
什么是Q-learning
Q是Quality的首字母,表示"质量/优劣",表示给它打一个分。
在某些状态下做某个动作,会给他一个Q的价值。
learning就是学习的意思。基于质量,评判做出选择。
Q learning 是基于价值(Value-Based) 的学习
Q learning 是离线(off-play) 学习 基于过去的记忆学习。
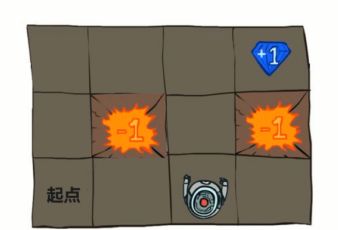
炸弹奖励是-1 宝石奖励为1。
Q learning 是基于价值的: State-Actio
对于state-action对做出一个打分。
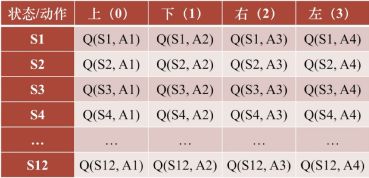
总共有12个状态,s1到s12.对于每一个状态会有四个动作。对于每个状态下的每个动作会有一个Q的值。
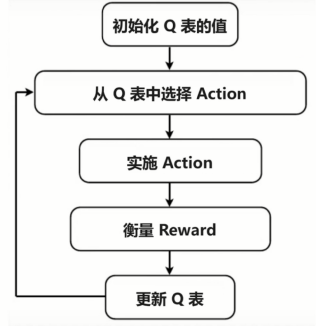
游戏中不断去跳转Q表中的值,学到最佳策略。
算法:


中文的算法解释。之后我们会基于这个中文算法描述来写我们的代码。
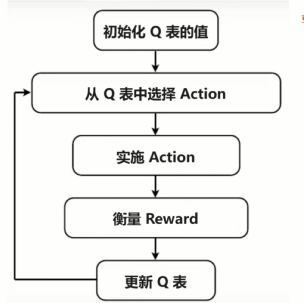
流程图:
基于表格的Q learning 局限性
对于状态(State) 非常多的(例如围棋) 无能无力
神经网络最会记住N多的参数,解决了Q Learing 的表格的局限。
结合深度学习(深度神经网络) 和 Q learning 推出了 DQL/DQN
深度Q learning 或者 深度的Q 网络
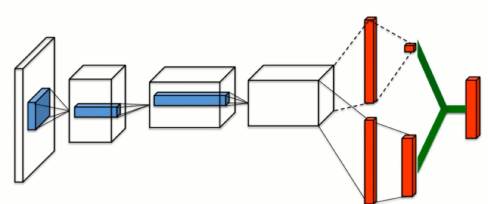
深度Q learning (DQL/DQN)
使用深度神经网络实现Q-learning的方法。克服了表格的局限。
Q-learning 实现机器人走迷宫
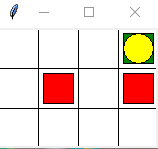
红色代表两个炸弹。蓝色宝藏。结束之后打印出Q表
实现步骤
游戏环境 机器人大脑 游戏主程序
实现游戏的环境
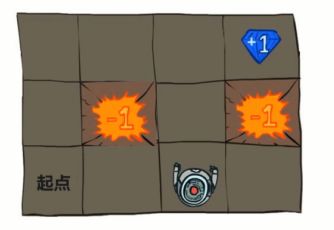
迷宫的地图是这样的,左下角有个起点。-1 是炸弹 +1 是宝藏。
用Tkinter 来模拟gym的环境构建。我们用到的方法名和用法都和gym是类似的。
完成的迷宫地图如下
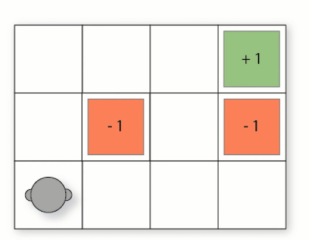
编写我们的env.py
1# -*- coding: UTF-8 -*-
2"""
3Q Learning 例子的 Maze(迷宫) 环境
4黄色圆形 : 机器人
5红色方形 : 炸弹 [reward = -1]
6绿色方形 : 宝藏 [reward = +1]
7其他方格 : 平地 [reward = 0]
8"""
9import sys
10import time
11import numpy as np
12# Python2 和 Python3 中 Tkinter 的名称不一样
13if sys.version_info.major == 2:
14import Tkinter as tk
15else:
16import tkinter as tk
python2与python3下的Tkinter的不同引入处理。
1WIDTH = 4 # 迷宫的宽度
2HEIGHT = 3 # 迷宫的高度
3UNIT = 40 # 每个方块的大小(像素值)
构建一个class继承TK
1# 迷宫 类
2class Maze(tk.Tk, object):
3def __init__(self):
4super(Maze, self).__init__()
5self.action_space = ['u', 'd', 'l', 'r'] # 上,下,左,右 四个 action(动作)
6self.n_actions = len(self.action_space) # action 的数目
7self.title('Q Learning')
8self.geometry('{0}x{1}'.format(WIDTH * UNIT, HEIGHT * UNIT)) # Tkinter 的几何形状
9self.build_maze()
定义一个init的构造方法。调用父类的初始化方法。
定义它的动作空间: action_space 上下左右四个。 up down action的数目。 title: 生成的游戏窗口的title geometry 几何形状。第一维是一宽度乘以每个单元的像素值,第二维是高乘以每个单元像素值。
调用 build Maze方法
1创建迷宫
2def build_maze(self):
3# 创建画布 Canvas.白色背景,宽高。
4self.canvas = tk.Canvas(self, bg='white',
5 width=WIDTH * UNIT,
6 height=HEIGHT * UNIT)
7
8# 绘制横纵方格线。创建线条。
9for c in range(0, WIDTH * UNIT, UNIT):
10 x0, y0, x1, y1 = c, 0, c, HEIGHT * UNIT
11 self.canvas.create_line(x0, y0, x1, y1)
12for r in range(0, HEIGHT * UNIT, UNIT):
13 x0, y0, x1, y1 = 0, r, WIDTH * UNIT, r
14 self.canvas.create_line(x0, y0, x1, y1)
15
16# 零点(左上角) 往右是x增长的方向。往左是y增长的方向。
17# 因为每个方格是40像素,20,20是中心位置。
18origin = np.array([20, 20])
19
20# 创建我们的探索者 机器人(robot)
21robot_center = origin + np.array([0, UNIT * 2])
22# 创建椭圆,指定起始位置。填充颜色
23self.robot = self.canvas.create_oval(
24 robot_center[0] - 15, robot_center[1] - 15,
25 robot_center[0] + 15, robot_center[1] + 15,
26 fill='yellow')
27
28# 炸弹 1
29bomb1_center = origin + UNIT
30self.bomb1 = self.canvas.create_rectangle(
31 bomb1_center[0] - 15, bomb1_center[1] - 15,
32 bomb1_center[0] + 15, bomb1_center[1] + 15,
33 fill='red')
34
35# 炸弹 2
36bomb2_center = origin + np.array([UNIT * 3, UNIT])
37self.bomb2 = self.canvas.create_rectangle(
38 bomb2_center[0] - 15, bomb2_center[1] - 15,
39 bomb2_center[0] + 15, bomb2_center[1] + 15,
40 fill='red')
41
42# 宝藏
43treasure_center = origin + np.array([UNIT * 3, 0])
44self.treasure = self.canvas.create_rectangle(
45 treasure_center[0] - 15, treasure_center[1] - 15,
46 treasure_center[0] + 15, treasure_center[1] + 15,
47 fill='green')
48
49# 设置好上面配置的场景
50self.canvas.pack()
reset方法表示游戏重新开始,机器人回到左下角
1# 重置(游戏重新开始,将机器人放到左下角)
2def reset(self):
3self.update()
4time.sleep(0.5)
5self.canvas.delete(self.robot) # 删去机器人
6origin = np.array([20, 20])
7robot_center = origin + np.array([0, UNIT * 2])
8# 重新创建机器人
9self.robot = self.canvas.create_oval(
10 robot_center[0] - 15, robot_center[1] - 15,
11 robot_center[0] + 15, robot_center[1] + 15,
12 fill='yellow')
13# 返回 观测(observation)
14return self.canvas.coords(self.robot)
使用update方法更新一下游戏环境。使用coords返回一个观测值。
走一步(机器人实施一个action)
1# 走一步(机器人实施 action)
2def step(self, action):
3# s表示一个state状态值
4s = self.canvas.coords(self.robot)
5# 基准动作
6base_action = np.array([0, 0])
7if action == 0: # 上
8 if s[1] > UNIT:
9 base_action[1] -= UNIT
10elif action == 1: # 下
11 if s[1] < (HEIGHT - 1) * UNIT:
12 base_action[1] += UNIT
13elif action == 2: # 右
14 if s[0] < (WIDTH - 1) * UNIT:
15 base_action[0] += UNIT
16elif action == 3: # 左
17 if s[0] > UNIT:
18 base_action[0] -= UNIT
19
20# 移动机器人,移动到baseation横向纵向坐标值
21self.canvas.move(self.robot, base_action[0], base_action[1])
22
23# 取得下一个 state
24s_ = self.canvas.coords(self.robot)
25
26# 奖励机制。
27if s_ == self.canvas.coords(self.treasure):
28 reward = 1 # 找到宝藏,奖励为 1
29 done = True
30 s_ = 'terminal' # 终止
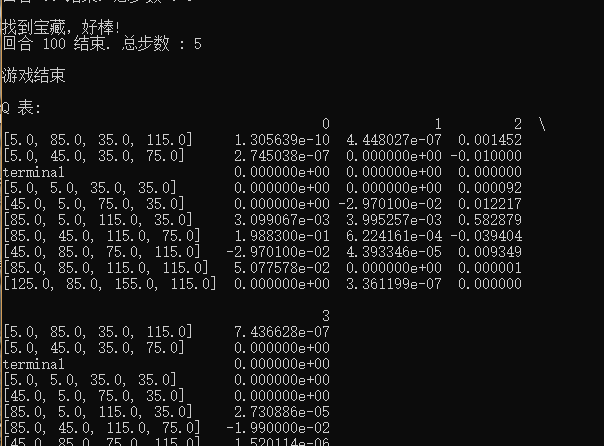
31 print("找到宝藏,好棒!")
32elif s_ == self.canvas.coords(self.bomb1):
33 reward = -1 # 踩到炸弹1,奖励为 -1
34 done = True
35 s_ = 'terminal' # 终止
36 print("炸弹 1 爆炸...")
37elif s_ == self.canvas.coords(self.bomb2):
38 reward = -1 # 踩到炸弹2,奖励为 -1
39 done = True
40 s_ = 'terminal' # 终止
41 print("炸弹 2 爆炸...")
42else:
43 reward = 0 # 其他格子,没有奖励
44 done = False
45
46return s_, reward, done
47# 调用 Tkinter 的 update 方法
48def render(self):
49time.sleep(0.1)
50self.update()
调用Tkinter的update方法。0.1秒去走一步。
实现Q learning(机器人的大脑)
Q learning的 Q表
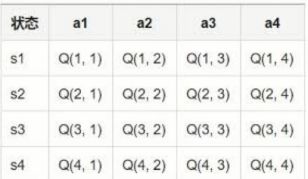
每一行是一个状态,s1 到 s4
每一列是在这个状态下可以采取的行动。
Q learning的算法

我们例子的Q表: 有12个格子,4个动作
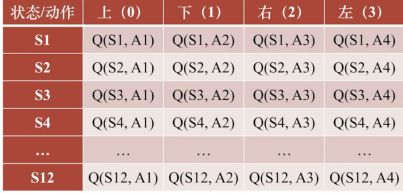
对应的Q值。
中文的Q learning算法伪代码

首先会随机的初始化Q表中的值。对于每一个回合做一个循环。
循环中首先:
初始化初始位置的状态。

新的Q表中的Q(s,a)更新规则如上。
著名的贝尔曼方程
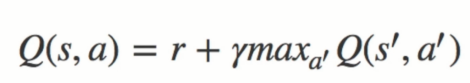
e-Greedy 贪婪算法: 持续探索(Exploration)
贪婪度 e: e-Greedy 算法可以预防更好的选择一直没有被探索到。
1-e 的概率 选择Q表中state位置值最大的action
e的概率 随机选取Q表中state位置的action
https://www.zhihu.com/question/26408259?sort=created
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
代码编写
1# -*- coding: UTF-8 -*-
2"""
3Q Learning 算法。做决策的部分,相当于机器人的大脑
4"""
5import numpy as np
6import pandas as pd
7class QLearning:
8def __init__(self, actions, learning_rate=0.01, discount_factor=0.9, e_greedy=0.1):
9self.actions = actions # action 列表
10self.lr = learning_rate # 学习速率
11self.gamma = discount_factor # 折扣因子
12self.epsilon = e_greedy # 贪婪度
13# 列是action,上下左右四种。
14self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float32) # Q 表
15# 检测 q_table 中有没有这个 state
16# 如果还没有当前 state, 那我们就插入一组全 0 数据, 作为这个 state 的所有 action 的初始值
17def check_state_exist(self, state):
18# state对应每一行,如果不在Q表中。
19if state not in self.q_table.index:
20 # 插入一组全 0 数据,上下左右,四个动作,创建四个零
21 self.q_table = self.q_table.append(
22 pd.Series(
23 [0] * len(self.actions),
24 index=self.q_table.columns,
25 name=state,
26 )
27 )
28
29# 根据 state 来选择 action
30def choose_action(self, state):
31self.check_state_exist(state) # 检测此 state 是否在 q_table 中存在
32# 选行为,用 Epsilon Greedy 贪婪方法
33if np.random.uniform() < self.epsilon:
34 # 随机选择 action
35 action = np.random.choice(self.actions)
36else: # 选择 Q 值最高的 action
37 state_action = self.q_table.loc[state, :]
38 # 同一个 state, 可能会有多个相同的 Q action 值, 所以我们乱序一下
39 state_action = state_action.reindex(np.random.permutation(state_action.index))
40 # 每一行中取到Q值最大的那个
41 action = state_action.idxmax()
42return action
43
44# 学习。更新 Q 表中的值
45def learn(self, s, a, r, s_):
46# s_是下一个状态
47self.check_state_exist(s_) # 检测 q_table 中是否存在 s_
48
49q_predict = self.q_table.loc[s, a] # 根据 Q 表得到的 估计(predict)值
50
51# q_target 是现实值
52if s_ != 'terminal': # 下个 state 不是 终止符
53 q_target = r + self.gamma * self.q_table.loc[s_, :].max()
54else:
55 q_target = r # 下个 state 是 终止符
56
57# 更新 Q 表中 state-action 的值
58self.q_table.loc[s, a] += self.lr * (q_target - q_predict)
编写游戏主程序、
1 play.py
2 # -*- coding: UTF-8 -*-
3 """
4 游戏的主程序,调用机器人的 Q learning 决策大脑 和 Maze 环境
5 """
6 from env import Maze
7 from q_learning import QLearning
8 def update():
9 for episode in range(100):
10# 初始化 state(状态)
11state = env.reset()
12
13step_count = 0 # 记录走过的步数
14
15while True:
16 # 更新可视化环境
17 env.render()
18
19 # RL 大脑根据 state 挑选 action
20 action = RL.choose_action(str(state))
21
22 # 探索者在环境中实施这个 action, 并得到环境返回的下一个 state, reward 和 done (是否是踩到炸弹或者找到宝藏)
23 state_, reward, done = env.step(action)
24
25 step_count += 1 # 增加步数
26
27 # 机器人大脑从这个过渡(transition) (state, action, reward, state_) 中学习
28 RL.learn(str(state), action, reward, str(state_))
29
30 # 机器人移动到下一个 state
31 state = state_
32
33 # 如果踩到炸弹或者找到宝藏, 这回合就结束了
34 if done:
35 print("回合 {} 结束. 总步数 : {}\n".format(episode+1, step_count))
36 break
37 # 结束游戏并关闭窗口
38 print('游戏结束')
39 env.destroy()
40 if __name__ == "__main__":
41 # 创建环境 env 和 RL
42 env = Maze()
43 RL = QLearning(actions=list(range(env.n_actions)))
44 # 开始可视化环境
45 env.after(100, update)
46 env.mainloop()
47 print('\nQ 表:')
48 print(RL.q_table)
DeepQlearning实现:迷宫游戏
我们通过之前的Qlearning 知道了算法和代码
Qlearning 局限: 不能表示很多的状态和Q值。下围棋这个例子

可以表示很多参数
最终效果:
实现步骤:
机器人大脑
游戏环境
游戏主程序。
DeepQlearing 有Q-learning的优势
Q-learning 是 off-Policy (离线学习 可以学习过往经验或记忆)
Q-learning 可以单步更新,比回合更新更有效率

经验回放(去学习过往的经验或记忆)
单步更新,更新网络参数
记忆库存储过往记忆。
估计神经网络 现实实际 神经网络
1# -*- coding: UTF-8 -*-
2"""
3Deep Q Learning 算法。做决策的部分,相当于机器人的大脑
4"""
5import numpy as np
6import tensorflow as tf
7# 伪随机数。为了复现结果
8np.random.seed(1)
9tf.set_random_seed(1)
10class DeepQLearning:
11def __init__(
12 self,
13 n_actions,
14 n_features,
15 learning_rate=0.01,
16 discount_factor=0.9,
17 e_greedy=0.1,
18 replace_target_iter=300,
19 memory_size=500,
20 batch_size=32,
21 output_graph=False, # 是否存储 TensorBoard 日志
22 ):
23self.n_actions = n_actions # action 的数目
24self.n_features = n_features # state/observation 里的特征数目
25self.lr = learning_rate # 学习速率
26self.gamma = discount_factor # 折扣因子
27self.epsilon = e_greedy # 贪婪度 Epsilon Greedy
28self.replace_target_iter = replace_target_iter # 每多少个迭代替换一下 target 网络的参数
29self.memory_size = memory_size # 记忆上限
30self.batch_size = batch_size # 随机选取记忆片段的大小
31
32# 学习次数 (用于判断是否更换 Q_target_net 参数)
33self.learning_steps = 0
34
35# 初始化全 0 记忆 [s, a, r, s_]
36self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
37
38# 构建神经网络
39self.construct_network()
40
41# 提取 Q_target_net 和 Q_eval_net 的参数
42t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Q_target_net')
43e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Q_eval_net')
44
45# 用 Q_eval_net 参数来替换 Q_target_net 参数
46with tf.variable_scope('target_replacement'):
47 self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
48
49self.sess = tf.Session()
50
51if output_graph:
52 # 输出 TensorBoard 日志文件
53 tf.summary.FileWriter("logs", self.sess.graph)
54
55# 初始化全局变量
56self.sess.run(tf.global_variables_initializer())
57'''
58构建两个神经网络(Q_eval_net 和 Q_target_net)。
59固定住一个神经网络 (Q_target_net) 的参数(所谓 Fixed Q target)。
60Q_target_net 相当于 Q_eval_net 的一个历史版本, 拥有 Q_eval_net 之前的一组参数。
61这组参数被固定一段时间, 然后再被 Q_eval_net 的新参数所替换。
62Q_eval_net 的参数是不断在被提升的
63'''
64def construct_network(self):
65# 输入数据 [s, a, r, s_]
66with tf.variable_scope('input'):
67 self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # State
68 self.a = tf.placeholder(tf.int32, [None, ], name='a') # Action
69 self.r = tf.placeholder(tf.float32, [None, ], name='r') # Reward
70 self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # 下一个 State
71
72# 权重和偏差
73w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
74
75# 创建 Q_eval 神经网络, 适时更新参数
76with tf.variable_scope('Q_eval_net'):
77 e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
78 bias_initializer=b_initializer, name='e1')
79 self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
80 bias_initializer=b_initializer, name='e2')
81
82# 创建 Q_target 神经网络, 提供 target Q
83with tf.variable_scope('Q_target_net'):
84 t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
85 bias_initializer=b_initializer, name='t1')
86 self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
87 bias_initializer=b_initializer, name='t2')
88
89# 在 Q_target_net 中,计算下一个状态 s_j_next 的真实 Q 值
90with tf.variable_scope('Q_target'):
91 q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1)
92 # tf.stop_gradient 使 q_target 不参与梯度计算的操作
93 self.q_target = tf.stop_gradient(q_target)
94
95# 在 Q_eval_net 中,计算状态 s_j 的估计 Q 值
96with tf.variable_scope('Q_eval'):
97 a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
98 # tf.gather_nd 用 indices 定义的形状来对 params 进行切片
99 self.q_eval_by_a = tf.gather_nd(params=self.q_eval, indices=a_indices)
100
101# 计算真实值和估计值的误差(loss)
102with tf.variable_scope('loss'):
103 self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_by_a, name='error'))
104
105# 梯度下降法优化参数
106with tf.variable_scope('train'):
107 self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
108
109# 在记忆中存储和更新 transition(转换)样本 [s, a, r, s_]
110def store_transition(self, s, a, r, s_):
111if not hasattr(self, 'memory_count'):
112 self.memory_count = 0
113transition = np.hstack((s, [a, r], s_))
114# 记忆总大小是固定的。如果超出总大小, 旧记忆就被新记忆替换
115index = self.memory_count % self.memory_size
116self.memory[index, :] = transition
117self.memory_count += 1
118
119# 根据 state 来选 action
120def choose_action(self, state):
121# 统一 state 的形状
122state = state[np.newaxis, :]
123
124if np.random.uniform() < self.epsilon:
125 # 随机选择
126 action = np.random.randint(0, self.n_actions)
127else:
128 # 让 Q_eval_net 神经网络生成所有 action 的值, 并选择值最大的 action
129 actions_value = self.sess.run(self.q_eval, feed_dict={self.s: state})
130 action = np.argmax(actions_value)
131
132 return action
133
134 # 学习
135 def learn(self):
136# 是否替换 Q_target_net 参数
137if self.learning_steps % self.replace_target_iter == 0:
138 self.sess.run(self.target_replace_op)
139 print('\n替换现实网络的参数...\n')
140
141# 从记忆中随机抽取 batch_size 长度的记忆片段
142if self.memory_count > self.memory_size:
143 sample_index = np.random.choice(self.memory_size, size=self.batch_size)
144else:
145 sample_index = np.random.choice(self.memory_count, size=self.batch_size)
146batch_memory = self.memory[sample_index, :]
147
148# 训练 Q_eval_net
149_, _ = self.sess.run(
150 [self.train_op, self.loss],
151 feed_dict={
152 self.s: batch_memory[:, :self.n_features],
153 self.a: batch_memory[:, self.n_features],
154 self.r: batch_memory[:, self.n_features + 1],
155 self.s_: batch_memory[:, -self.n_features:],
156 })
157
158self.learning_steps += 1
Policy Gradient 实现 Gym游戏
实现步骤: 机器人大脑 & 游戏主程序
什么是Policy Gradient
Policy-Based 方法: 与Value-Based(如Q-learning DQN)不同
策略上做一个梯度下降
Policy Gradient 跳过 Value 阶段,根据概率来输出具体的Action
输出的Action可以是一个连续的值,Value-Based输出是不连续的。
原文链接:https://www.jianshu.com/p/e37f5d98c886







