
首先跟大家解释下,为什么更新的是关于爬虫的内容而不是open.cv。因为小编想继承上一篇帖子(python数据可视化之WordCloud)的内容,上篇帖子只是简单的介绍了wordcloud的安装和使用方法,但是应用部分却没有怎么提及。今天,我们用爬虫来获取网页,然后再用word cloud做词云分析。
一、爬虫框架的搭建
1.1网络爬虫的基本思路
爬虫的目的是获取网页的信息,一般的应用就是搜索引擎了。今天小编就以爬取搜狐新闻为例跟大家聊聊爬虫的这些事儿。我们一般是通过requests库向web提出请求,然后通过BeautifulSoup库对页面内容进行解析,再次是利用正则表达式对获取的页面内容进行详解和筛选关键信息。具体的流程如下图:
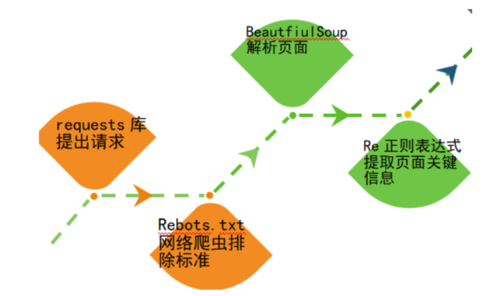
爬虫1.PNG
安装requests库的方法:只需在命令行输入:“pip install requests”即可,这次我们用到的库一共是5个:requests、BeautifulSoup、jieba、re(re是python的内置模块,无需安装)、WordCloud。前三种库的安装方法同requests是一样的,所以小编就不赘述,WordCloud的安装参考这篇帖子。
requests库的使用方法很简单,也很容易掌握,主要的方法如下:

爬虫2.PNG
接下来,小编介绍下jieba库的使用:jieba是优秀的中文分词第三方库,中文文本需要通过分词来获得单个词语,它提供三种分词模式,主要是依靠中文词库,除了分词,用户还可以自定义添加词组。总的来说,jieba的分词要点就是:jieba.lcut(txt)。
二、实例
2.1 构造请求,获取页面内容进行解析
第一步我们需要构造请求,获取页面内容,具体的代码如下:
import requestsfrom bs4 import BeautifulSoup url = "https://www.sohu.com/a/226127592_139908"responce = requests.get(url) soup = BeautifulSoup(responce.text,'lxml') #lxml用来解析网页responce.status_code #如果返回值为200则表示访问成功
2.2抓取页面,获取关键信息
我们需要进入开发者模式(一般是按F12或者是单击鼠标右键选择“检查//审查元素”选项卡),找到我们的想要的对象,这时对应的HTML源码部分就会变蓝,具体的操作如下图:
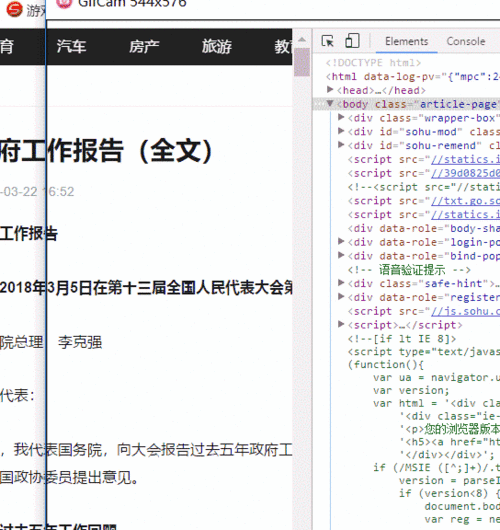
示例1.gif
我们的目标是获取2017年度政府报告的全文,注意到这部分文本在 article类的article标签下,可以利用BeautifulSoup模块下的find函数进行查找,即
links_div = soup.find("article",class_="article")#links_div 我们可以尝试输出下获取的文本,验证是否是我们想要的text = links_div.strip() #对字符串进行切片操作2.3 接下来,我们把得到的页面内容作为对象保存到字典中,然后再写入到本地的记事本中
dic = {text}with open("C:\\Users\qinglifang\\Desktop\\pictures\\report.txt",'a',encoding='utf-8')as f:
f.write(str(dic))
f.close()2.4 然而,我们注意到获取的页面内容中有html的标签和其他符号存在,不利于下一步的词云操作,所以需要利用jieba和正则表达式对得到的文本进行清洗。
import jiebaimport re
r ='[,。\%、;1234567890n]'file=open("report.txt","r",encoding='utf-8').read()
file =re.sub(r,'',file) #剔除无关信息con = jieba.lcut(file) #分词words = " ".join(con) #分词后插入空格2.5词云分析
from wordcloud import WordCloud
wordcloud = WordCloud(font_path="simkai.ttf",background_color="white",width=800, height=660).generate(words)
#我们注意到wordcloud对中文很不友好,必须要进行jieba分词,还应该再WordCloud中增加设置字体的参数#否则生成的词云图片是方框型的wordcloud.to_file('pic.png') #保存图片2.6结果展示

pic.png
三、小结
有的网站增加了反爬虫的识别功能,这时我们需要修改requests的头文件。再者就是做爬虫时,我们应该遵循目标网站的robots协议。感兴趣的同学们,可以自己试着爬取一些网上商品的信息或者其他有趣的网页内容。在小编的下一篇帖子中,会为大家正式介绍open.cv的强大功能。
创作不易,喜欢我就点个赞吧。
(本文原创,如需引用,请注明出处)
作者:氢立方
链接:https://www.jianshu.com/p/605ab76c9fb0






