
激活函数是什么
激活函数,即Activation Function,有时候也称作激励函数。它是为了解决线性不可分的问题引出的。但是也不是说线性可分就不能用激活函数,也是可以的。它的目的是为了使数据更好的展现出我们想要的效果。
激活函数在哪里用?
比如一个神经网络
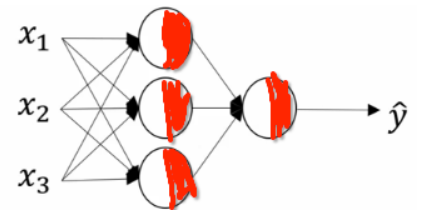
为了更清晰的表示,我用红色标出。比如像上面的网络z = W*x,这个线性运算就是上面节点白色的部分,另一部分当然就是F(z)了。则第一层隐层(除了输入和输出层,其他都为隐层,因为'看不见')输出的就是F(z)。但是不是说所有层都要经过激活函数。根据自己的情况而定。
为什么要用激活函数
这个用简单的数学推导即可。
比如有两层隐层网络:z_1 = W_1*x, z_2 = W_2*z_1 (x为输入层,W_1, W_2为两个隐层,z_2为输出层)
则z_2 = W_2*z_1 = W_2*W_1*x = W*x
可以看出,无论经过多少次隐层,跟经过一层的是一样的。简单的应该看出来激活函数的作用了吧。
激活函数该怎么用
就一个一个说说常用的吧。
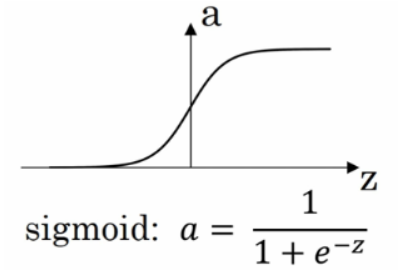
sigmoid
sigmoid函数,范围是(0,1)。如果你想要你的数据近可能的处在0或1上,或者你要进行二分类,就用这个函数吧。其他的情况尽量不要用。或者几乎从来不用。因为,下面的这个函数几乎在任何场合都比sigmoid更加优越。
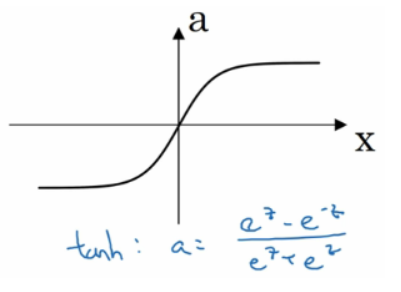
tanh
tanh函数,范围是(-1,1)。如果想让数据尽可能在-1和1之间,就考虑这个吧。
但是,sogmoid和tanh有个很明显的缺点:在z很大或者很小的时候,导数几乎是零,也就是在梯度下降优化时几乎更新不了。然而在机器学习中最受欢迎的莫过于修正线性单元reLU(rectified Linear Unit)。下面就是:
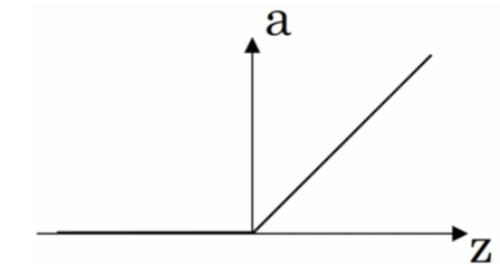
reLU
reLU = max(0, z) 当z小于零时,导数为0,当z大于0时,导数为1。这个激活函数几乎变成默认的激活函数,如果你不知道用什么激活函数的话。
虽然遇到向量z(0,0,0,0,0,0,0,0,...,0)的几率贼小,但是为了万无一失,有人就提出了下面的reLU版本:
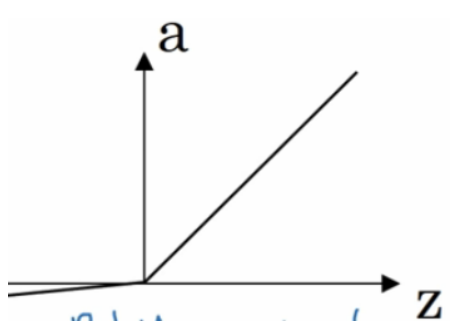
leaky reLU
leaky reLU = max(0.01z, z) 叫做 带泄漏reLU,0.01这个值是经验值,在z小于0的时候有个特别特别缓的直线。这个比reLU好用,但是实际用的真的不多。
reLU和leaky reLU的好处在于当z大于0时,导数和0差的很远。所以在实际实践中,用reLU和leaky reLU会使得神经网络学习速率快很多。虽然有z有小于0的可能,但是在实际中,有足够多的隐层单元是的z大于0
激活函数的导数
sigmoid F'(z) = 1 - F(z)
tanh F'(z) = 1 - F^2 (z)
1 if z >= 0
reLU F'(z) =
0 if z < 0
1 if z >= 0
leaky reLU F'(z) =
0.01 if z < 0
作者:zenRRan
链接:https://www.jianshu.com/p/916243941347





