-

- qq_无名_113 2024-11-12

步骤
- 0赞 · 0采集
-
- qq_无名_113 2024-11-12
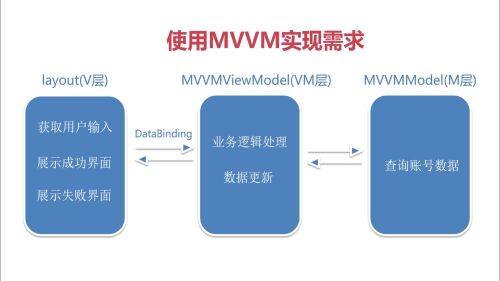
mvvm
- 0赞 · 0采集
-
- qq_无名_113 2024-11-12

备注:
- 0赞 · 0采集
-
- qq_无名_113 2024-11-12
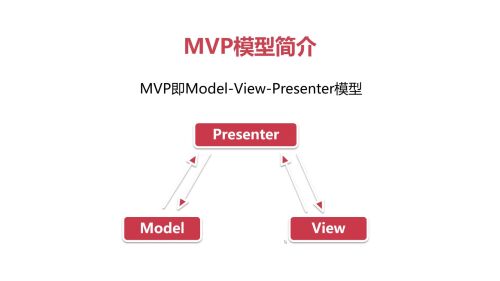
Mvp
- 0赞 · 0采集
-
- qq_无名_113 2024-11-12
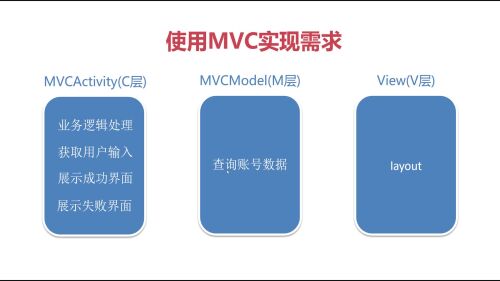
M层负责从数据库中获取数据
- 0赞 · 0采集
-
- qq_无名_113 2024-11-12
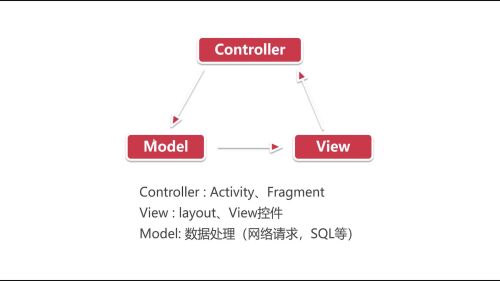
mvc 形式 Controller 持有Model 先Model 传递数据,而Model向View传递数据 一般使用Callback的形式
- 0赞 · 0采集
-

- 梦里花99 2024-01-05

根据项目来选择,学会变通,简单的页面可以不使用框架或使用MVC,建议多使用插件或自定义插件,减少重复代码
- 0赞 · 0采集
-
- 梦里花99 2024-01-05

学好 DataBinding、LiveData
- 0赞 · 0采集
-
- 梦里花99 2024-01-05

1、
2、
3、
在布局文件中声明
在Activity中初始化
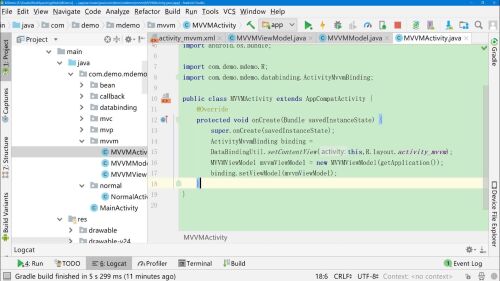
在布局文件中使用
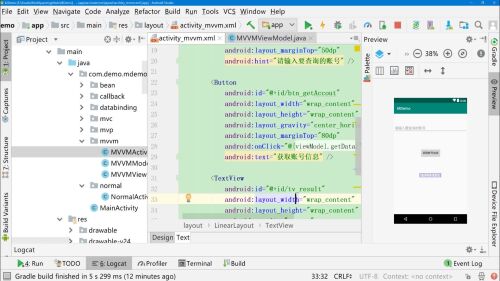
ViewModel中实现getData方法
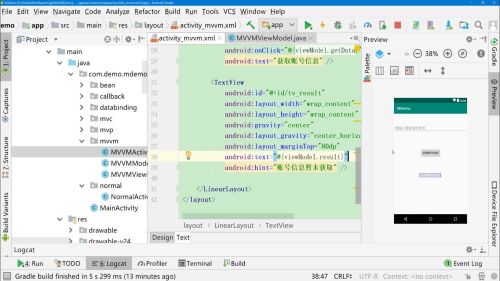
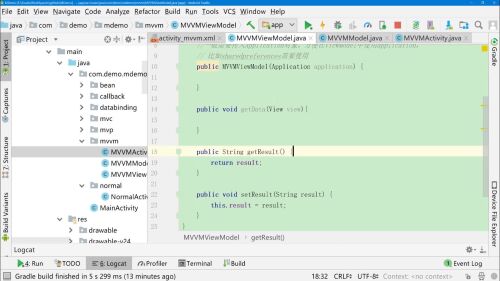
3、
再创建一个构造器,将Binding对象传值过来,可以调用输入的内容
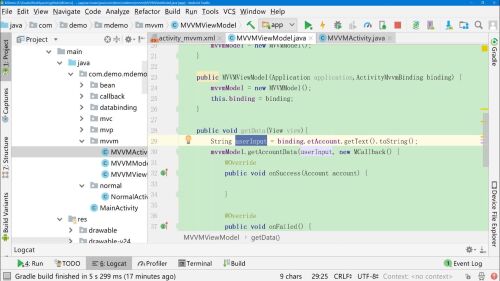
在viewModel中直接使用dataBinding来操作,这样不是很好
改进:
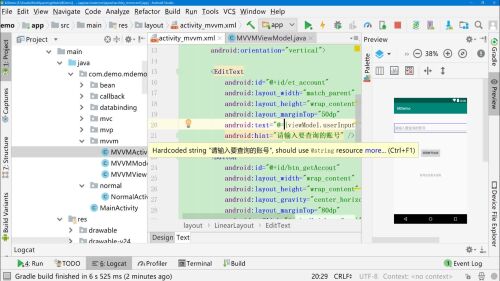
1、将输入框与viewModel.userInput绑定,并且实现双向绑定,
android:text="@={viewModel.userInput}"
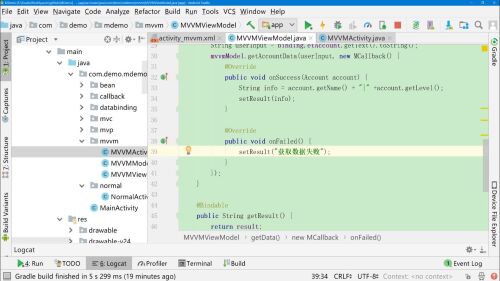
2在viewModel中提供userInput变量
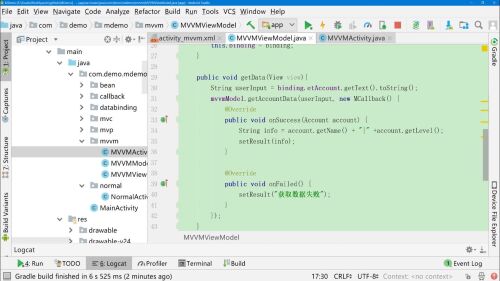
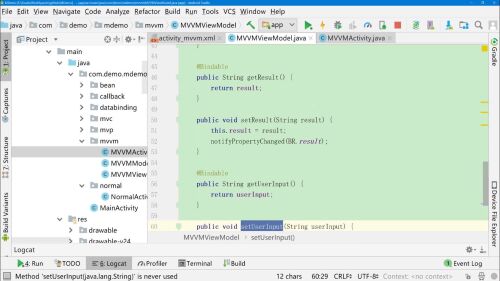
所以在使用的时候,不需要使用dataBinding获取userInput,直接使用userInput变量
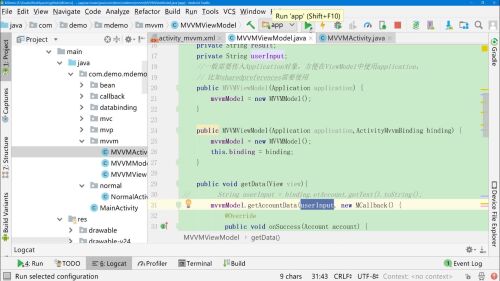
有时候,有些操作需要在Activity中完成,实现方式很多
1、借助三方库,EventBus/RxBus,但不够好
2、建议使用LiveData+ViewModel的形式

- 0赞 · 0采集
-
- 梦里花99 2024-01-05


1、启动DataBinding
在App下的build.gradle的android层级下,添加
dataBinding{ enabled = true }2、修改布局文件为DataBinding布局
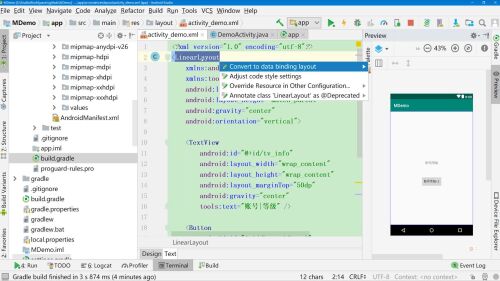
选中最外层的布局控件,同时按下Alt+回车,选择Convert to data binding layout
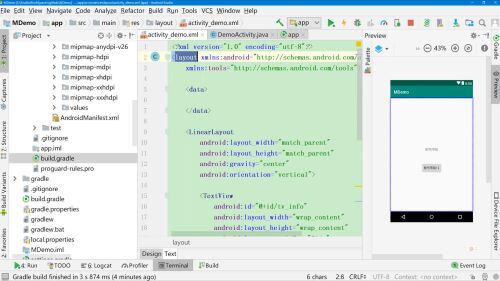
原来的Activity
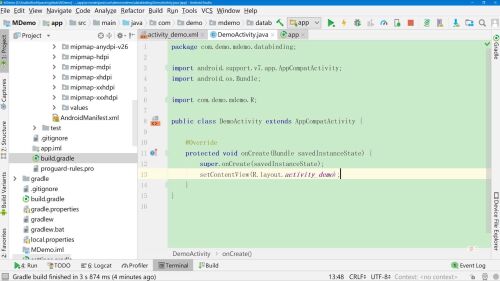
可以修改为
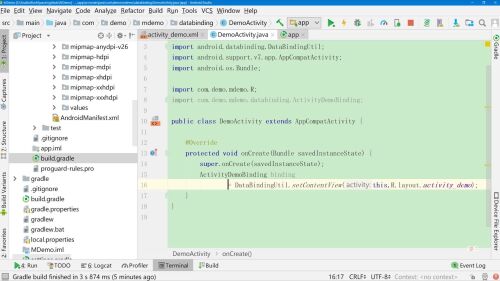
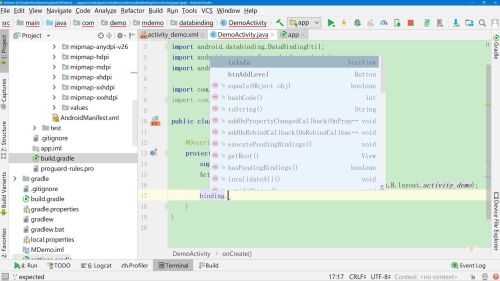
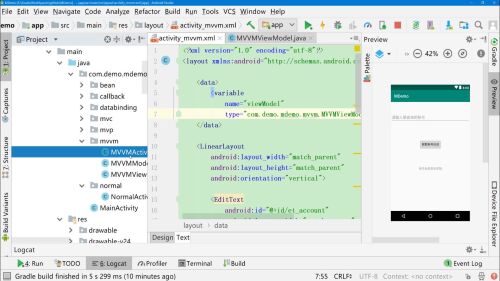
在布局文件中的layout-data下声明变量
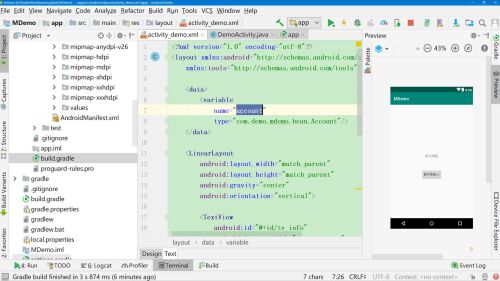
在相应位置使用,还可以在其中使用拼接,注:在大括号中还包含字符串的话 需要使用单引号
android:tex="@{account.name}"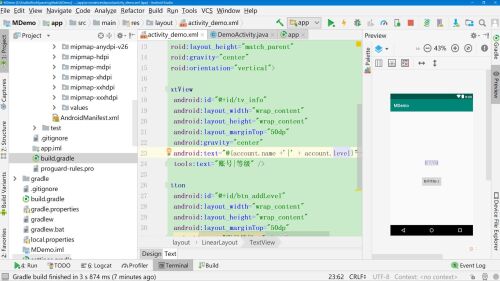
对account进行初始化
拓展:
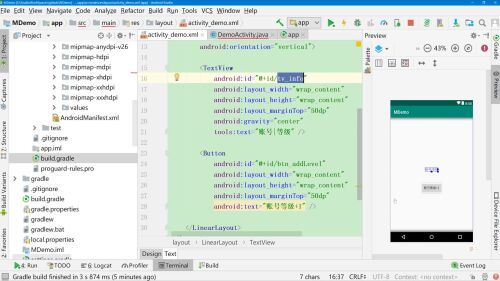
点击按钮为level+1
1、声明activity变量
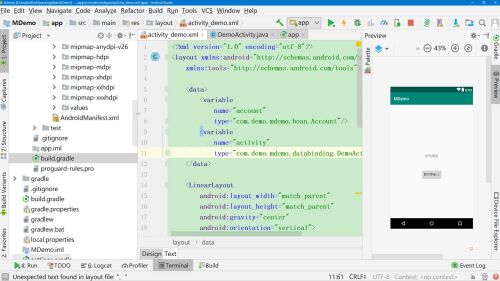
2、按钮中添加点击事件,引用activity的onClick事件
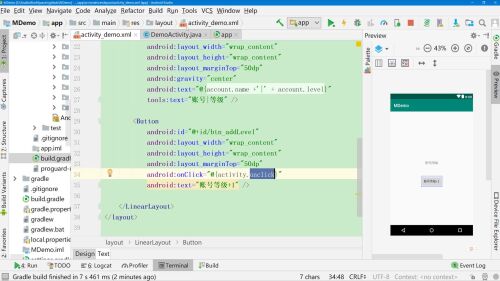
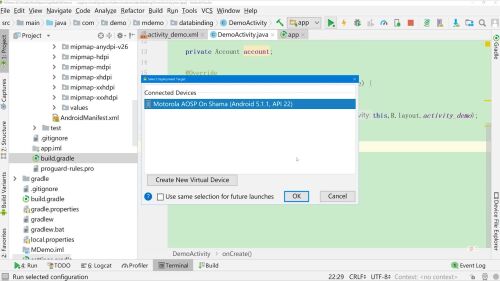
3、Activity中设置activity
dataBinding.setActivity(this);
4、实现onClick方法
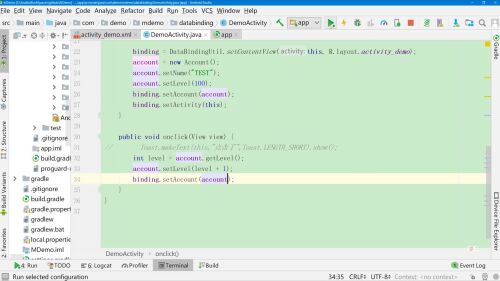
优化:
每次点击都会调用setLevel
在Bean中 extends BaseObservable
对getLevel()添加@Bindable注解
在setLevel()方法中添加刷新,BR类似R,是DataBinding为我们自动生成的
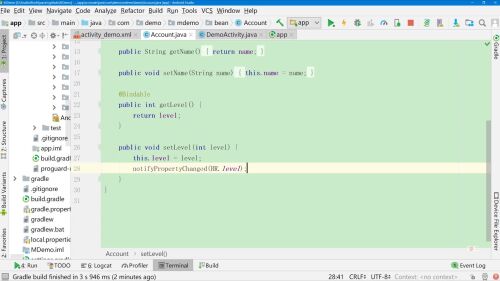
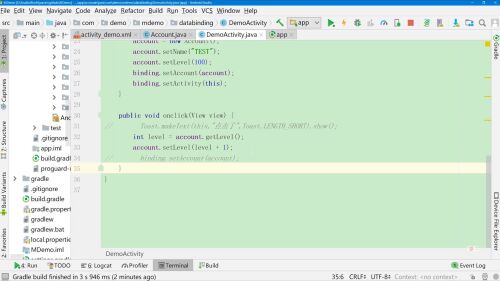
以上为单向绑定
双向绑定:
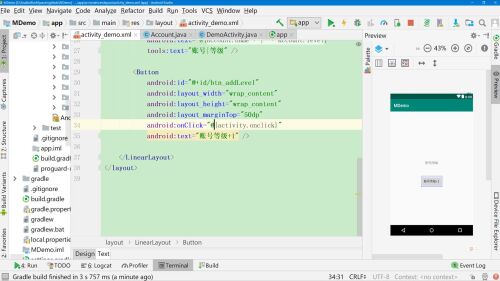
在视图中,@后增加=,表示双向绑定,即视图更新也会更新数据,数据更新也会刷新视图
双向绑定一般用于输入框
- 0赞 · 0采集
-
- 梦里花99 2024-01-05
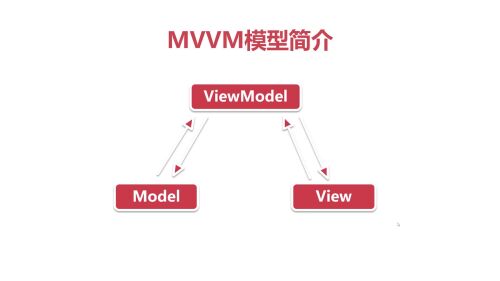
与MVP的思想相似,但代码更简洁

- 0赞 · 0采集
-
- 梦里花99 2024-01-03
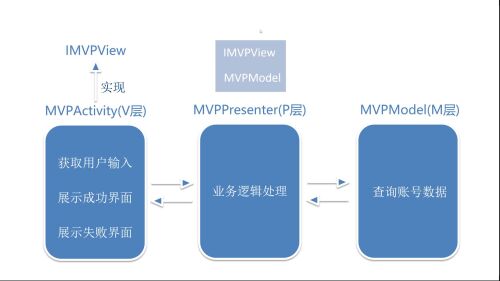

1、
创建一个interface IMVPModel 里面创建三个方法,分别是获取数据、数据获取成功、数据获取失败
MVPAvtivity implements IMVPModel,并实现这三个方法,完成其中的逻辑处理
2、
创建MVPModel
他需要获取接口中的数据
3、
创建一个MVPPresenter,持有view层和Model层的引用
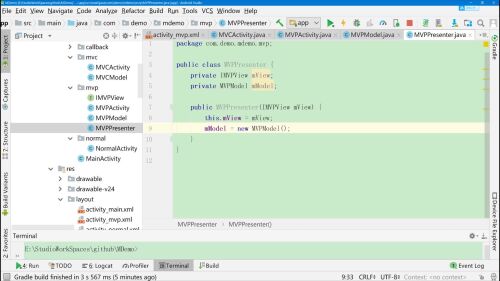
4、MVPActivity中创建一个presenter的实例
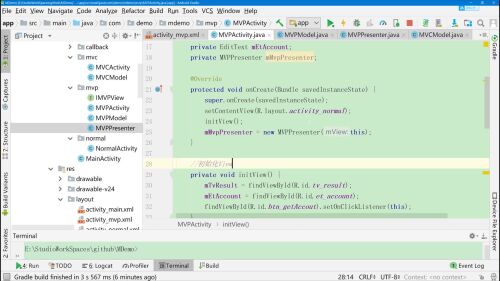
prenster中实现一个获取数据的方法getData(),在实际操作时,Activity中presenter.getData()
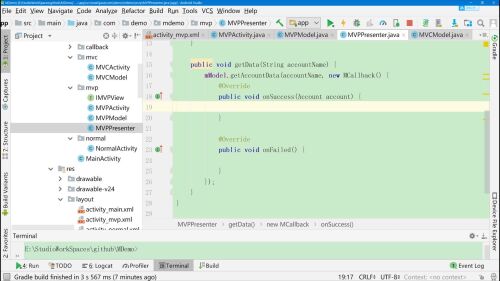
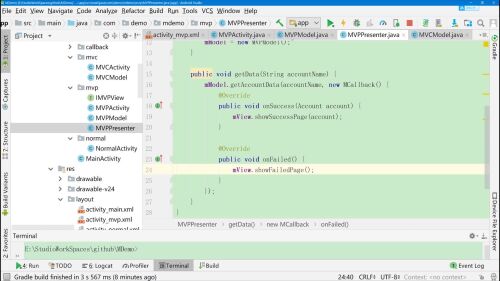
- 0赞 · 0采集
-
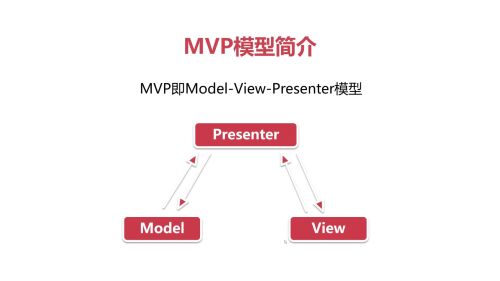
- 梦里花99 2024-01-03
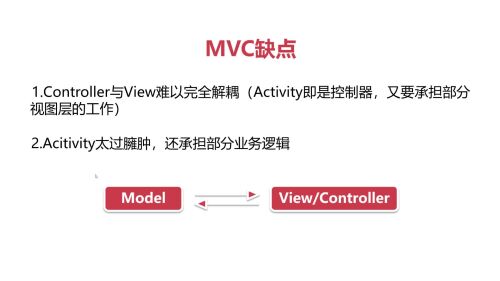
在MVP中,这种情况得到了很好的解决

- 0赞 · 0采集
-
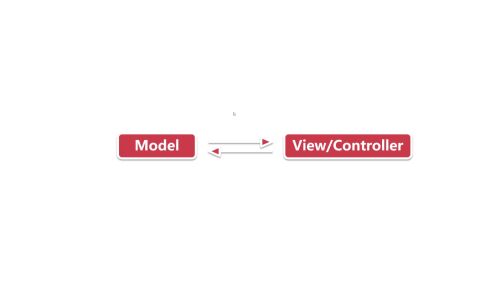
- 梦里花99 2024-01-03

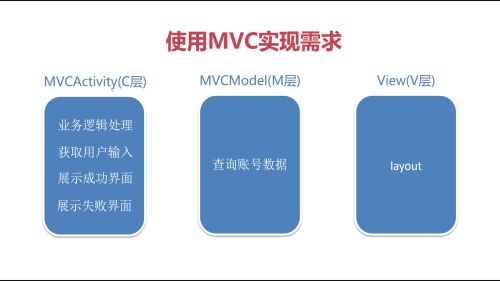
所以也可以将View和Controller混合放在一起,形成下图的情况
- 0赞 · 0采集
-
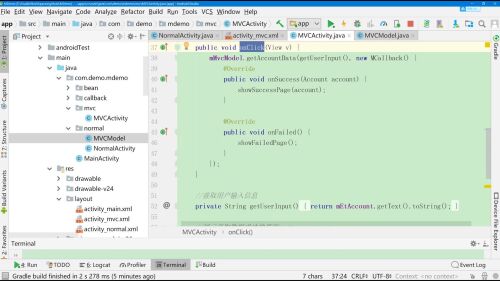
- 梦里花99 2024-01-03
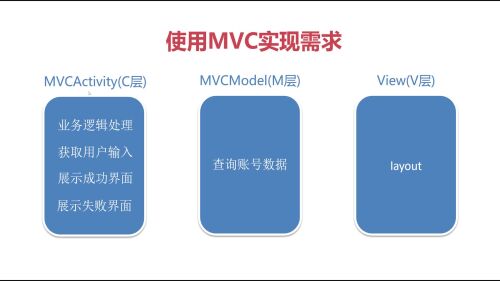

解决第二点,是可以在Activity中创建一个Model的实例,拿着实例去调用接口方法,然后再去分别实现不同情况下的处理通知页面更新操作的方法。
- 0赞 · 0采集
-
- 梦里花99 2024-01-03

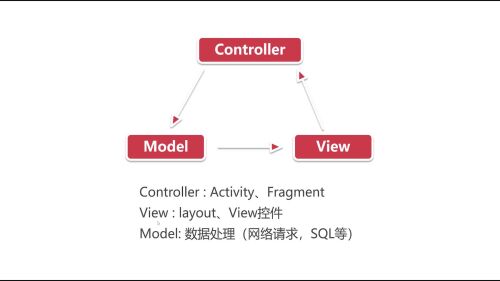
箭头表示的是事件的传递方向

- 0赞 · 0采集
-
- 梦里花99 2024-01-03

最终失效效果:
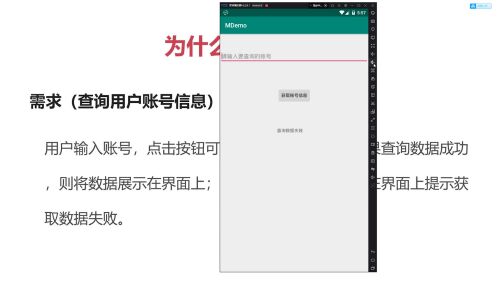
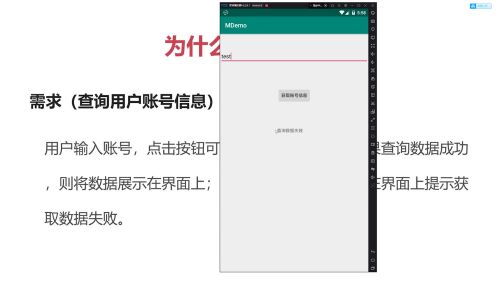
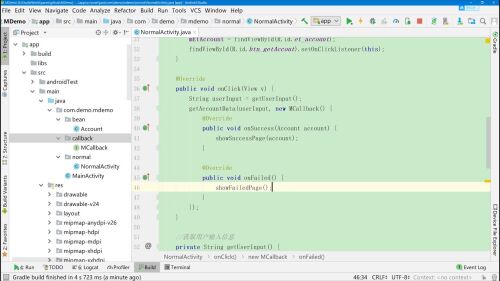
具体实现部分截图
使用此种方式,将所有内容都放在了NormalActivity.java页面中,承载了页面展示、逻辑处理、接口调用等
项目越来越大,越复杂的话,会越来越多。
使用MVC模式优化,下节继续、
- 0赞 · 0采集
-
- 梦里花99 2024-01-03
在应用和面试中经常被问到。
- 0赞 · 0采集
-

- 日就月将 2022-09-18
【MVVM优缺点】
-优点 :
实现了数据和视图的双向绑定,极大的简化代码
1.减少了接口数量 2.告别繁琐findViewById操作
-缺点 :
bug难以调试,并且dataBinding目前存在一些编译问题
【建议】建议DataBinding和LiveData结合使用
-DataBinding是实现MVVM模式数据绑定的工具;
-LiveData是解决MVVM之间的通信问题,且可感知组件的生命周期,可有效避免内存泄漏。- 0赞 · 0采集
-
- 日就月将 2022-09-18
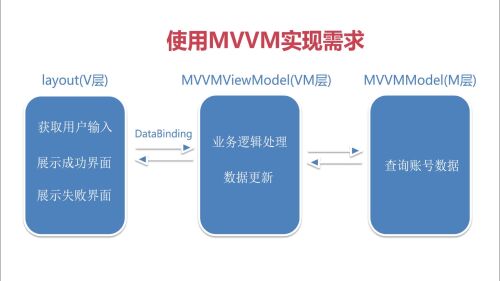
使用MVVM实现需求步骤:
1. 提供View,ViewModel以及Model三层
2. 将布局修改为DataBinding布局
3. View与ViewModel之间通过DataBinding进行通信
4. 获取数据并展示在界面上

- 0赞 · 0采集
-
- 日就月将 2022-09-18
使用MVM实现需求

- 0赞 · 0采集
-
- 日就月将 2022-09-18
双向绑定☞视图发生变化,一般是EditView,在@后面加上 = 号即可。
- 0赞 · 0采集
-
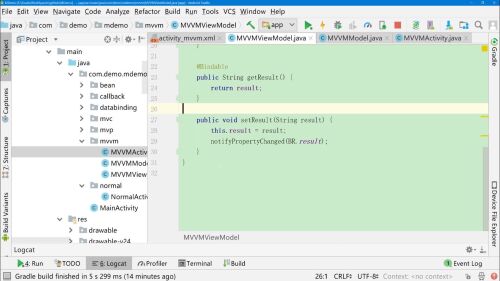
- 日就月将 2022-09-18
对象Bean继承 android.databinding.BaseObservable
设置@Bindable 注解,等级发生变化的时候自动更新
设置 notifyPropertyChanged(BR.level),当值发生变化是通知视图更新。
- 0赞 · 0采集
-
- 日就月将 2022-09-18
DataBinding使用三步骤?
1启用 DataBinding
在app的buid.gradle 中 android{}下 添加如下代码
dataBinding{ enabled = true }2. 将传统布局文件,修改为支持 DataBinding
选中最外层布局文件—按住【ALT+ENTER】—选择 Convert on data binding layout 这个步骤后将会生成ActivityDemoBing (ActivityDemoBinding生成规则就是布局文件变成大写再拼接一个Binding就是其类名)
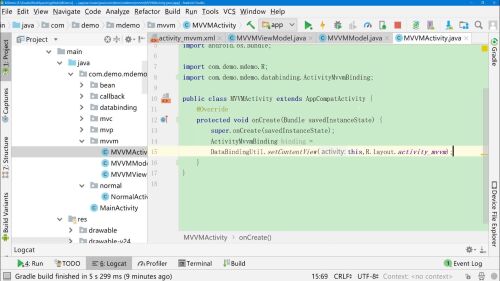
3. 数据绑定 @{}
1.修改Activity onCreate()中移除 setContentView() 而是 DataBingdingUtil.setContentView(Activity.this,R.layout.activity_demo) 然后将得到 ActivityDemoBinding binding实例。 现在可以直接通过binging.控件id,对控件进行操作了(告别了繁琐的findViewById) 2.来到布局文件中—可见到最外层为layout、layout下包含了<data/>节点以及传统布局文件; 在data节点中可声明对象 <data><variable name = "account" type="Account"/></data> 声明好后,在不居中可直接使用。如在TextView中 text= "@{account.name+'hello'+account.level}" //ps.如果在大括号中若需要拼接字符串,这里使用单引号 ''- 0赞 · 0采集
-
- 日就月将 2022-09-18
DataBinding是什么?
DataBinding是谷歌发布的一个实现数据绑定的框架(实现数据与视图双向绑定)它可以帮助我们在安卓中更好地实现MVVM模式。
- 0赞 · 0采集
-

- ciicjsb 2022-05-25
111111

- 0赞 · 0采集
-

- AppMan 2022-02-28
对框架的使用要灵活使用。
建议使用一些插件一键生成代码等。

- 0赞 · 0采集
-
- AppMan 2022-02-28
MVVM优缺点
要向用好MVVM要先把DataBinding和LiveData学好。

- 0赞 · 0采集
-
- AppMan 2022-02-28
LiveData + ViewModel

- 0赞 · 0采集
-
- AppMan 2022-02-28
View层:Activity和Layout布局视图文件。
Model:获取数据层。
View与ViewModel通过DataBinding进行通信。

使用MVVM需要实现以下步骤:

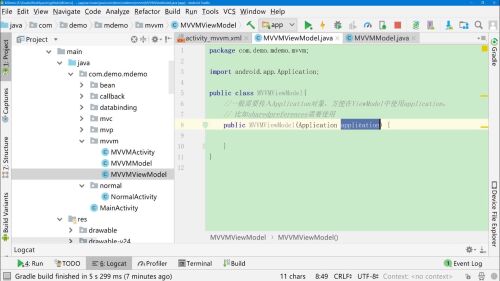
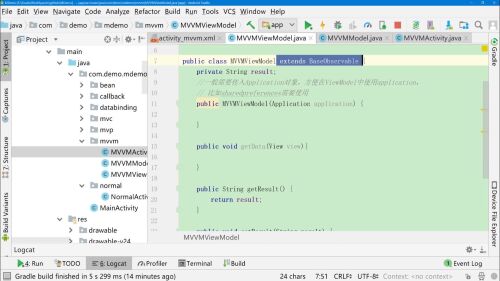
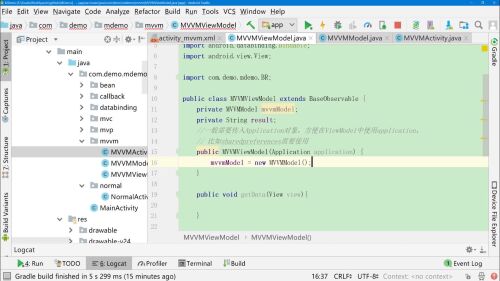
新建MVVMViewModel对象,继承BaseObservable。
持有MVVMModel数据对象。

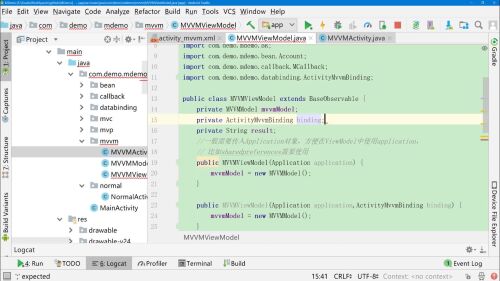
改进DataBinding,实现EditText双向绑定ViewModel里面的userInput字段(或对象)
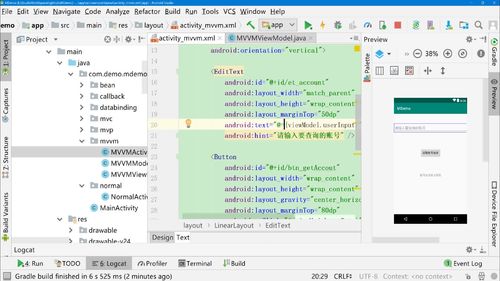
改进ViewModel,提供userInput字段,实现get和set方法并添加@Bindable注解和添加notifyPropertyChange(BR.userInput)方法。

- 0赞 · 0采集




