
二叉堆是一种典型的优先队列实现策略,广义而言,堆是优先队列的实现方式,在此之下又分为二叉堆,左式堆,斜堆,二项队列等具体形态。但第一个用得太普遍了,所以我们平时一说到堆(Heap)指的就是二叉堆。基本模型如下,基本操作就这两个,其他的都是扩展。

以后我们讨论的堆,如果不特殊说明,那都以小顶堆为例,堆顶元素为最小的值,但优先级上却是最高的。我们从二叉堆的起源谈起,如何根据之前已经掌握的数据结构来实现优先级队列,在这里,既要考虑效率还要兼顾成本,那最佳的实现方式应该是这两个因素的综合与兼顾,这就要求我们设计模型的时候发挥统筹兼顾、总揽全局的领导核心作用。
第一种实现方式是基于此前的向量或链表,这样的话,实现方便而且能保证某种情况下的效率。它可以在表头以O(1)O(1)的时间插入元素,如果要查询最小元素,那需要耗费θ(N)θ(N)时间。如果删除最小元素,不仅要遍历整个表来查到优先级最小的,而且需要在摘除之后将它的所有后继顺次前移,两项工作的成本累计Θ(n)+O(N)=θ(N)Θ(n)+O(N)=θ(N)。这就有点慢了,那另一种方法就是始终让表保持有序,构成有序向量,这往往会让算法性能有实质提高。这时候查找和删除最小元素只需要O(1)O(1)时间,如果要插入一个元素,我们要先找到他所在的位置,花费O(logN)O(logN),然后将它的所有后继元素后移一个单位留出空位,在最坏和平均情况都需要耗费O(N)O(N),所以总代价是O(N)O(N)。因此将向量有序化也不是一个行之有效的策略。
同样,借助链表也不能高效地实现优先级队列。
以上方法都各有缺陷,那或许我们会求诸之前学过的BBST,没错,无论是用AVL树、伸展树或者红黑树实现优先队列,三个标准接口(增、删、查)的效率都可以达到O(logN)O(logN),而且只需作一点优化,其中的getMin()getMin()接口效率还可以进一步提高到O(1)O(1)。但是就优先队列所要求的功能来说,BBST的功能就过于强大了。因为我们在优先队列里查找和删除都仅限于堆顶,而难以找到某个确切元素,并没有完全用上BBST的完整功能。也就是说,我们实际上是使用了一个非常高级的数据结构来实现一个功能更为简单的结构,而且BBST的开销也是比较大的,这简直杀鸡用牛刀。那有没有成本更低的实现方式呢?我们注意到对于优先队列而言,矛盾都集中在优先级最高的那个极值元素。这就意味着,我们只需要维护所有元素之间的一个偏序关系,就足以确定这个极值元素,而不必像BBST那样,始终都不折不扣地维护一个所有元素之间的全序关系。根据这一分析,我们确信一定存在某种形式上更简单,而且维护成本更低的实现方式。
总结一下:采用基本的向量结构不够,而采用更高级的树形结构,却有杀鸡用牛刀之嫌。我们要找一个中庸之道,为此我们需要以向量为形,以树形结构为神,形成二者之间的有机结合。就是逻辑上用树组织,但物理上用数组实现。为此,我们需要借助完全二叉树,可以认为是AVL树的一个特例,它的平衡因子处处非负,这也是二叉堆名字的来由。

和BST一样,堆也有两个性质:结构性和堆序性。如同AVL树一样,对堆的任何一次操作都有可能破坏这些性质,所以我们要时时维护这两个性质。下面来仔细分析一下这两个性质究竟为何物。
结构性质
堆是一颗被完全填满的二叉树,底层可能有空缺,但至少要保证从左到右填充,这样的树被称为完全二叉树(complete binary tree)。比如这样
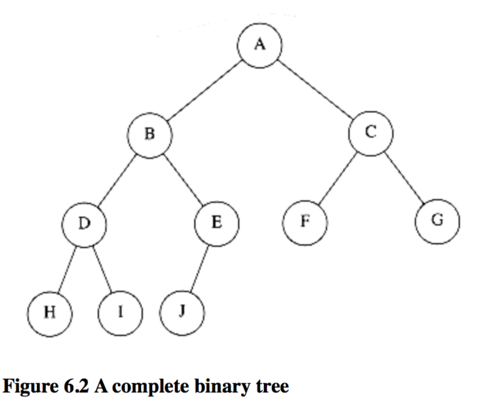
一颗高度为h的CBT有2h2h 到2h+1−12h+1−1 个节点,这就意味着CBT的高度是logNlogN。之前说物理上可以用数组实现是因为,CBT很有规律,可以用一个数组表示而不用指针。下图的数组对应图6.2中的堆

对于每一个位置为i的元素,左孩子在2i2i 上,右孩子在2i+12i+1 的位置,父亲则在i2i2上,所以不用指针而可以按下标访问。这种方法的唯一问题在于我们要事先估计堆的规模,从而确定开多大空间,不过这个也好解决。因此,堆这种结构将由一个数组、代表最大值的数、指示当前堆的最大规模的数字组成。下面先给出相关类型声明

#ifndef BinHeap_h #define BinHeap_h struct HeapStruct; typedef struct HeapStruct *PriorityQueue; PriorityQueue Init(int maxValue); void Insert(int X,PriorityQueue H); int Delete(PriorityQueue H); void PercolateDown(int *a,int root,int size); void Display(PriorityQueue H); void BuildHeap(int N,PriorityQueue H); #endif /* BinHeap_h */ struct HeapStruct { int capacity; //总空间 int size; //已有元素的规模 int *Element; };
堆序性质(重点)
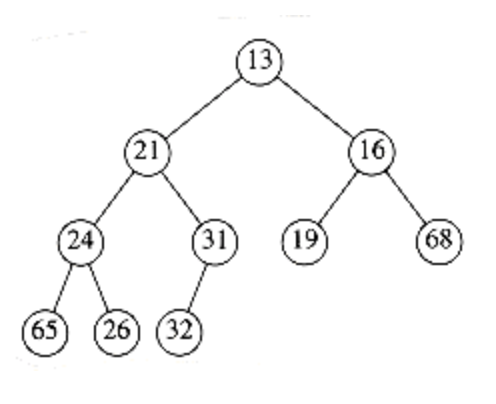
这个性质是保证动态操作高效率的关键,这个性质是说:任何一颗子树的树根都应该小于所有后代。也就是对于任何一个节点X,X父亲的关键字≤≤X的关键字,根节点除外。比如下面就是一个典型的堆。根据堆序性,最小元素可以在根处找到,所以可以用O(1)O(1)时间完成getMin()getMin()。
堆的初始化如下
//以小根堆为例 #define MinPQSize 5 #define MinData (-2) //初始化一个新的空堆 PriorityQueue Init(int maxValue){//参数是堆的最大规模 PriorityQueue H; if(maxValue < MinPQSize){ printf("Could you give more space?\n"); return NULL; } H=(PriorityQueue)malloc(sizeof(HeapStruct)); H->Element=(int*)malloc((maxValue+1)*sizeof(int));//保持一定冗余 H->capacity=maxValue; H->size=0; H->Element[0]=MinData; //这一句后面会解释其用途 return H; }
后续我们任何的操作都必须保持这两条性质,因此也可以猜测到,插入和删除的核心都是在于维护这两点,他们是堆所有操作算法的循环不变量。
现在我们来讨论基本的堆操作,插入和删除。其实都很容易实现,只需要始终保持堆序性。插入的时候可以直接把元素放在数组的末尾这样一来首先保持了结构性,接下来看满不满足堆序性,如果也满足,那插入过程就完成了。但往往是插入过程会破坏堆序,这时候要通过循环不变式使新元素推进到正确位置,然后再进行数据装填,可不能直接放到末尾。做法就是找到下一个空位置,然后把新节点的父亲放到这个空位里,腾出来的位置就是新节点当前的位置,形象上看就像他们”互换位置“。如此循环往复,这样一来新元素会逐渐向根上浮,直到抵达一个“新元素与其父满足堆序”的位置。举个例子吧,我们要插入14,先找到下一个位置,画个圈,如果14直接放进去,就破坏堆序,所以把31移动过来,那这个空圈就上浮一层。
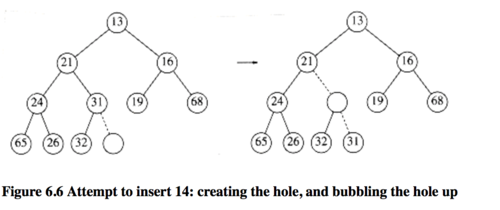
不断持续这个过程

直到找到放置14的正确位置。这种策略叫做上滤(percolate up),是插入的核心步骤。前面说了这好像父子互换位置,可能初学者会直接上去就swap两个数,但我们要注意的是,一次交换要三条赋值语句。如果一个元素上滤dd层,由于交换而进行的赋值语句就需要执行3d3d次,这……不太明智。现在这里有一个办法,只需要d+1d+1次赋值。
void Insert(int X,PriorityQueue H) { int i; //进行上滤 for (i=++(H->size); H->Element[i/2]>X; i/=2) { //取CBT的下一个空闲位置,如果满足heap order则进行插入,否则接收父节点数值 H->Element[i]=H->Element[i/2]; } H->Element[i]=X; }
这个循环直到满足父节点≤≤X的时候种植,这时候再把数据放进去,就是正确的位置了。这里再解释一些初始化程序里的一句话,第11行,这句话和链表的头节点起到了类似的作用。如果要插入的元素是新的最小值,那这个圆圈会一直被推向顶端,这样的话在某个时刻i=1i=1,我们需要终止循环。也可以用一个if完成,但我们采用的是放一个标记在i=0的位置,这个值必须$\leq $堆中的所有制。通过添加一个哑节点,避免了每个循环都要执行一次的测试,就节省了一些时间,像下面这个样子,这就保证了新插入的最小元素不会上浮得突破天际,到这就被拦住了。

如果新插入元素是最小元,那就会一直上滤到根,耗时高达O(logN)O(logN)。但平均情况会结束的早,大量数据证明,执行一次插入平均需要2.607次比较,因此插入操作会将新元素平均上移1.607层。
再说删除,这里的删除可不是像BST一样随意,你不能点菜,只能给你删除最小元素。删除的时候会 在根节点处产生一个空位,由于缺少了元素,就必须把最后一个元素放在合适位置,其余元素必须依照堆序性逐层补充上去,把当前这个空位两个儿子中较小的那个移入该空位。那其实这个修复过程是自上而下进行的,因此称为下滤。最后我们要把堆中末尾元素放到合适位置,比如说在下图左边的原始堆里删除13,整个流程就是
删除堆顶元素后,把较小的儿子放在空位,然后空位下滑一层:

接着把当前空位的小儿子放进来,继续下滑一层,直到最终把31放在底层的空位上,删除宣告完成。

不过这里有个疑点在于,刚开始的时候乍看之下“必须把最后一个元素放在合适位置”这话有点无厘头,为什么删除堆顶后还要顾及末尾元素?其实这是为了满足结构性质。我们也不妨换种思路理解这个过程,之前是逐层下滤,最后安置末尾元素,这个思考方式不太直观。现在这样想:删除堆顶后,在逻辑上就不是一颗结构完整的完全二叉树了,为了尽快恢复结构性,可以先把末尾元素送到堆顶(拆东墙补西墙,其他的事以后再说)。这一步之后结构性是恢复了,但是堆序性又破坏了,为了恢复堆序性,我们从堆顶开始执行下滤,走一轮就行了。整体过程如下:

其实这两种方法是殊归同途的。
由此我们也可以得到一个启示:对于堆的任何动态操作,脑海里时刻考虑1.结构性 2.堆序性两者如何维护
在堆的实现过程中经常发生的错误是当堆里存在偶数个元素时,此时会遇到某个节点只有一个儿子。所以要考虑到节点不总是有双子的情况,这会涉及到一个附加的测试,在下面的第14行。
1 int DeleteMin(PriorityQueue H){ 2 int i,child; 3 int MinElement,last; 4 5 MinElement=H->Element[1];//取出树根的值,根据heap order它是最小元素 6 last=H->Element[H->size--];//取出末尾元素以便后续安置 7 // H->Element[1]=last; 8 9 //执行下滤,搜索每个膝下有子的父节点 10 //具体做法是:把last放在沿着从根开始包含最小儿子的一条路径的某个恰当位置,这是步进条件的由来 11 for (i=1; i*2<=H->size; i=child) { 12 //首先确定下滤的孩子索引(找到更小的那个) 13 child=i<<1;//先取左孩子 14 if (child!=H->size && H->Element[child+1] < H->Element[child]) 15 child++; 16 17 //然后下滤一层 18 if (last > H->Element[child]) 19 H->Element[i]=H->Element[child]; 20 else 21 break; 22 } 23 H->Element[i]=last; //把最后一个元素放在合适的空穴里 24 return MinElement; 25 }
这是第一种办法,如果采用第二种办法,只需要把第7行的注释取消,然后23行打上注释即可。删除堆顶的最坏情况的运行时间是O(logN)O(logN),因为平均而言,末尾元素被提上去之后,经过下滤几乎总是又到达底层(他原来的那一层)的另一个合理位置,故几乎和堆深度的复杂度一致。
另外堆还有其他的操作,我们来一一端详,并简要介绍下在实际工程中的应用。比如求最小值,直接返回堆顶元素即可。但是求最大值就很难了,因为不确定在哪一片树叶上,而半数元素都在树叶上,这光靠堆自己去检索就心有余而力不足了。正因此,如果我们想要知道每个元素具体的位置,那么除了堆这种结构之外,还必须用到诸如散列表等其他的数据结构。那假如说我们通过某种绝妙的方法知道了具体位置,那么还有几种操作的开销会变小,最坏情况都是O(logN)O(logN):
DecreaseKey(pos,Δ,H)DecreaseKey(pos,Δ,H),语义是降低在位置pos处元素的值,减幅为$\Delta$,H是指向该堆的指针(下同),由于这个操作可能破坏堆序性,因此要通过上滤进行调整。这个操作有什么用?操作系统管理程序可以使用这个函数保证下属运行的程序以最高优先级运行。
IncreaseKey(pos,Δ,H)IncreaseKey(pos,Δ,H),语义是增加在位置pos处元素的值,增幅为$\Delta$,用下滤完成,用处在于:系统调度程序可以用其自动降低正在过多消耗CPU资源的进程优先级。
Delete(pos,H)Delete(pos,H),语义是删除堆中位置pos的节点。这通过先调用DecreaseKey(pos,Δ,H)DecreaseKey(pos,Δ,H),然后调用DeleteMin(H)DeleteMin(H)来完成。用处在于:当一个进程被用户强制中止时,就从系统的调度队列里删除。比如这个时候

BulidHeap(N,H)BulidHeap(N,H),批量建堆。把N个元素作为输入然后放入空堆中,以线性平均时间运行。
void PercolateDown(int *a,int root,int size) { int l,r,min; l=root<<1; r=(root<<1)+1; //找到局部子堆最小值的索引 if (l<=size && a[l]>a[root] ) min=root;//先比较lChild & root else min=l; if (r<size && a[r]<a[min]) min=r; if(min!=root){ //相等时意味已经满足最小堆的性质 swap(&a[root],&a[min]);//执行下滤 PercolateDown(a,min,size);//继续处理下一子堆 } } void BuildHeap(int N,PriorityQueue H) { for(int i=N/2;i>0;i--) PercolateDown(H->Element, i, H->size); }
总的代码如下,头文件就不在这里显示了,和上面的完全一样。
#include <stdio.h> #include <stdlib.h> #include <time.h> #include "BinHeap.h" //以小根堆为例 #define MinPQSize 5 #define MinData (-2) void swap(int *a,int *b) { int t=*a; *a=*b; *b=t; } //初始化一个新的空堆 PriorityQueue Init(int maxValue){//参数是堆的最大规模 PriorityQueue H; if(maxValue < MinPQSize){ printf("Could you give more space?\n"); return NULL; } H=(PriorityQueue)malloc(sizeof(HeapStruct)); H->Element=(int*)malloc((maxValue+1)*sizeof(int));//保持一定冗余 H->capacity=maxValue; H->size=0; H->Element[0]=MinData; return H; } void Insert(int X,PriorityQueue H) { int i; //进行上滤 for (i=++(H->size); H->Element[i/2]>X; i/=2) { //取CBT的下一个空闲位置,如果满足heap order则进行插入,否则和父节点交换数值 H->Element[i]=H->Element[i/2]; } H->Element[i]=X; } int DeleteMin(PriorityQueue H){ int i,child; int MinElement,last; MinElement=H->Element[1];//取出树根的值,根据heap order它是最小元素 last=H->Element[H->size--];//取出末尾元素以便后续安置 H->Element[1]=last; //执行下滤,搜索每个膝下有子的父节点 //具体做法是:把last放在沿着从根开始包含最小儿子的一条路径的某个恰当位置,这是步进条件的由来 for (i=1; i*2<=H->size; i=child) { //首先确定下滤的孩子索引(找到更小的那个) child=i<<1;//先取左孩子 if (child!=H->size && H->Element[child+1] < H->Element[child]) child++; //然后下滤一层 if (last > H->Element[child]) H->Element[i]=H->Element[child]; else break; } //把最后一个元素放在合适的空穴里 return MinElement; } void PercolateDown(int *a,int root,int size) { int l,r,min; l=root<<1; r=(root<<1)+1; //找到局部子树最小值的索引 if (l<=size && a[l]>a[root] ) min=root;//先比较lChild & root else min=l; if (r<size && a[r]<a[min]) min=r; if(min!=root){ //相等时意味已经满足最小堆的性质 swap(&a[root],&a[min]);//执行下滤 PercolateDown(a,min,size);//继续处理下一棵树 } } void Display(PriorityQueue H){ for(int i=1;i<=H->size;i++) printf("%d ",H->Element[i]); printf("\n"); } void BuildHeap(int N,PriorityQueue H) { for(int i=N/2;i>0;i--) PercolateDown(H->Element, i, H->size); } int main(){ srand(time(nullptr)); int n; scanf("%d",&n); PriorityQueue pq=Init(n); for(int i=0;i<n;i++) Insert(rand()%988, pq); // BuildHeap(n, pq); Display(pq); printf("The min is %d.\n After deletion the heap is:\n",DeleteMin(pq)); Display(pq); }
下一篇是优先队列里的又一变种,你猜猜是哪个?
原文出处:https://www.cnblogs.com/hongshijie/p/9607461.html





