
今天,本神给小伙伴们分享下国外 lmax 平台的核心-无锁并行计算框架!LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理600万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动的方式。业务逻辑驱动器的核心是Disruptor。Disruptor主动将数据发送到数据消费端,600万指的是分发给消费端的订单数!
好吧,看到介绍,给跪了,单线程撸出600万的量,不是一般的框架能够做到的,我们的disruptor,做到了。
一、何为Disruptor?
简单来说他就是一个有界队列,类似我们所熟悉的JDK里并发包下的ArrayBlockingQueue。复杂来说,他具有ArrayBlockingQueue做不到的强大功能,比如串并行操作、多生产者多消费者模型。
github传送门送一下求生欲望超强的小伙伴:https://github.com/LMAX-Exchange/disruptor
二、你为何这么牛掰?
接下来我们一起聊了Disruptor为何这么6,性能如此之好!
首先介绍ringbuffer。我对Disruptor的最初印象就是ringbuffer。但是后来我意识到尽管ringbuffer是整个模式(Disruptor)的核心,但是Disruptor对ringbuffer的访问控制策略才是真正的关键点所在。
嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
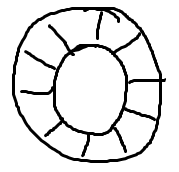
基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。
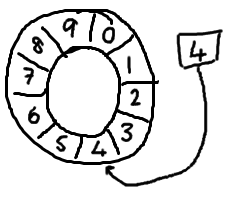
随着你不停地填充这个buffer,可能也会有相应的读这个序号会一直增长,直到绕过这个环。
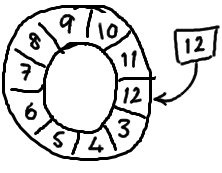
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息。如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。我们需要将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们,听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息:
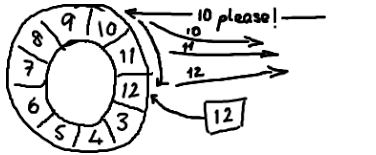
我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分–如果你等不急我写blog来说明它们,那么可以自行检出Disruptor项目)
他为什么如此优秀哪?
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)。
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
哪它为什么会这么快?
CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一
块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一
个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)
我喜欢在LMAX工作的原因之一是,在这里工作让我明白从大学和A Level Computing所学的东西实际上还是有意义的。做为一个开发者你可以逃避不去了解CPU,数据结构或者大O符号 —— 而我用了10年的职业生涯来忘记这些东西。但是现在看来,如果你知道这些知识并应用它,你能写出一些非常巧妙和非常快速的代码。
因此,对在学校学过的人是种复习,对未学过的人是个简单介绍。但是请注意,这篇文章包含了大量的过度简化。
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。本文将忽略硬件驱动和网络之类的东西,因为Disruptor的目标是尽可能多的在内存中运行。
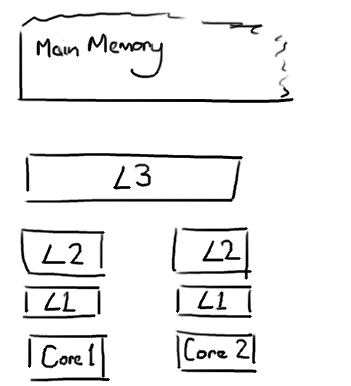
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
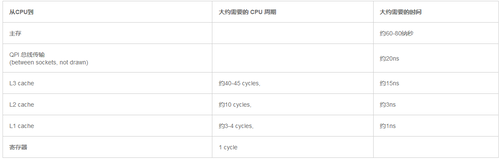
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
缓存行
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节(译注:这篇文章发表时常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
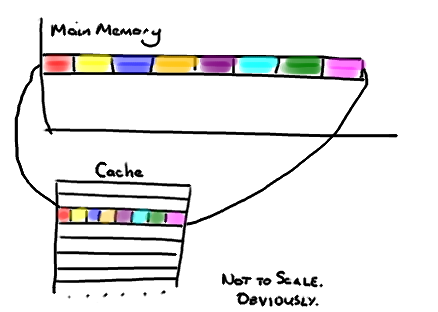
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。我在第一篇关于ring buffer的文章中顺便提到过这个,它解释了我们的ring buffer使用数组的原因。
因此如果你数据结构中的项在内存中不是彼此相邻的(链表,我正在关注你呢),你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
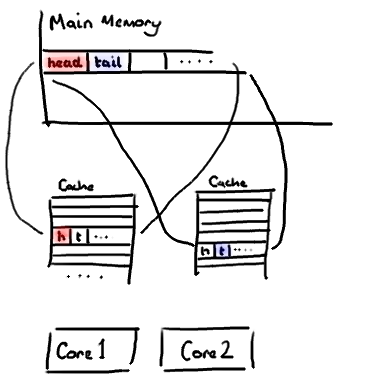
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。
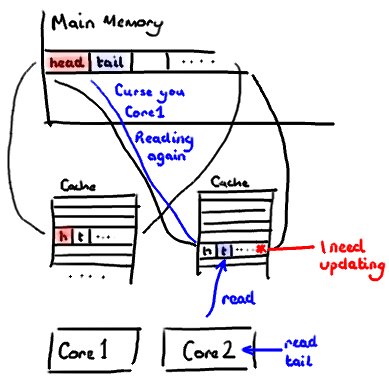
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
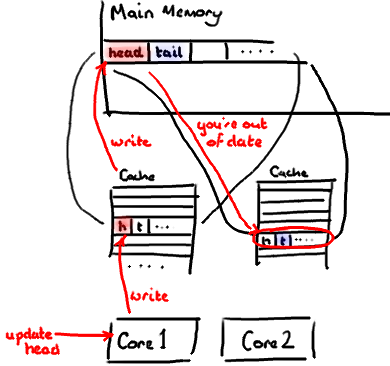
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。

因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
在你的Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。
修改:Martin写了一个从技术上来说更准确更详细的关于伪共享的文章,并且发布了性能测试结果。
欢迎关注课程:《Java并发编程高阶技术高性能并发框架源码解析与实战》















热门评论
-

brucelwl2018-11-04 1
-

fly_烟雨行舟2019-01-26 0
-

brucelwl2018-11-04 0
查看全部评论话说你在disruptor课程里面,多生产者,多消费者里面有个地方讲的有问题
老师,请问你这个框架既然性能这么好,是不是挺吃机器内存的,对硬件要求蛮高啊。
disruptor中除了有等待策略是否有拒绝策略呢? 只看到有timeoutException,然后在TimeoutHandler中回调等待获取的序号,但是这个时候怎么得到等到投递的数据呢?