-

- 一不不 2025-03-03
流式VS非流式对比介绍
非流式输入的问题:
当你从OpenAI请求一个完成内容时,如果你在生成长的完成内容,等待响应可能需要几秒钟的时间。影响用户体验。流式:
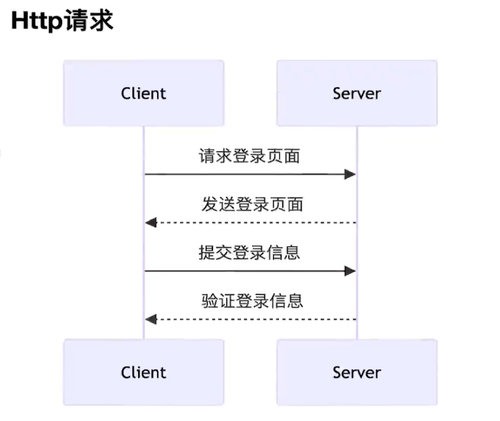
http请求:一问一答模式
SSE
服务其发送事件(Server-sent events ,简称SSE),服务器向客户端推送数据,客户端通过事件监听器接收数据。
严格地说,Http协议无法做到服务器主动推送信息,但是,有一种变通方法,就是服务器向客户端声明,接下来要发送的是流信息(streaming)。
也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。本质上,这种通信就是以流信息的方式,完成一次用时很长的下载。
向OpenAI请求流式输出
1、要流式传输完成内容,请在调用聊天完成或完成端点时设置stream=True.
2、使用openai-python库解析OpenAI流式请求的缺点:
1、内容审查问题。请注意,在生产应用程序中使用stream=True会使内容的审核变得更加困难,因为部分完成内容可能更难评估。
向C端用户提供服务的时候,需要注意内容审查问题。
2、无usage字段。流式响应的另一个小缺点是响应不在包括usage字段,告诉你消耗了多少令牌。在接收和组合所有响应后,你可以使用tiktoken自己计算这一点总结:
简单来说:这种流式传输方式使得客户端在长内容生成过程中无需等待整个内容完成,就可以逐步接受到生成的内容,从而提高了响应速度和用户体验。- 0赞 · 0采集
-

- 程序小工 2024-09-01
流式输出的场景:
需要大模型执行一段时间的情况,避免用户等待,可以一点一点的输出
非流式:

使用的是http请求,不能主动向客户端推送数据
流式:----SSE:服务器发送事件


响应结构:



非流式响应结构:


object的结构差异:
非流式=chat.completion
流式=chat.completion.chunk
choices的结构差异:
非流式=index、message.role、message.content、logprobs、finish_reason
流式=index、delta.role、delta.content、finish_reason
usage差异:
非流式=prompt_tokens、completion_tokens、total_tokens
流式=没有该参数


逐行读取流式返回结果:

bit类型=>字符串: line.decode('utf-8').lstrip('data: ')
字符串=>字典(json) : json.loads()
print使用知识点:
默认输出后会带换行符,如果不需要换行,需要执行换行符类型
print(str, end=''): 不换行直接输出
openai-python库: 使用支持SSE协议的已有客户端库,简化实现逻辑

处理返回结果



- 0赞 · 1采集
-

- shineLover 2024-08-28
不输出换行符:print("输出", end='')
使用openai-python库
流式输出时,可设置滑动窗口实现内容审查
使用tiktoken库计算token消耗
- 0赞 · 0采集


