
1.识别系统架构
harr_system.png
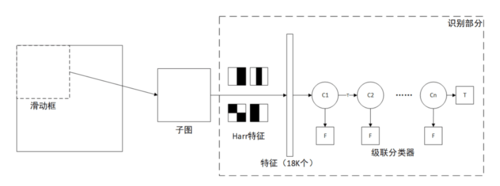
以上是Harr特征+级联分类器的识别系统架构图,系统分为以下几个部分:
滑动框:固定大小的在原图上滑动的框,用于获取子图
Harr特征提取器:在子图上提取指定的四种Harr特征(获取的特征非常多)
级联分类器:基于选定的一些特征,进行分类,筛选出正例
对于该目标识别器,将目标检测问题转换为目标分类问题:滑动框在原图上滑动,识别部分识别每一个滑动子图,判断是否为需要识别的目标。
1.1.Harr特征
Harr特征是一类非常简单的特征,如下图所示有四个框,这四个框的大小是可变的,使用黑色部分覆盖的像素之和减去白色部分覆盖的像素之和即为Harr特征:
Harr(x)=∑picblack(x)−∑picwhite(x)

harr.png
例如以下图片示意:

harr_example.png
取第一个4x4的区域数据计算第二种harr特征,被黑色覆盖的区域和为3,被白色区域覆盖的和为2,因此可获得基于第二种模板下滑动框的harr特征为3-2=1。对于基于某一个模板,一个候选框可取多个特征,例如对于24x24的滑动框,基于第一种模板(对角线模板),可以在2x2,3x3,...,24x24等多个尺寸取特征,对于2x2的特征而言,也可以在24x24的框内取23x23个特征,因此,每个滑动框的harr特征数量都是海量的,在原论文中,使用20x20的滑动框,每个滑动框有约18k个特征值。
1.2.级联分类器
由于Harr特征数量过多,已经几乎超过任何一种机器学习算法的输入特征数量极限(2001年),因此直接训练一个分类器是不现实的,于是使用多个弱分类器组成一个强分类器的方法训练。在本系统中,每一个弱分类器只针对一个单独的特征:
hj(x)={10fj(x)<θjother
该级联分类器使用AdaBoost方法训练,训练分类器的同时也筛选特征,最终分类器的级数与使用的特征数量相同(每个分类器只使用一个特征)。最终的分类器为:
h(x)=10∑\limitst=1Tatht(x)≥21t=1∑Tatother
T为级联分类器的数量,同时也是选择特征的数量,级联分类器不使用的特征在计算Harr特征时可以不计算以减少计算量;at为单个分类器的权重,在训练过程中得到。
2.训练方法
需要训练的部分为级联分类器,由于每个弱分类器仅使用一个特征,因此每个弱分类器的参数为阈值θj。训练算法如下图所示:

harr_train.PNG
首先,初始化样本权值w1,i={2m12l1yi=0yi=1,其中yi为当前样本的标签,1表示正例;m和l为反例和正例的数量。进入训练循环后,对于每次迭代:
首先标准化样本权值wt,i=\cfracwt,i∑j=1nwt,j
根据每个特征训练弱分类器h(x),训练过程中,代价函数与样本权值有关,代价函数为ϵj=∑iwi∣hj(xi)−yi∣。
所有特征对应的弱分类器训练完成后,选择代价函数最低的分类器和对应特征,同时该特征从待选则特征中移除。
最后更新样本权值:wt+1,i=wt,iβt1−ei,其中ei={10classifid correctlyotherwise ;βt=\cfracϵt1−ϵt
最终获得分类器h(x)和每个分类器的权值at=log\cfrac1βt。
3.加速方法
为了达到较快的检测速度,该系统分别对计算Harr特征和级联分类器提出了加速方案
3.1.积分图
积分图用于加速计算Harr特征,其方法是生成一个与原图片大小相同的图,使用以下公式:
ii(x)=x′≤x,y′≤y∑i(x′,y′)
如下图所示,积分图的数据为以图片对应位置和图片左上角连线为对角线的矩形覆盖的所有像素的和。在按行生成计算图的过程中,每个位置的值可以由计算图上方的数据和这一行之前的累加与该位置的值相加得到,因此计算图的生成比较简单。

harr_in.png
在计算harr特征时,需要计算大量的一定面积像素和,基于积分图,若要计算以下计算区域的和,仅需要计算:A−B−C+D即可,其中ABCD分别为积分图对应位置的值,因此任何一个矩形区域的求和都可以用3次加减法计算完成,有效的加速了Harr特征的提取速度。

harr_compute_im.png
3.2.级联计算
在基本级联分类器需要计算全部所需要的Harr特征,尽管已经使用学习算法筛选过,特征数量仍然较多,基于大部分子图中没有需要识别的物品,提出了级联的方法:
在训练筛选分类器时,不选择误差最小的分类器,而是选择最少的将正例划分为反例的分类器,即召回率最高的分类器。且下一次计算的样本集合为使用该分类器剔除反例的样本集合。
运行时,顺序计算特征-分类,当样本被一个分类器识别为反例时,直接拒绝该样本,后续的特征和分类都可以不被计算。
4.代码实践
4.1.使用自带级联分类器
OpenCV自带了一些级联分类器,可以用于识别人脸,五官和人体等等,在Python下使用方法如下:
face_cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt2.xml")
faces = face_cascade.detectMultiScale(
gray, scaleFactor=1.3, minNeighbors=2, minSize=(60, 60), maxSize=(300, 300))首先调用cv2.CascadeClassifier()打开一个级联分类器,这里载入的xml为OpenCV自带的人脸识别级联分类器,随后调用.detectMultiScale()方法进行识别,参数含义为:
第一个参数image:待识别图片,必须是灰度图片(channel=1)
scaleFactor:被检测对象的尺度变化,合理范围1.1~1.4,该参数越大检测越细致,速度越慢
minNeighbors:每个候选框需要保持多少个领域,该参数越大,一个候选框被接受越困难
minSize和maxSize:目标的最小尺寸和最大尺寸,当目标超过这一范围时无法识别
该函数返回一个list,其中每个元素为一个有4个元素的list,分别是[x,y,w,h],可直接用于绘制矩形框。
4.2.训练级联分类器
选择FDDB数据集训练针对人脸的级联分类器
4.2.1.处理标签
FDDB的标注方式是椭圆形标注,提供椭圆形的中心,长短轴和角度信息,原label为<major_axis_radius minor_axis_radius angle center_x center_y detection_score>,先要将label转为<left_x top_y width height>的格式。考虑简便,使用以下公式:
公式输入有误
该公式简单的将椭圆转为矩形,clamp为钳位函数,将输入限制在0~-1,-1表示不限制。同时限制矩形的范围一定在图片范围中。代码如下:
def FDDB2label(source_path, target_path): source_list = read_ellipseList(source_path) //读取原有label文件 target_list = change_label(source_list) //转换label格式 save_rec_label(target_list, target_path) //保存label格式
转换label的部分如下:
def change_label(source):
"""source:list[[path,label],...],label:[major_axis_radius minor_axis_radius angle center_x center_y detection_score]"""
result = [] for name, label in source:
name = name + ".jpg"
data = [float(x) for x in label.replace(" ", ' ').split(' ')]
data = [int(data[3] - data[1]), int(data[4] - data[0]),
int(data[1] * 2), int(data[0] * 2)]
data = check_label(name, data, root="../FDDB-folds/")
result.append(
[name, data]) return result检查部分如下:
def check_label(name, data, root=""): img_shape = cv2.imread(os.path.join(root, name)).shape if data[0] < 0: data[0] = 0 if data[1] < 0: data[1] = 0 if data[0] + data[2] > img_shape[1]: data[2] = img_shape[1] - data[0] - 1 if data[1] + data[3] > img_shape[0]: data[3] = img_shape[0] - data[1] - 1 return data
共检查两种情况:
物品左上角坐标小于0
物品右下角坐标超过图片限制
4.2.2.准备文件
训练前需要准备数据,包括正例和反例。
4.2.2.1.准备正例
正例使用opencv自带的opencv_createsamples.exe生成,注意该exe文件不可独立运行,因此不能拷贝出来使用,其依赖OpenCV的其他文件,因此必须从OpenCV中调用(opencv\build\x64\vc14\bin\opencv_createsamples.exe),该工具将正例转为.vec文件,主要有以下命令行参数:
-vec:输出vec文件的路径-info:正例描述文件路径-num:生成的正例数量-w和-h:正例图片的长宽
使用之前,需要准备一个描述正例文件的文件info.dat,其格式如下:
FDDB-folds\2002\08\11\big\img_591.jpg 1 184 38 171 247 FDDB-folds\2002\07\19\big\img_423.jpg 1 196 46 118 174 FDDB-folds\2002\08\24\big\img_490.jpg 1 110 23 70 109 <相对路径> <目标数量n> <目标1的x,y,w,h> ... <目标n的x,y,w,h>
随后使用该工具,生成正例文件pos.vec。
.\opencv\build\x64\vc14\bin\opencv_createsamples.exe -vec .\pos.vec -info info.dat -num 178 -w 40 -h 40
4.2.2.2.准备反例
对于反例,反例只需要准备一个文件列表neg_list.dat即可:
.\dataset\negtive\neg_img2698.jpg.\dataset\negtive\neg_img2699.jpg.\dataset\negtive\neg_img2700.jpg<相对路径>
4.2.3.模型训练
模型训练使用OpenCV的opencv_traincascade.exe,主要的参数如下:
-data:最终保存分类器文件的位置-vec:正例vec文件的路径-bg:反例文件列表的路径-numPos和-numNeg:正例和反例的数量-numStages:多层分类器的层数-w和-h:正例文件的长宽,必须和生成样本时填入的对应长宽相同
本次使用的命令行参数如下图所示:
.\opencv\build\x64\vc14\bin\opencv_traincascade.exe -data . -vec .\pos .vec -bg .\neg_list.dat -numPos 178 -numNeg 200 -numStages 10 -w 40 -h 40
最终训练的模型会保存在-data/cascade.xml中。
4.2.4.模型测试
可以使用官方提供的测试工具opencv_visualisation.exe测试,该工具会可视化测试过程并打印使用的分类器的类型,命令行参数如下:
--image:用于测试的图片路径--model:用于测试的模型(.xml文件)--data:保存测试结果的路径(可选)
官方给出的例子如下:
.\opencv\build\x64\vc14\bin\opencv_visualisation --image=\data\object.png --model=\ data\model.xml --data=\data\result\
参考文献
理论部分:Viola P, Jones M. Rapid object detection using a boosted cascade of simple features[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE Computer Society, 2001:511.
作者:月见樽
链接:https://www.jianshu.com/p/dddf13848148





