
集合就是一组数的集合,就像是一个容器,但是我们应该清楚的是集合中存放的都是对象的引用,而不是真正的实体。而我们常说的集合中的对象其实指的就是对象的引用。
我们可以把集合理解为一个小型数据库,用于存放数据,我们对集合的操作也就是数据的增删改查,在 Java 中有两个顶层接口 Collection 和 Map 用于定义和规范集合的相关操作。这篇文章主要说一下集合框架中的 Collection 部分。
Collection 表示一组对象,这些对象可以是有序也可以是无序的,它提供了不同的子接口满足我们的需求。我们主要看看 List 和 Set 。
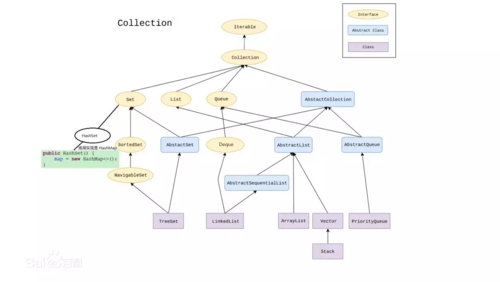
List 整体的特征就是有序可重复。我们需要研究的是上图中具体的实现类都有什么特性。底层的实现原理是什么,首先来看一看 List 的古老的实现类 Vector ,说是古老是因为在 JDK 1.0 的时候就出现了,都走开,我要开始看源码了!这些源码来自于 JDK 1.7。

public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{ /**
* The array buffer into which the components of the vector are
* stored. */
protected Object[] elementData; /**
* The number of valid components in this {@code Vector} object. */
protected int elementCount; /**
* The amount by which the capacity of the vector is automatically
* incremented when its size becomes greater than its capacity. If
* the capacity increment is less than or equal to zero, the capacity
* of the vector is doubled each time it needs to grow. */
protected int capacityIncrement; public Vector() { this(10);
} // 添加元素
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e; return true;
} // 删除元素
public synchronized E remove(int index) {
modCount++; if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index); int numMoved = elementCount - index - 1; if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
} // 修改元素
public synchronized E set(int index, E element) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element; return oldValue;
} // 查找元素
public synchronized E get(int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); return elementData(index);
}
...
就以上源码分析就可以知道关于 Vector 的特征。1 底层实现是使用数组来存储数据,所以相应的查找元素和添加元素速度较快,删除和插入元素较慢。2 数组的初始长度为 10 ,当长度不够时,增长量也为 10 使用变量 capacityIncrement 来表示。3 方法的声明中都加入了 synchronized 关键字,线程安全的,所以效率相应降低了。 4 没分析出来的再看一遍。
下面开始看 ArrayList 的源码。
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{ private static final long serialVersionUID = 8683452581122892189L; /**
* Default initial capacity. */
private static final int DEFAULT_CAPACITY = 10; /**
* Shared empty array instance used for empty instances. */
private static final Object[] EMPTY_ELEMENTDATA = {}; /**
* The array buffer into which the elements of the ArrayList are stored.
* DEFAULT_CAPACITY when the first element is added. */
private transient Object[] elementData; /**
* Constructs an empty list with an initial capacity of ten. */
public ArrayList() { super(); this.elementData = EMPTY_ELEMENTDATA;
} // 添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e; return true;
} // 增加数组的长度
private void grow(int minCapacity) { // overflow-conscious code
int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0)
newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
...
因为源码和 Vector 类似,所以有些就不贴了,但是不耽误我们继续分析 ArrayList 。1 底层存储数据使用的还是数组,长度依旧为 10 ,但是进步了,没有在刚开始创建的时候就初始化,而是在添加第一个元素的时候才初始化的。2 方法的声明少了 synchronized 关键字,线程不安全,但性能提高了。3 数组长度不够时,会自动增加为原长度的 1.5 倍。
以上分析也能体现出 Vector 和 ArrayList 的差别。主要就是想说 Vector 已经不用了。使用 ArrayList 即可,关于线程安全问题,后面再说。
接着看 LinkedList 的实现,上源码 ~
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{ transient int size = 0; /**
* Pointer to first node. */
transient Node<E> first; /**
* Pointer to last node. */
transient Node<E> last; /**
* Constructs an empty list. */
public LinkedList() {
} // 每一个元素即为一个节点,节点的结构如下(这是一个内部类啊)
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev;
}
} // 添加元素
public boolean add(E e) {
linkLast(e); return true;
} void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null);
last = newNode; if (l == null)
first = newNode; else
l.next = newNode;
size++;
modCount++;
} // 删除某个节点的逻辑
E unlink(Node<E> x) { // assert x != null;
final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
} if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++; return element;
}
...
重点就是 LinkedList 的底层实现是双链表。这样就会有以下特性,1 查找元素较慢,但是添加和删除较快。2 占内存,因为每一个节点都要维护两个索引。3 线程不安全 。4 对集合长度没有限制。
以上,List 的几个实现已经分析完成,以后再谈到 Vector ,ArrayList ,LinkedList 之间的区别应该不会不知所云了吧!还要接着看 Collection 的另一个子接口 Set 。首先有个大前提,Set 中存储的元素是无序不可重复的。然后我们再来看实现类是如何实现的。下面开始 HashSet 的表演。
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
{ private transient HashMap<E,Object> map; // Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object(); /**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75). */
public HashSet() {
map = new HashMap<>();
} // 添加元素,其实就是像 Map 中添加主键,所以添加的元素不能重复
public boolean add(E e) { return map.put(e, PRESENT)==null;
} // 实现 Iterable 接口中的 Iterator 方法。
public Iterator<E> iterator() { return map.keySet().iterator();
}
...
看了源码才发现,1 原来 HashSet 就是对 HashMap 的封装啊,底层实现是基于 hash 表的,回头有必要再好好的介绍一下 hash 相关的知识。2 Set 集合中的值,都会以 key 的形式存放在 Map 中,所以说 Set 中的元素不能重复。3 线程不安全。4 允许存放空值,因为 Map 的键允许为空。
今天要说的最后一个实现类终于出现啦,他就是 TreeSet ,这个实现类中的元素是有序的!注意这里说的有序是指按照一定的规则排序,而我们说 Set 集合中的元素无序是因为添加进集合的顺序和输出的顺序不保证一致。TreeSet 是怎么保证有序我们待会再说,还是一样的套路,是对 TreeMap 的封装,线程依旧不安全。
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable
{ /**
* The backing map. */
private transient NavigableMap<E,Object> m; // Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object(); /**
* Constructs a set backed by the specified navigable map. */
TreeSet(NavigableMap<E,Object> m) { this.m = m;
} /**
* Constructs a new, empty tree set, sorted according to the
* natural ordering of its elements. All elements inserted into
* the set must implement the Comparable interface. */
public TreeSet() { this(new TreeMap<E,Object>());
} /**
* Constructs a new, empty tree set, sorted according to the specified
* comparator. All elements inserted into the set must be mutually
* comparable by the specified comparator
* If the Comparable natural ordering of the elements will be used. */
public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator));
}
// 添加元素方法
public boolean add(E e) { return m.put(e, PRESENT)==null;
}
...
我们可以看到 TreeSet 中构造函数上方的注释,TreeSet 要保证元素有序,保证有序的思路是在添加元素的时候进行比较。
... // 这是 TreeMap 的 put 方法的节选,为了看到比较的过程。
public V put(K key, V value) {
... // split comparator and comparable paths
Comparator<? super K> cpr = comparator; if (cpr != null) { do {
parent = t;
cmp = cpr.compare(key, t.key); if (cmp < 0)
t = t.left; else if (cmp > 0)
t = t.right; else
return t.setValue(value);
} while (t != null);
} else { if (key == null) throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key; do {
parent = t;
cmp = k.compareTo(t.key); if (cmp < 0)
t = t.left; else if (cmp > 0)
t = t.right; else
return t.setValue(value);
} while (t != null);
}
...
}
Java 中提供了两种方式,第一种方法,需要我们所添加对象的类实现 Comparable 接口,进而实现 compareTo 方法,这种方式也叫自然排序,我们并没有传入什么排序规则。这种方式对应 TreeSet 的空参构造器。而另一种方式就是定制排序,即我们自己定义两个元素的排序规则,在实例化 TreeSet 的时候传入对应的排序规则即可,对应于 TreeSet 中带有 Comparator 接口的构造器,这里面需要实现 compare 方法 。有点迷糊了是吧,举个例子看看 ~
public class Person implements Comparable<Person>{ public String name; public Integer age; public Person(String name,Integer age) { this.name = name; this.age = age;
} /* 自定义的比较的逻辑:
* 首先按照对象的 name 属性排序
* 其次按照 age 属性排序
* 方法的返回值为 0 ,大于 0,小于 0 ,分别对应于 相等,大于,和小于 */
@Override public int compareTo(Person o) { int i = this.name.compareTo(o.name); if(i == 0){ return this.age.compareTo(o.age);
}else { return i;
}
}
@Override public String toString() { return "[Person] name:"+this.name+" age:"+this.age;
}
} // 以下是测试代码
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("AJK923",20));
set.add(new Person("BJK923",20));
set.add(new Person("AJK923",21));
set.add(new Person("BJK923",21)); for (Person person : set) {
System.out.println(person.toString());
} /*
[Person] name:AJK923 age:20
[Person] name:AJK923 age:21
[Person] name:BJK923 age:20
[Person] name:BJK923 age:21 */
----以下为定制排序的部分----匿名内部类实现 Comparator 接口----
TreeSet<Person> set2 = new TreeSet<>(new Comparator<Person>() {
@Override public int compare(Person o1, Person o2) { int i = o1.age.compareTo(o2.age); if(i == 0){ return o1.name.compareTo(o2.name);
}else { return i;
}
}
});
set2.add(new Person("AJK923",20));
set2.add(new Person("BJK923",20));
set2.add(new Person("AJK923",21));
set2.add(new Person("BJK923",21)); for (Person person : set2) {
System.out.println(person.toString());
} /*
[Person] name:AJK923 age:20
[Person] name:BJK923 age:20
[Person] name:AJK923 age:21
[Person] name:BJK923 age:21 */
}
上面就是自然排序和定制排序的应用。要说明几点:
1 定制排序和自然排序同时存在的话,优先执行定制排序。可以看看上面的 put 方法的实现 。
2 自然排序对应 Comparable 接口,定制排序对应 Comparator 接口。
3 String ,包装类,日期类都已经实现了 Comparable 接口的 comparaTo 方法,所以我上面的例子中都偷懒了,没有自己实现具体比较,而是直接调用现成的。
看到这里,也算是对 Collection 有了整体的认识,但是这里我并没有说到具体的 API ,我现在日常也用不到几个方法,就放一张 Collection 接口的结构图吧,方法也比较简单,看个名字就大概知道什么意思了。
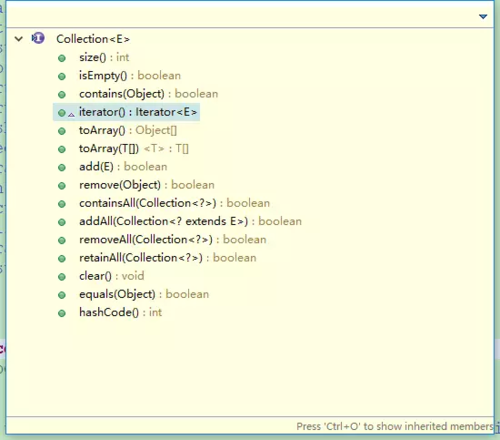
还是要重点说一下 iterator 方法。这个方法定义在 Iterable 接口中(Collection 继承了 Iterable 接口),方法返回的是 iterator 接口对象。iterator 中定义了迭代器的操作规则,而 Collection 的实现类中是具体的实现。Iterator 接口中定义了 next ,hasNext 和 remove 方法。看一下在ArrayList 中是如何实现的吧。
private class Itr implements Iterator<E> { int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount; public boolean hasNext() { return cursor != size;
}
@SuppressWarnings("unchecked") public E next() {
checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException();
cursor = i + 1; return (E) elementData[lastRet = i];
} public void remove() { if (lastRet < 0) throw new IllegalStateException();
checkForComodification(); try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException();
}
} final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException();
}
}
应用起来还是比较简单的,使用一个 while 循环即可。看下面这个例子。 public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> it = list.iterator(); while (it.hasNext()) {
Integer i = it.next();
System.out.println(i);
}
}
不知道你有没有发现,除了 Vector 以外,保存集合元素的那个变量都定义为 transient 不管你是数组,Node 或是 Map ,不由得我又要想一想为什么这样设计?
先看一下 transient 的作用吧!Java 的 serialization 提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用 serialization 机制来保存它。为了在一个特定对象的一个域上关闭 serialization,可以在这个域前加上关键字 transient 。当一个对象被序列化的时候,transient 型变量的值不包括在序列化的表示中,非 transient 型的变量是被包括进去的。
那么为什么要这么做呢,好好的标准序列化不用,原因如下:
对于 ArrayList 来说,底层实现是数组,而数组的长度和容量不一定相等,可能容量为 10 ,而我们的元素只有 5 。此时序列化的时候就有点浪费资源,序列化和反序列化还是要的,故 ArrayList 自己实现了两个方法,分别是 writeObject 和 readObject ,用于序列化和反序列化。
对于 HashSet 和 HashMap 来说,底层实现都是依赖于 hash 表,而不同的 JVM 可能算出的 hashCode 值不一致,这样在跨平台的时候就会导致序列化紊乱。故也重写了那两个方法。借用一句似懂非懂的话:
当一个对象的物理表示方法与它的逻辑数据内容有实质性差别时,使用默认序列化形式有 N 种缺陷,所以应该尽可能的根据实际情况重写序列化方法。
对应于 Collection ,有一个 Collections 工具类,其中提供很多方法,比如说集合的排序,求子集合,最大值,最小值,交换,填充,打乱集合等等,还记得上面说到的实现类中存在线程不安全的情况吧,这个工具类中提供很多对应的 synchronized 的方法。
后记 :不知不觉中扩展了这么多知识点,实话说,肯定还有遗漏的地方,就我现在能想到的依然还有很多,除去 Hash 表和 Hash 算法这一部分之外,我还没有对底层的数据结构进一步分析,数组,链表,二叉树等等,现在是分析不动了,本文已经很长了。
原文出处:https://www.cnblogs.com/YJK923/p/9498975.html





