-

- qq_百香果_0 2023-10-18
新建一个 Scala 类
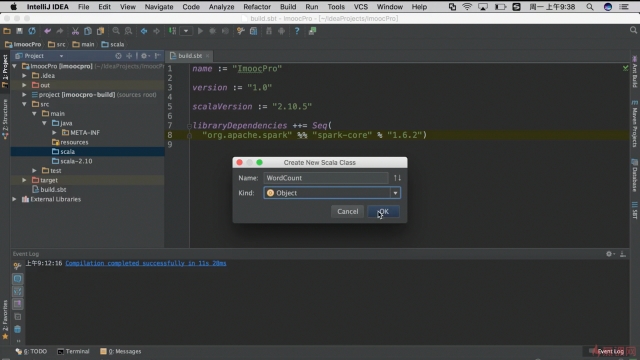
- 0赞 · 0采集
-

- 熊手拉猫手 2023-03-21
演示了 ssh 不需要输密码的修改
执行 ssh-keygen (一路回车)
执行 cd .ssh 看到几个文件,其中 .pub 为公钥
创建文件 authorized_keys 文件
执行 cat 文件 > 文件 (把那个 .pub 导入 authorized_keys )
chmod 600 authorized_keys
验收:再执行 ssh localhost 看到启动后不需要输入密码
---------------------------------------------------------------
给集群提交作业,也是把作业(工程)打包成 jar 然后上传到服务路径
./bin/spark-submit .... xx.jar (工程)
- 0赞 · 0采集
-

- zrey 2022-03-23
Wordcount
//Scala Object WordCount{ def main(args: Array[String]){ val conf= new SparkConf().setAppName("wordcount") val sc = new SparkContext(conf) val input= sc.textFile("/home/soft/hello.txt") //RDD操作:压扁 val lines = input.flatMap(line=> line.split(" ")) //转换成kv对 val count= lines.map(word=>(word,1)).reduceByKey{case (x,y)=>x+y} val output= count.saveAsTextFile("/home/result") } }Project Structure -> Artifacts ->+然后 BuildArtifacts 打包Jar
启动集群:
启动master start-master.sh
启动worker spark-class
提交作业 spark-submit
#启动worker spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:4040 #提交 spark-submit --master spark://localhost.localdomain:4040 --class WordCount /home/soft/hello.jar #上传jar包 rz -be
- 0赞 · 0采集
-

- 慕粉1446071354 2020-05-24






WordCount程序开发
- 0赞 · 0采集
-

- 慕的地1117626 2019-11-03
使用standalone mode启动spark:命令行输入
$ cd software/spark-2.4.4-bin-hadoop2.7/sbin $ ./start-master.sh 会输出log文件地址xxx $ tail xxx 会输出log文件末尾,找到Starting Spark master at spark://xxx.local:7077, 也可以浏览器访问http://localhost:8080/,出现视频中的网页
参考https://uohzoaix.github.io/studies//2014/09/13/sparkRunning/
-
截图0赞 · 0采集
-

- xyx8888 2019-08-10
开发Spark程序
-
截图0赞 · 0采集
-

- gongwanyi 2019-08-04
具体命令:
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
启动集群相关步骤
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
然后出现如下截图
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
Build项目
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
点击OK后出现这个效果
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
然后重新配置
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
如果报错,原因是之前已经存在相关文件,只需要把相关文件删除即可
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
配置Jar包过程3
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
配置Jar包过程2
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
配置jar包过程
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
打包过程:
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
WordCount程序
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
新建一个Scala class,命名为WordCount,Kind为Object
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
配置build.sbt相关环境依赖
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
WordCount
-
截图0赞 · 0采集
-
- gongwanyi 2019-08-04
配置ssh无密码登录
-
截图0赞 · 0采集
-

- lowenest 2019-07-15
spark 启动 master worker 、
-
截图0赞 · 0采集
-

- 凡简 2018-11-27
配置ssh免密登录
-
截图0赞 · 0采集
-

- 慕婉清5038615 2018-10-19
可以看到spark集群上的wordcount程序在跑,是4040端口,jobs。
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-19
用 rz -be命令可以上传一个本地文件
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-19
详细的集群启动操作,相关的参数
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-19
开发完spark程序后,启动集群:
启动master ./sbin/start-master.sh
启动worker ./bin/spark-class
提交作业 ./bin/spark-submit
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-19
如何添加jar包,有两种选择方式
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-19
开发第一个spark程序: wordcount
设置应用名,val conf=new sparkconf()。setappname(“”)
设置上下文根,val sc =new sparkcontext(conf)
加载文件,val input=sc。textfile(“”)
通过分隔符获取数据行(压扁操作),val lines = input。flatmap(line=》line。split(“”))
获取单词个数count,转换成map对象,val count= lines。map(word=》(word,1))。reducebykey{case (x,y)=》x+y}
输出结果,val output=count。saveastextfile(“”)
-
截图0赞 · 0采集









