
背景
今天老板让核查新上线的app中的中标数据展示情况,一条一条数据点开看实在是太慢了,于是想抓包获取app请求的api接口以及传入的参数,获取返回的数据内容,将数据存储到sqlite3中直接通过执行sql来统计数据质量。
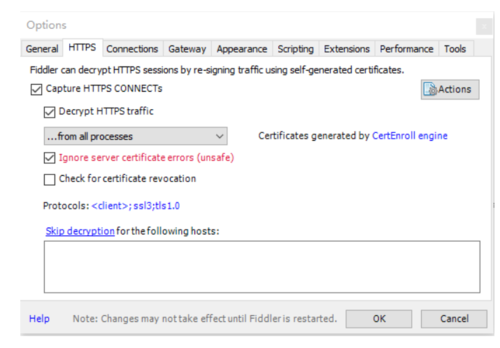
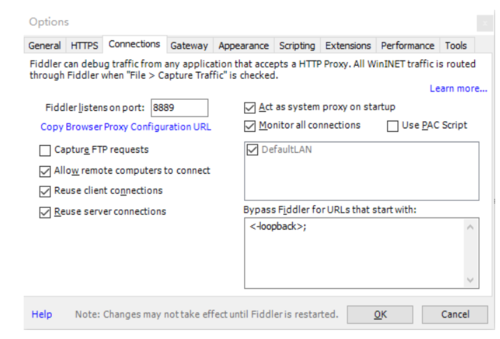
先打开fiddle4,设置好代理,设置如下:
mr_酱
mr_酱
scrapy 项目初始化
执行命令创建项目:
scrapy startproject wltx_app cd wltx_app
执行如下命令先创建spider,命令如下:
scrapy genspider zhongbiao wltx.cmcc-cs.cn
打开spiders/zhongbiao.py文件内容如下:
# -*- coding: utf-8 -*-import scrapyclass ZhongbiaoSpider(scrapy.Spider): name = 'zhongbiao' allowed_domains = ['wltx.cmcc-cs.cn'] start_urls = ['http://wltx.cmcc-cs.cn/'] def parse(self, response): pass
fiddler4准备
ok,到这里爬虫项目的初始化工作已经完成,下面开始抓包分析请求和响应的数据信息。
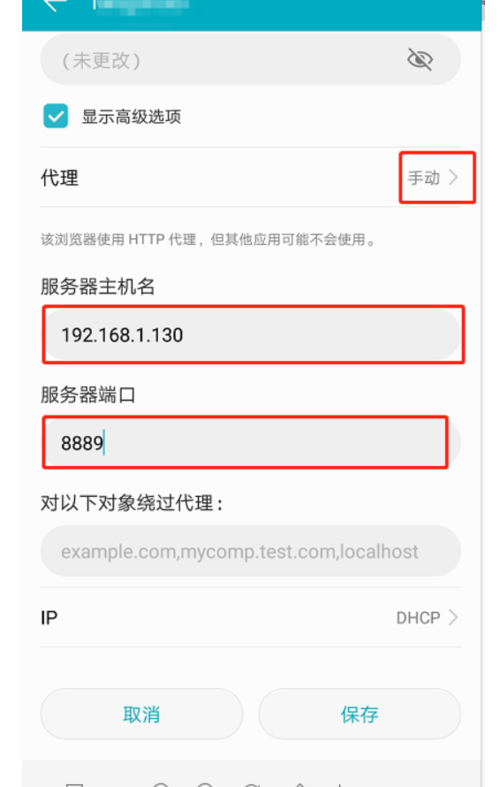
首先,手机要和打开fiddler4的笔记本在一个局域网中,在手机的wifi设置中长按该wifi名称,点击【修改网络】,勾选显示高级选项,
代理:手动
服务器主机名:打开fiddler4的电脑ip地址
服务器端口号:以fiddler4中的端口号为准,默认是8888,我这里设置的是8889
mr_酱
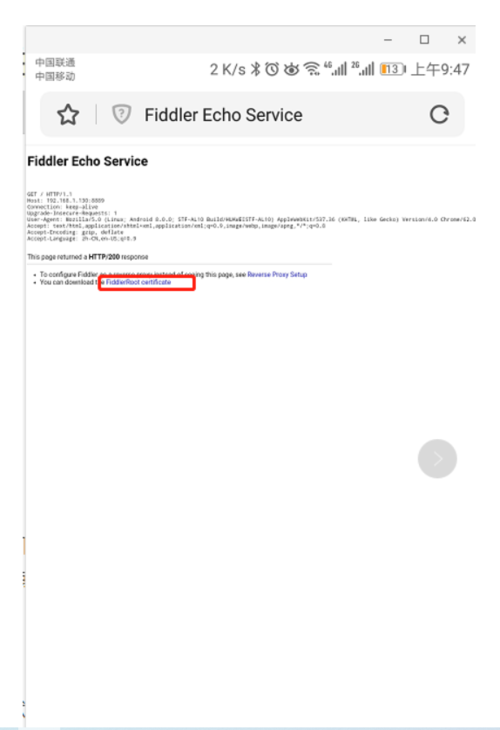
点击保存,手机上打开浏览器刷新网页是不是fiddle上就显示出抓取的手机网页了,如果是第一次使用,需要在浏览器中打开http://服务器主机名:服务器端口号。
mr_酱
点击最下面的连接安装CA证书,才可以解析https的请求内容和响应内容。
抓包分析
打开手机app,点击老板让分析的中标模块,fiddler4上瞬间出现大量请求记录,看了一下app的请求域名应该是wltx.cmcc-cs.cn,那么勾选Filters,勾选User Filters,选择【show only the following Hosts】在下方的输入框中输入“wltx.cmcc-cs.cn”,截图如下:
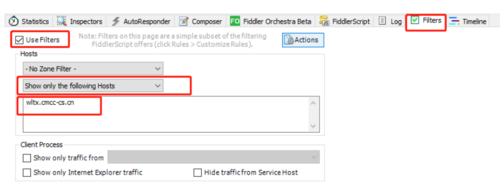
mr_酱
点击Actions>run filter set now,应用该过滤设置,在fiddler4左侧的抓取结果区域中显示的则都是该域名相关的抓取结果。
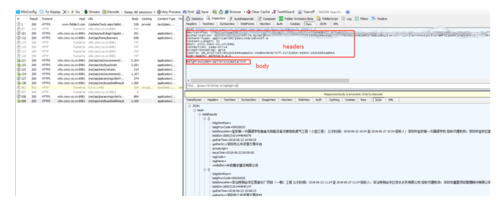
mr_酱
在该图中可以得到得信息如下:
请求地址:https://wltx.cmcc-cs.cn:8981/net/api/net/busi/biddResult
设备信息:deviceinfos
认证信息:authorization
请求方式:POST
媒体类型:Content-Type: application/json;charset=utf-8
主机信息:host:
用户标识:User-Agent: okhttp/3.6.0
经验证,请求得头信息中,authorization、Content-Type、User-Agent是必填项。
请求的数据信息如下:
belgProvCode=-1&limit=10&start=0
belgProvCode:省份编码
limit:返回记录数
start:偏移量
开始构造spider
settings.py
BOT_NAME = 'wltx_app'SPIDER_MODULES = ['wltx_app.spiders']
NEWSPIDER_MODULE = 'wltx_app.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'okhttp/3.6.0'# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docsDOWNLOAD_DELAY = 0# The download delay setting will honor only one of:CONCURRENT_REQUESTS_PER_DOMAIN = 16CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED = False# Override the default request headers:DEFAULT_REQUEST_HEADERS = {'authorization': ''}
ITEM_PIPELINES = { 'wltx_app.pipelines.BidPipeline': 300,
}DEFAULT_REQUEST_HEADERS中authorization的值为抓取的值。
定义items
# -*- coding: utf-8 -*-# Define here the models for your scraped items## See documentation in:# https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass WltxAppItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() passclass BidItem(scrapy.Item): abst = scrapy.Field() bdgtAmt = scrapy.Field() belgCityCode = scrapy.Field() belgDistrtCode = scrapy.Field() biddAnoceNm = scrapy.Field() biddId = scrapy.Field() biddInfoIssueTime = scrapy.Field() biddNm = scrapy.Field() biddProdId = scrapy.Field() biddProdName = scrapy.Field() bidTypeId = scrapy.Field() busiOptnyLvlCd = scrapy.Field() cntt = scrapy.Field() cnttRich = scrapy.Field() concPrsnId = scrapy.Field() concTelnum = scrapy.Field() gatherTime = scrapy.Field() gathrSrc = scrapy.Field() gathrTime = scrapy.Field() indstBigClaCd = scrapy.Field() indstMidCd = scrapy.Field() indstSmallClaCd = scrapy.Field() infoTypeCd = scrapy.Field() issueTime = scrapy.Field() origTxtLinkAddr = scrapy.Field() projNm = scrapy.Field() projNo = scrapy.Field() syncTime = scrapy.Field() tagCode = scrapy.Field() tagName = scrapy.Field() tenderDueTime = scrapy.Field() tendererNm = scrapy.Field() tenderModeCd = scrapy.Field() tenderProjNm = scrapy.Field() userLikeTag = scrapy.Field() winBidAmt = scrapy.Field() winBidId = scrapy.Field() winBidNm = scrapy.Field()
编写spider
# -*- coding: utf-8 -*-import scrapyimport jsonfrom wltx_app.items import BidItemclass ZhongbiaoSpider(scrapy.Spider):
name = 'zhongbiao'
allowed_domains = ['wltx.cmcc-cs.cn'] # start_urls = ['https://wltx.cmcc-cs.cn:8981/net/api/net/busi/biddResult']
start = 0
def start_requests(self):
url = 'https://wltx.cmcc-cs.cn:8981/net/api/net/busi/biddResult'
headers = { 'Content-Type': 'application/json;charset=utf-8'
} for x in range(10000):
self.start = x
data = { 'belgProvCode': '-1', 'limit': '10', 'start': str(self.start)
} # yield scrapy.FormRequest(url, method = 'POST', headers = headers, body=json.dumps(data), callback = self.parse_list, dont_filter = True)
yield scrapy.FormRequest(url, method = 'POST', headers = headers, formdata=data, callback = self.parse_list, dont_filter = True) def parse_list(self, response):
res_data= json.loads(response.body.decode('utf-8'))
res_code = res_data['returnCode'] if res_code == 0: for item in res_data['bean']['biddResults']:
belgProvCode = item['belgProvCode']
biddId = item['biddId']
url = 'https://wltx.cmcc-cs.cn:8981/net/api/net/busi/resultDetail'
headers = { 'Content-Type': 'application/json;charset=utf-8'
}
data = { 'biddId':str(biddId), 'belgProvCode':str(belgProvCode), 'userId':'201804282156'
} yield scrapy.FormRequest(url, method = 'POST', headers = headers, formdata=data, callback = self.parse, dont_filter = True) def parse(self, response):
res_data= json.loads(response.body.decode('utf-8'))
res_code = res_data['returnCode'] if res_code == 0:
data = res_data['bean']
item = BidItem()
item = data yield item执行开始爬取执行命令如下:
scrapy crawl zhongbiao
总结的坑如下:
headers信息中的Content-Type在settings.py中设置是没有效果的。
重写start_requests()方法,中data列表的值必须是str、bytes,不能为int
post请求中formdata和body的效果是一样的
yield scrapy.FormRequest(url, method = 'POST', headers = headers, body=json.dumps(data), callback = self.parse_list, dont_filter = True)yield scrapy.FormRequest(url, method = 'POST', headers = headers, formdata=data, callback = self.parse_list, dont_filter = True)
重复爬取的地址需要设置 dont_filter = True
作者:mr_酱
链接:https://www.jianshu.com/p/028908a5be41





