-

- XZC6188253 2024-04-08



111111111111111111111111111111111111111111111111111111111111111
- 0赞 · 0采集
-

- 慕姐3353973 2024-03-29
P(Y|X)条件概率。
H(Y|X)条件熵:计算公式。
信息增益:熵和条件熵的差,g(D,A),特征A对数据集D的信息增益。
g(D,A)=H(D)-H(D|A)。
- 0赞 · 0采集
-
- 慕姐3353973 2024-03-29
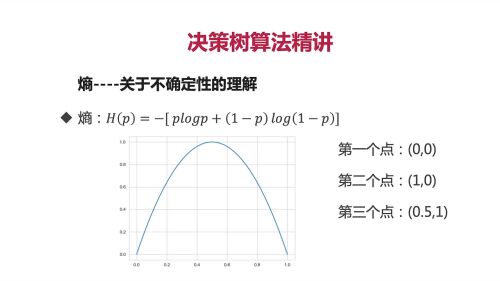
熵:随机变量的不确定性。
决策树构建、剪枝。
熵的计算公式。
熵越大,变量的不确定性就越大。
- 0赞 · 0采集
-

- 慕九州9087631 2022-02-09
泛化性能较差的意思是在测试集上表现较好,在其它数据集上可能表现的较差
- 0赞 · 0采集
-

- qq_petersonjoe_0 2020-10-22
- 无监督算法—数据不包含标签 有监督算法—数据包含标签
-
截图0赞 · 0采集
-

- O_O01234 2020-09-08
k-means 算法精讲
-
截图1赞 · 0采集





数据加载中...