村9412698
慕村9412698
- 想要一个数据库文件
?怎么上传文件?我想传一个sql文件,传不上来
- 2019-07-17 1回答·866浏览
-
 qq_耶丑_imuzC6
qq_耶丑_imuzC6
- SELECT的查询输出
select user_id,timestr,kills,(slelect count(*) from user_kills b where b-user_id=auser_id and a.lills <= b.killls) ad cnt from use_kills a group by user_id = d.id here
- 2018-11-07 1回答·1497浏览
-
 慕娘9557946
慕娘9557946
- 分组后取出每组top-n的题目答案有误
嗯是的
- 2017-08-26 1回答·1503浏览
-
 Frank_Fu4373300
Frank_Fu4373300
- Mysql
多层子查询
- 2017-07-06 3回答·1499浏览
-
 静美书斋
静美书斋
- 关于修改表中数据后查询出不符合预期结果的尝试
点赞,确实是,偶然发现,那就是问题了,确实是没有考虑完全。(select count(*) from user_kill b where b.user_id = a.user_id and a.kills <= b.kills ) cnt,这个语句是达不到排序目的的,正如你说,猪八戒有12、10、10 这种记录时,针对12,排出结果是1,最对第一个、第二个10,排出的结果都是3,后面条件 where cnt <= 2 直接把两条10的记录过滤掉了。
- 2017-05-25 4回答·1820浏览
-
 Steven36
Steven36
- 如何的到创建表的语句呢?
Create Database If Not Exists test DEFAULT Character Set UTF8; use test; SET names utf8; DROP TABLE IF EXISTS user1; DROP TABLE IF EXISTS user2; DROP TABLE IF EXISTS user_kills; CREATE TABLE IF NOT EXISTS user1 ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(45) NOT NULL , over VARCHAR(45) NOT NULL , PRIMARY KEY(id)) DEFAULT CHARACTER SET = utf8; CREATE TABLE IF NOT EXISTS user2 ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(45) NOT NULL , over VARCHAR(45) NOT NULL , PRIMARY KEY(id)) DEFAULT CHARACTER SET = utf8; CREATE TABLE IF NOT EXISTS user_kills ( id INT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, user_name VARCHAR(45) NOT NULL , timestr DATETIME NOT NULL, kills INT NOT NULL , PRIMARY KEY(id)) DEFAULT CHARACTER SET = utf8; INSERT INTO user1(user_name, over) VALUES ( '唐僧', '旃檀功德佛' ),( '猪八戒', '净坛使者' ),( '孙悟空', '斗战神佛' ),( '沙僧', '金身罗汉' ); INSERT INTO user2(user_name, over) VALUES ( '孙悟空', '成佛' ),( '牛魔王', '被降服' ),( '鹏魔王', '被降服' ),( '蛟魔王', '被降服' ),( '狮骆王', '被降服' ); INSERT INTO user_kills(user_name, timestr, kills, user_id) VALUES ( '孙悟空', '2013-01-11 00:00:00', 20, 3 ),( '沙僧', '2013-01-10 00:00:00', 3, 4 ),( '猪八戒', '2013-01-10 00:00:00', 10, 2 ),( '猪八戒', '2013-02-01 00:00:00', 2, 2 ),( '猪八戒', '2013-02-05 00:00:00', 12, 2 ),( '猪八戒', '2013-02-06 00:00:00', 1, 2 ),( '猪八戒', '2013-02-07 00:00:00', 17, 2 ),( '猪八戒', '2013-02-11 00:00:00', 5, 2 ),( '猪八戒', '2013-02-12 00:00:00', 10, 2 );
- 2017-04-15 3回答·1269浏览
-
 慕粉18129907432
慕粉18129907432
- join优化聚合函数
不行,两次JOIN你可以假象成两张不同的表,但是结构和数据都一样,第二张表求最大值行,以最大值的行筛选出第一次JOIN的表数据,第一次JOIN的表数据和主查询的表构成最终的查询数据
- 2017-03-01 1回答·1676浏览
-
 小飞鑫哥
小飞鑫哥
- 关于数据库中时间的查询
- 已采纳 骑车去拉萨 的回答
CURRENT_TIMESTAMP 这个值
- 2017-01-21 3回答·1853浏览
-
 qq_萝卜_22
qq_萝卜_22
- 视频中的group by是不是不用也可以分组,因为已经使用了b.use_id=a.user_id这个条件,最后在添加一个order by a.user_name,kills;就行?
where 的作用是条件查询 ,group by 是分组查询,他们的作用不一样,只有where 查询结果不会分类显示,可能是杂乱无序
- 2016-12-24 1回答·1638浏览
-
 深山里的小铁匠
深山里的小铁匠
- 怎么快速复制前面写的几行代码
- 已采纳 simpleTravel 的回答
键盘中的方向键 按上下选择
- 2016-10-29 1回答·1853浏览
-
 哈你
哈你
- 本节sql优化,及详细讲解
我们紧接上楼,内部优化完毕的sql是这样的
SELECT d.user_name, c.timestr, kills FROM
(SELECT a.user_id, a.timestr, a.kills, COUNT(b.kills) cnt FROM kills AS a
JOIN kills b ON a.user_id = b.user_id
WHERE a.kills <= b.kills
GROUP BY a.user_id, a.timestr, a.kills) AS c
JOIN workteam d ON d.work_id = c.user_id WHERE cnt <=2;
由于 where 从句中的条件和 下面的这个子查询相关联,每进行一个次外围查询就要执行一次子查询,效率不言自明。
SELECT a.user_id, a.timestr, a.kills, COUNT(b.kills) cnt FROM kills AS a
JOIN kills b ON a.user_id = b.user_id
WHERE a.kills <= b.kills
GROUP BY a.user_id, a.timestr, a.kills
我们继续优化。
思路是这样的,JOIN两次 kills 表即可, 第一次关联是为了 查找信息, timestr 和 kills。
第二次关联是为了 使用 count() 函数统计 比 当前行 kills 大的 数量,供having 语句使用(
吐槽的各位看官,看到这里是不是发现和上节课老师所讲的求每个人哪天打怪的数目最多的
思路如出一辙啊)。下面给出sql
SELECT c.user_name, a.timestr, a.kills FROM workteam c
JOIN kills a ON c.work_id = a.user_id
JOIN kills b ON a.user_id = b.user_id
WHERE a.kills <= b.kills
GROUP BY user_name, kills DESC, timestr
HAVING COUNT(b.kills) <= 2
细心的看管,已经发现我这里的表名称, 表字段和老师演示的例子不尽相同。
kills 表对应 user_kills , workteam 对应 users1,
work_id 字段对应 id
- 2016-10-16 3回答·1303浏览
-
 张吃吃
张吃吃
- 这两个表名a,b到底指什么啊,还有我真的不明白这里为什么要分组 什么情况下分组好一点
- 已采纳 BaBy13 的回答
不同表比较一般也会起别名,为了书写区分简单,这里取不同的别名是因为在使用嵌套子查询,里外的表结果是不一样的,相同别名会报错
比如查询不同类目下的前几个商品的信息就需要分组了,我觉得分组主要是为了提高查询的效率。
感觉不太容易说清楚,不过如果你一次性听不明白,我觉得可以把几次查询先分开查一下,看看出的结果是什么,然后再组合到一起看一下就好了。
个人意见,希望对你有帮助
- 2016-07-21 2回答·1906浏览
-
 致远163
致远163
- 字段没有说明属于哪个表,有语法错误吗
如果两张表中存在相同的字段名时,如果不指定是某一张表的字段名,将会报语法错
- 2016-06-10 1回答·906浏览
-
 joyoes
joyoes
- 关于两表统计数分组的SQL语句
- 已采纳 SevenKey 的回答
SELECT `a表`.`name` AS 村社,COUNT(`a表`.id) AS 统计结果 FROM a表 LEFT JOIN `b表` ON `a表`.card=`b表`.card WHERE GROUP BY `a表`.`name`
- 2016-03-24 3回答·2117浏览
-
 qq_敲着键盘看风景_0
qq_敲着键盘看风景_0
- 有没有课件PPT下载
- 2015-07-26 2回答·914浏览
-
 鹏飞天下
鹏飞天下
- 每个人打怪最多的两天
这里确实可以不用分组。
- 2015-06-30 4回答·1257浏览

















