
模拟登录过程的核心,是传送post请求时携带包含用户信息的参数(账号、密码、验证码),并且在整个爬取过程中,所有请求都要携带同一个cookie。
爬取的整个思路和步骤为:
请求网站登录路径,保存返回的cookie,并作为全局变量用于整个爬取过程
请求验证码,将识别后的文本保存下来
请求加密地址,通过AES加密过程获取密钥,并根据加密函数加密密码
发送包含登录名、加密密码、识别后验证码的post请求到登录地址
确认登录状态,如果成功则可以开始爬取数据
首先解决cookie初始化问题。通过cookielib和urllib2模块相结合来保证爬取过程中cookie的一致性,cookielib模块通过CookieJar类的对象来捕获cookie,建立存储cookie的对象cj,该对象只更新却不删除cookie,从而保证cookie自始至终一致。然后实例化一个全局opener,并绑定cookie库(即cj对象),此后opener发送请求和接受响应使用的cookie都会存在cj。最后安装opener对象。
import urllib2 import cookielib cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener)
需要注意,cj和opener都为全局变量,不能写在模块内部,这样整个爬取过程都能使用同一个cookie。初始化存放cookie的cj对象后,请求网站的登录路径,使用opener.open()将返回的cookie存入cj对象。
headers = {"User-Agent": "",
"Accept-Encoding": "gzip, deflate",
"Host": "",
"Referer": ""}
loginURL = ""
def receiveCookie():
requestLogin = urllib2.Request(loginURL, headers=headers)
responseLogin = opener.open(requestLogin)
receiveCookie()接下来是验证码的识别。由于爬取网站的验证码干扰项太多,用网上说的PIL包pytesseract包识别准确率仍然不理想,在工作任务要求时间紧张的情况下,我暂时选择了笨办法:获取验证码图像-->保存并弹出-->人工识别。由于始终爬取同一用户数据,且仅登录一次,因此只需要人工识别一次即可,以后有时间研究神经网络图像识别后再补充这部分吧。
import cStringIO
from PIL import Image
def receiveImage():
urlIm = ""
requestIm = urllib2.Request(urlIm, headers=headers)
responseIm = opener.open(requestIm)
fileIm = cStringIO.StringIO(responseIm.read())
img = Image.open(fileIm)
img.show()
receiveImage()
verify = raw_input("input verify:")由于一开始获得的cookie存入cj对象,因此之后所有的opener.open()命令都会携带该cookie,获得对应网址的响应。这里把验证码图片数据的读取内容通过cStringIO模块模拟成本地文件(实质是内存上的文件),可以像操作磁盘文件一样操作该文件。
其实一开始是直接使用urllib.urlretrieve()直接将验证码图片网址保存到本地后弹出,但是多次登录失败后发现这样写无法传递cookie,促使获得的验证码图片根本不是我们一开始登录时看到的图片,在保存图片的过程中实质又获得另一个cookie,因为cookie的不一致,网站无法保证两次行为是同一用户所为。而使用cStringIO模块前一步,刚好用opener携带了cookie。最终将弹出的图像肉眼识别后输入给verify变量。
最后是密码。爬取该网站时的一个大坑是密码是通过密钥加密的,通过fiddler捕获发现传递的post数据中password不是实际密码,

并且在输入各项用户参数后、登录成功前网站自动跳转到带有GetAESCode字样的路径并返回一串字母数字组成的密钥,这应该就是传说中的AES加密功能。
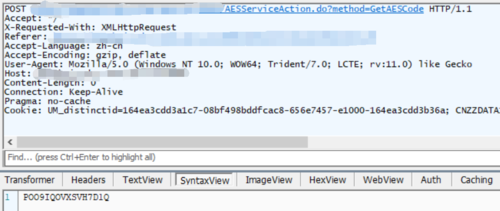
在登录页面调出控制台,password确实通过一个叫Encrypt()的函数加密,其加密原理是通过密钥code对实际密码进行转换。因此获得加密密码的整个过程拆分为:请求密钥路径-->获得密钥-->密码+密钥=加密后密码。最后一步可以将Encrypt函数的java代码转换成python格式写入py文件,也可以直接在控制台手动调用该函数,将结果传递给password变量。
def receiveCode():
urlCo = ""
requestCo = urllib2.Request(urlCo, headers=headers)
responseCo = opener.open(requestCo)
code = responseCo.read()
print “密钥:” + code
receiveCode()
password = raw_input("input pwd:")获得验证码、加密密码后算是大功告成,将三个参数传递给post请求,模拟登录。
def login():
dataList = {
"activity" : "login",
"userId": "",
"password": password,
"verifyCode": verify}
dataList = urllib.urlencode(dataList)
req = urllib2.Request(loginURL, dataList, headers)
res = opener.open(req)此时可以查看返回的响应是否为登录成功后实际看到的页面内容,如果是代表模拟登录成功,可以放心爬取任何内容了!
这是我第一次模拟登录如此复杂繁琐的网站,对于爬虫小白来说,对整个过程的理解和资料的搜集都比较困难,希望把这次经验好好记下,提醒自己温故知新,也希望能帮助更多的码农。








热门评论
-

CodeForLife_2019-04-07 0
查看全部评论学习了