-

- 崔华乐 2024-04-23
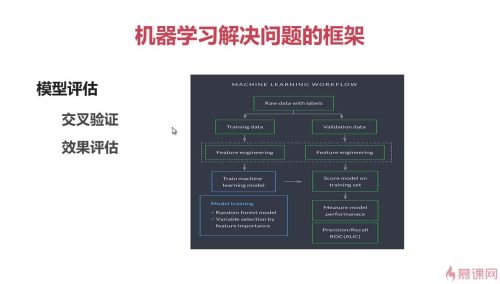
一、机器学习解决问题的框架
训练模型
定义模型
定义损失函数
优化算法
模型评估
交叉验证
多个算法分别带入同一类数据,验证效果
效果评估
评估多个算法间的差异
- 0赞 · 0采集
-

- 慕少7339756 2023-07-31

1
- 0赞 · 0采集
-
- 慕少7339756 2023-07-31

来自网络:损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
解析解: 精确的解。
近似解:使得损失函数/偏差函数 比较小的解。
- 0赞 · 0采集
-

- 即白CV 2023-03-18

1
- 0赞 · 0采集
-

- _Clouds 2021-10-27
机器学习大致框架-思路


- 0赞 · 0采集
-

- 大白小白i 2021-08-28
6-2机器学习解决问题(2)
训练模型
定义模型
定义损失函数 找偏差最小的一个函数 针对很大的数据集来说
优化算法 出发点就是为了让损失函数取最小
模型评估
交叉验证 将不同的算法带入同一类数据中,验证效果
效果评估 根据标准可以看出几个算法之间具体的差别、效果
- 0赞 · 0采集
-

- weixin_慕姐6432486 2020-02-23
损失函数与优化算法是重点,难度比较大
- 0赞 · 0采集
-

- 要做就做周幽王 2019-10-15
机器学习解决问题的框架:
训练模型:定义模型、定义损失函数、优化算法、模型评估、效果评估
- 0赞 · 0采集
-

- 霜花似雪 2019-10-11
机器学习解决问题的框架:
二、训练模型
STEP1:定义模型(形成目标公式)
STEP2:定义损失函数(数学的方式定义预测值与现实值的差异)
STEP3:优化算法(寻找确定损失函数极小值)
三、模型评估(标准)
STEP1:交叉验证
STEP2:效果评估
训练模型
(1)定义模型:确定模型,训练出模型的参数
(2)定义损失函数(定义偏差的大小):评价真实结果与模型的预测结果的相似程度和差异度。 机器学习解决的问题,有时不能得到精确解只能寻找近似解。 偏差最小的函数,针对很大的数据集,就是损失函数。 让损失函数求最小,就是优化算法。对于线性回归模型,计算预测结果与实际结果的差值;对于分类模型,则需要定义自己的损失函数
(3)优化算法:对算法进行优化,使损失函数取极小值,如梯度下降法......
-
截图0赞 · 2采集
-

- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;
2 【聚类】-用户细分精准营销;
3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);
4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;
5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;
6【更多应用】
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接告诉你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;
2 【聚类】-用户细分精准营销;
3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);
4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;
5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;
6【更多应用】
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;
2 【聚类】-用户细分精准营销;
3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);
4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;
5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;
6【更多应用】
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;
2 【聚类】-用户细分精准营销;
3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);
4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;
5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;
6【更多应用】
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;2 【聚类】-用户细分精准营销;3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;6更多应用
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;2 【聚类】-用户细分精准营销;3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;6更多应用
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-
- 灿若星辰7587352 2019-08-18
课程小结:
Q:什么是机器学习?
A:计算机在历史数据中去寻找规律,然后在未来不确定中做决策。
Q:机器学习的典型行业案例?
A:1【关联规则】-购物篮分析 ;2 【聚类】-用户细分精准营销;3【朴素贝叶斯和决策树】-垃圾邮箱、行用卡诈骗(银行信用贷款风险识别);4【ctr预估和协同过滤】ctr预估-互联网广告的点击预估、协同过滤-类似购物篮分析;5【自然语言处理和图像识别】情感识别、实体识别、图像深度学习;6更多应用
Q:机器学习和传统数据分析的区别?
A:机器学习(行为数据—海量数据—全量分析—预测未来发生的事—数据挖掘:数据驱动自我进行知识发现—用户目标:个体如个性推荐)
数据分析(交易数据—少量数据—采样分析—报告过去的事情—OLAP-数据分析:用户驱动—用户目标:公司高层决策)
Q:机器学习的经典算法
A:1有监督学习、无监督学习、半监督学习
2 分类回归、聚类、标注
3 生成模型和判别模型(训练模型思维上不一样)
生成模型:不会告诉你数据属于哪一类,只会告诉你数据属于各个类别的概率,结果模棱两可,就像陪审团
判别模型:直接高数你属于哪一类,结果非1即2,就像法官说你有罪/无罪
【FP-Ggrowth】
【罗辑回归】百度、谷歌的搜索推荐排序
【RF、GBDT】对决策树算法的改进
【推荐算法】各大电商的标配,关联推荐法则
【LDA】【Word2Vector】【HMM \ CRF】三者都是对自然语言文本的处理算法
【深度学习】图像识别
- 0赞 · 0采集
-

- 地铁跳水 2019-08-01
- 6.2机器学习解决问题的框架二
-
截图0赞 · 0采集
-

- qq_黄蓉_0 2019-06-13
机器学习解决问题的框架:
 寻找近似解
寻找近似解
- 0赞 · 0采集
-

- 曹文 2019-06-08
- 模型,定义模型就是求一个公式,比如y=ax+b
-
截图0赞 · 0采集
-

- 孤雁西风 2019-05-11
训练模型!
-
截图0赞 · 0采集
-
- 孤雁西风 2019-05-11
机器学习flow
-
截图0赞 · 1采集
-

- 楠shen 2019-04-25
机器学习解决问题的框架:
二、训练模型
STEP1:定义模型(形成目标公式)
STEP2:定义损失函数(数学的方式定义预测值与现实值的差异)
STEP3:优化算法(寻找确定损失函数极小值)
三、模型评估(标准)
STEP1:交叉验证
STEP2:效果评估
- 0赞 · 2采集
-

- 慕运维4169585 2019-03-20
训练模型:
-
截图0赞 · 0采集
-

- 慕尼黑9823340 2019-03-02
*定义损失函数
*优化算法
- 0赞 · 0采集
-

- 慕设计8338630 2019-01-30
机器学习解决问题的框架:
二、训练模型
STEP1:定义模型(形成目标公式)
STEP2:定义损失函数(数学的方式定义预测值与现实值的差异)
STEP3:优化算法(寻找确定损失函数极小值)
三、模型评估(标准)
STEP1:交叉验证
STEP2:效果评估
- 0赞 · 0采集
-

- 滕玉龙 2018-12-10
机器学习解决问题的框架2:
训练模型
(1)定义模型:确定模型,训练出模型的参数
(2)定义损失函数(定义偏差的大小):评价真实结果与模型的预测结果的相似程度和差异度。 机器学习解决的问题,有时不能得到精确解只能寻找近似解。 偏差最小的函数,针对很大的数据集,就是损失函数。 让损失函数求最小,就是优化算法。对于线性回归模型,计算预测结果与实际结果的差值;对于分类模型,则需要定义自己的损失函数
(3)优化算法:对算法进行优化,使损失函数取极小值,如梯度下降法......
- 0赞 · 0采集
-
- 滕玉龙 2018-12-10
监督式学习:分类,回归 非监督式学习:聚类 标注 逻辑回归与朴素贝叶斯本质区别:生成模型与判别模型的区别 生成模型->估计的是联合概率分布 判别模型->估计的是条件概率分布 监督式学习:分类,回归 分类 C4.5 聚类 K-Means 统计学习SVM 关联分析fp-growth RF 深度学习 业务需求->数据->特征工程 定义模型->定义损失函数->优化算法->交叉验证
- 0赞 · 0采集
-

- 慕婉清5038615 2018-11-26
机器学习解决问题框架
模型评估
交叉验证
效果评估
其中训练模型中的损失函数定义和优化算法是最为困难的。
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-11-26
机器学习解决问题框架
训练模型
定义模型
定义损失函数
优化算法
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-11-26
机器学习解决问题框架三步走:
1确定目标
业务需求
数据
特征工程
-
截图0赞 · 0采集





















