
作者 | Moses Olafenwa
翻译 | 林椿眄
出品 | 人工智能头条(公众号ID:AI_Thinker)
作为人工智能的一个重要领域,计算机视觉是一门可以识别并理解图像和场景的计算机及软件系统科学。该领域主要包括图像识别,目标检测,图像生成,图像超分辨率等多个方向。由于现实中存在众多的实际案例,目标检测应该是计算机视觉中最令人深刻的一个方向。在本教程中,我们将简要介绍包括当前目标检测的概念,软件开发人员所面临的挑战,相应的解决方案以及执行高性能目标检测的编码教程等内容。
目标检测是指计算机和软件系统在图像/场景中定位并识别出每个目标的能力,已广泛应用于人脸检测,车辆检测,行人计数,网络图像,安全系统和无人驾驶汽车等领域。当前有很多目标检测方法能够在实践中应用。像其他任何计算机技术一样,各种创造性和效果惊人的目标检测方法都是来自计算机程序员和软件开发人员的努力。
在应用程序和系统中使用目标检测方法,并基于这些方法构建新的应用并不是一项直接的任务。在早期,目标检测的实现包括一些经典算法的使用,如在受欢迎的计算机视觉库 OpenCV 中支持的算法。然而,这些经典算法无法在不同条件下达到同等优秀的工作性能。
2012 年之后,深度学习技术的突破性及其快速应用,带来了诸如 R-CNN,Fast-RCNN,Faster-RCNN,RetinaNet 等诸多高精度目标检测方法,以及以 SSD 和 YOLO 为代表的等快而准的目标检测算法。想要使用这些基于深度学习的目标检测方法,我们需要对数学知识及深度学习框架的深刻理解。数百万的专业计算机程序员和软件开发人员想要集成和创建用于目标检测的新产品。但是,理解并在实际中使用目标检测产品需要额外且复杂的方法,这种技术超出了一般程序员的能力范围。
在几个月前,我的团队就意识到了这个问题,这就是为什么我和 John Olafenwa构建 ImageAI 的原因。这是一个基于 Python 程序库,它允许程序员和软件开发人员轻松地将最先进的计算机视觉技术集成到他们现有的或新的应用程序中。
想要使用 ImageAI 实现目标检测任务,你需要做的就是:
1. 在计算机系统上安装 Python
2. 安装 ImageAI 及其依赖库
3. 下目标象检测的模型文件
4. 运行示例代码 (只有10行)
现在让我们开始吧~
1) 从 Python 官网上下载并安装 Python 3:
https://python.org
2) 通过 pip 安装以下依赖库:
Ⅰ. Tensorflow:pip install tensorflow
II. NumPy:pip install numpy
III. SciPy:pip install scipy
IV. OpenCV:pip install opencv-python
Ⅴ. Pillow:pip install pillow
Ⅵ. Matplotlib: pip install matplotlib
Ⅶ. H5py:pip install h5py
Ⅷ. Keras:pip install keras
Ⅸ. ImageAI:pip install
https://github.com/OlafenwaMoses/ImageAI/releases
/download/2.0.1/imageai-2.0.1-py3-none-any.whl
3) 通过此链接下载用于目标检测的 RetinaNet 模型文件。
https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5
现在,你已经安装了需要的依赖库。接下来,你就可以编写第一段目标检测代码了。创建一个 Python 文件并为其命名 (例如,FirstDetection.py),然后写入下面的 10 行代码,并将 RetinaNet 模型文件和需要检测的图像复制到包含这个 python 文件的文件夹中。
FirstDetection.py
from imageai.Detection import ObjectDetectionimport osexecution_path = os.getcwd()detector = ObjectDetection()detector.setModelTypeAsRetinaNet()detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))detector.loadModel()detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
然后运行代码,稍等片刻结果将显示在控制台中。一旦控制台打印出结果后,转到 FirstDetection.py 所在的文件夹,你将找到所保存的新图像。如下是两个原图像样本,检测后将保存新图像。
Before Detection:

Image Credit: alzheimers.co.uk

Image Credit: Wikicommons
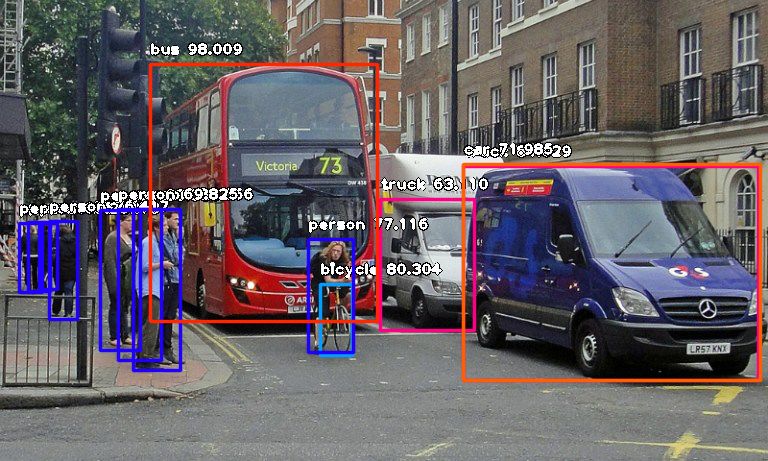
After Detection:
控制台打印的检测结果:
person : 55.8402955532074
person : 53.21805477142334
person : 69.25139427185059
person : 76.41745209693909
bicycle : 80.30363917350769
person : 83.58567953109741
person : 89.06581997871399
truck : 63.10953497886658
person : 69.82483863830566
person : 77.11606621742249
bus : 98.00949096679688
truck : 84.02870297431946
car : 71.98476791381836

控制台打印的检测结果:
person : 71.10445499420166
person : 59.28672552108765
person : 59.61582064628601
person : 75.86382627487183
motorcycle : 60.1050078868866
bus : 99.39600229263306
car : 74.05484318733215
person : 67.31776595115662
person : 63.53200078010559
person : 78.2265305519104
person : 62.880998849868774
person : 72.93365597724915
person : 60.01397967338562
person : 81.05944991111755
motorcycle : 50.591760873794556
motorcycle : 58.719027042388916
person : 71.69321775436401
bicycle : 91.86570048332214
motorcycle : 85.38855314254761
现在,我们来解释下这 10 行代码是如何工作的。
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
在上面 3 行代码种,第一行我们导入了 ImageAI 目标检测类,第二行导入了 python 的 os 类,第三行定义了一个变量用来保存我们的 python 文件,其中 RetinaNet 模型文件和图像都将存放在该文件夹路径下。
detector = ObjectDetection()detector.setModelTypeAsRetinaNet()detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))detector.loadModel()detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
在上面的 5 行代码中,第一行定义了目标检测类,第二行将模型的类型设置为 RetinaNet,并在第三行将模型路径设置为 RetinaNet 模型的路径,第四行将模型加载到的目标检测类,第五行调用目标检测函数,解析输入的和输出的图像路径。
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
在上面的2行代码中,第一行迭代执行 detector.detectObjectsFromImage 函数并返回所有的结果,然后在第二行打印出所检测到的每个目标的名称及其概率值。
ImageAI 支持许多强大的目标检测过程。其中之一就是能够提取图像中检测到的每个目标。如下所示,通过简单地解析将 extra_detected_objects = True 变为 detectObjectsFromImage 函数,目标检测类将为图像目标创建一个新的文件夹,提取每张图像,并将每张图像保存到新创建的文件夹中,同时返回一个包含每张图像路径的额外数组。
detections, extracted_images = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"), extract_detected_objects=True)
下面我们来看看在第一张图像上取得的目标检测结果:

所有包含行人的图像都能被提取出来了,我没有保存所有的目标,因为它们会占用太多不必要的空间。
ImageAI 还提供了更多功能,可用于定制和生产功能部署所需的目标检测任务。一些支持的功能如下:
Adjusting Minimum Probability:默认情况下,检测概率低于 50% 的对象将不会显示或报告。你可以增加高确定性目标的检测概率,或者在需要检测所有可能对象的情况下降低该概率值。
Custom Objects Detection:使用所提供的 CustomObject 类,如此检测类函数将打印出一个或几个唯一目标的检测结果。
Detection Speed:通过将检测速度设置为“fast”、“faster”和“fastest”,以便缩短目标检测所需的时间。
Input Types:你可以指定并解析图像的文件路径,Numpy 数组或图像文件流作为输入图像
Output Types:你可以指定 detectObjectsFromImage 函数所返回的图像格式,可以是以文件或 Numpy 数组的形式。
最后,送上 GitHub 地址:
https://github.com/OlafenwaMoses/ImageAI





